 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF2IDiff: Real-world Image Super-resolution using Feature to Image Diffusion Foundation Model
Dec 30, 2025With the advent of Generative AI, Single Image Super-Resolution (SISR) quality has seen substantial improvement, as the strong priors learned by Text-2-Image Diffusion (T2IDiff) Foundation Models (FM) can bridge the gap between High-Resolution (HR) and Low-Resolution (LR) images. However, flagship smartphone cameras have been slow to adopt generative models because strong generation can lead to undesirable hallucinations. For substantially degraded LR images, as seen in academia, strong generation is required and hallucinations are more tolerable because of the wide gap between LR and HR images. In contrast, in consumer photography, the LR image has substantially higher fidelity, requiring only minimal hallucination-free generation. We hypothesize that generation in SISR is controlled by the stringency and richness of the FM's conditioning feature. First, text features are high level features, which often cannot describe subtle textures in an image. Additionally, Smartphone LR images are at least $12MP$, whereas SISR networks built on T2IDiff FM are designed to perform inference on much smaller images ($<1MP$). As a result, SISR inference has to be performed on small patches, which often cannot be accurately described by text feature. To address these shortcomings, we introduce an SISR network built on a FM with lower-level feature conditioning, specifically DINOv2 features, which we call a Feature-to-Image Diffusion (F2IDiff) Foundation Model (FM). Lower level features provide stricter conditioning while being rich descriptors of even small patches.
Diffusion Algorithm for Metalens Optical Aberration Correction
Nov 16, 2025
