 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiHDR: Iterative HDR Imaging with Arbitrary Number of Exposures
May 29, 2025High dynamic range (HDR) imaging aims to obtain a high-quality HDR image by fusing information from multiple low dynamic range (LDR) images. Numerous learning-based HDR imaging methods have been proposed to achieve this for static and dynamic scenes. However, their architectures are mostly tailored for a fixed number (e.g., three) of inputs and, therefore, cannot apply directly to situations beyond the pre-defined limited scope. To address this issue, we propose a novel framework, iHDR, for iterative fusion, which comprises a ghost-free Dual-input HDR fusion network (DiHDR) and a physics-based domain mapping network (ToneNet). DiHDR leverages a pair of inputs to estimate an intermediate HDR image, while ToneNet maps it back to the nonlinear domain and serves as the reference input for the next pairwise fusion. This process is iteratively executed until all input frames are utilized. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method as compared to existing state-of-the-art HDR deghosting approaches given flexible numbers of input frames.
Quanta Video Restoration
Oct 19, 2024The proliferation of single-photon image sensors has opened the door to a plethora of high-speed and low-light imaging applications. However, data collected by these sensors are often 1-bit or few-bit, and corrupted by noise and strong motion. Conventional video restoration methods are not designed to handle this situation, while specialized quanta burst algorithms have limited performance when the number of input frames is low. In this paper, we introduce Quanta Video Restoration (QUIVER), an end-to-end trainable network built on the core ideas of classical quanta restoration methods, i.e., pre-filtering, flow estimation, fusion, and refinement. We also collect and publish I2-2000FPS, a high-speed video dataset with the highest temporal resolution of 2000 frames-per-second, for training and testing. On simulated and real data, QUIVER outperforms existing quanta restoration methods by a significant margin. Code and dataset available at https://github.com/chennuriprateek/Quanta_Video_Restoration-QUIVER-
Generative Quanta Color Imaging
Mar 28, 2024



The astonishing development of single-photon cameras has created an unprecedented opportunity for scientific and industrial imaging. However, the high data throughput generated by these 1-bit sensors creates a significant bottleneck for low-power applications. In this paper, we explore the possibility of generating a color image from a single binary frame of a single-photon camera. We evidently find this problem being particularly difficult to standard colorization approaches due to the substantial degree of exposure variation. The core innovation of our paper is an exposure synthesis model framed under a neural ordinary differential equation (Neural ODE) that allows us to generate a continuum of exposures from a single observation. This innovation ensures consistent exposure in binary images that colorizers take on, resulting in notably enhanced colorization. We demonstrate applications of the method in single-image and burst colorization and show superior generative performance over baselines. Project website can be found at https://vishal-s-p.github.io/projects/2023/generative_quanta_color.html.
Spatio-Temporal Turbulence Mitigation: A Translational Perspective
Jan 08, 2024Recovering images distorted by atmospheric turbulence is a challenging inverse problem due to the stochastic nature of turbulence. Although numerous turbulence mitigation (TM) algorithms have been proposed, their efficiency and generalization to real-world dynamic scenarios remain severely limited. Building upon the intuitions of classical TM algorithms, we present the Deep Atmospheric TUrbulence Mitigation network (DATUM). DATUM aims to overcome major challenges when transitioning from classical to deep learning approaches. By carefully integrating the merits of classical multi-frame TM methods into a deep network structure, we demonstrate that DATUM can efficiently perform long-range temporal aggregation using a recurrent fashion, while deformable attention and temporal-channel attention seamlessly facilitate pixel registration and lucky imaging. With additional supervision, tilt and blur degradation can be jointly mitigated. These inductive biases empower DATUM to significantly outperform existing methods while delivering a tenfold increase in processing speed. A large-scale training dataset, ATSyn, is presented as a co-invention to enable generalization in real turbulence. Our code and datasets will be available at \href{https://xg416.github.io/DATUM}{\textcolor{pink}{https://xg416.github.io/DATUM}}
Kernel Diffusion: An Alternate Approach to Blind Deconvolution
Dec 04, 2023Blind deconvolution problems are severely ill-posed because neither the underlying signal nor the forward operator are not known exactly. Conventionally, these problems are solved by alternating between estimation of the image and kernel while keeping the other fixed. In this paper, we show that this framework is flawed because of its tendency to get trapped in local minima and, instead, suggest the use of a kernel estimation strategy with a non-blind solver. This framework is employed by a diffusion method which is trained to sample the blur kernel from the conditional distribution with guidance from a pre-trained non-blind solver. The proposed diffusion method leads to state-of-the-art results on both synthetic and real blur datasets.
Spatially Varying Exposure with 2-by-2 Multiplexing: Optimality and Universality
Jun 30, 2023The advancement of new digital image sensors has enabled the design of exposure multiplexing schemes where a single image capture can have multiple exposures and conversion gains in an interlaced format, similar to that of a Bayer color filter array. In this paper, we ask the question of how to design such multiplexing schemes for adaptive high-dynamic range (HDR) imaging where the multiplexing scheme can be updated according to the scenes. We present two new findings. (i) We address the problem of design optimality. We show that given a multiplex pattern, the conventional optimality criteria based on the input/output-referred signal-to-noise ratio (SNR) of the independently measured pixels can lead to flawed decisions because it cannot encapsulate the location of the saturated pixels. We overcome the issue by proposing a new concept known as the spatially varying exposure risk (SVE-Risk) which is a pseudo-idealistic quantification of the amount of recoverable pixels. We present an efficient enumeration algorithm to select the optimal multiplex patterns. (ii) We report a design universality observation that the design of the multiplex pattern can be decoupled from the image reconstruction algorithm. This is a significant departure from the recent literature that the multiplex pattern should be jointly optimized with the reconstruction algorithm. Our finding suggests that in the context of exposure multiplexing, an end-to-end training may not be necessary.
HDR Imaging with Spatially Varying Signal-to-Noise Ratios
Apr 16, 2023



While today's high dynamic range (HDR) image fusion algorithms are capable of blending multiple exposures, the acquisition is often controlled so that the dynamic range within one exposure is narrow. For HDR imaging in photon-limited situations, the dynamic range can be enormous and the noise within one exposure is spatially varying. Existing image denoising algorithms and HDR fusion algorithms both fail to handle this situation, leading to severe limitations in low-light HDR imaging. This paper presents two contributions. Firstly, we identify the source of the problem. We find that the issue is associated with the co-existence of (1) spatially varying signal-to-noise ratio, especially the excessive noise due to very dark regions, and (2) a wide luminance range within each exposure. We show that while the issue can be handled by a bank of denoisers, the complexity is high. Secondly, we propose a new method called the spatially varying high dynamic range (SV-HDR) fusion network to simultaneously denoise and fuse images. We introduce a new exposure-shared block within our custom-designed multi-scale transformer framework. In a variety of testing conditions, the performance of the proposed SV-HDR is better than the existing methods.
Scattering and Gathering for Spatially Varying Blurs
Mar 10, 2023A spatially varying blur kernel $h(\mathbf{x},\mathbf{u})$ is specified by an input coordinate $\mathbf{u} \in \mathbb{R}^2$ and an output coordinate $\mathbf{x} \in \mathbb{R}^2$. For computational efficiency, we sometimes write $h(\mathbf{x},\mathbf{u})$ as a linear combination of spatially invariant basis functions. The associated pixelwise coefficients, however, can be indexed by either the input coordinate or the output coordinate. While appearing subtle, the two indexing schemes will lead to two different forms of convolutions known as scattering and gathering, respectively. We discuss the origin of the operations. We discuss conditions under which the two operations are identical. We show that scattering is more suitable for simulating how light propagates and gathering is more suitable for image filtering such as denoising.
Dynamic Low-light Imaging with Quanta Image Sensors
Jul 16, 2020
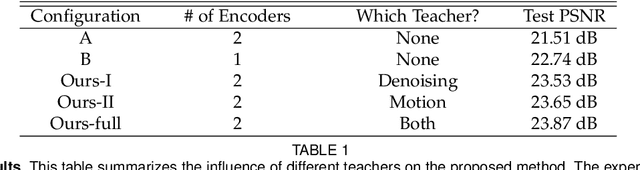


Imaging in low light is difficult because the number of photons arriving at the sensor is low. Imaging dynamic scenes in low-light environments is even more difficult because as the scene moves, pixels in adjacent frames need to be aligned before they can be denoised. Conventional CMOS image sensors (CIS) are at a particular disadvantage in dynamic low-light settings because the exposure cannot be too short lest the read noise overwhelms the signal. We propose a solution using Quanta Image Sensors (QIS) and present a new image reconstruction algorithm. QIS are single-photon image sensors with photon counting capabilities. Studies over the past decade have confirmed the effectiveness of QIS for low-light imaging but reconstruction algorithms for dynamic scenes in low light remain an open problem. We fill the gap by proposing a student-teacher training protocol that transfers knowledge from a motion teacher and a denoising teacher to a student network. We show that dynamic scenes can be reconstructed from a burst of frames at a photon level of 1 photon per pixel per frame. Experimental results confirm the advantages of the proposed method compared to existing methods.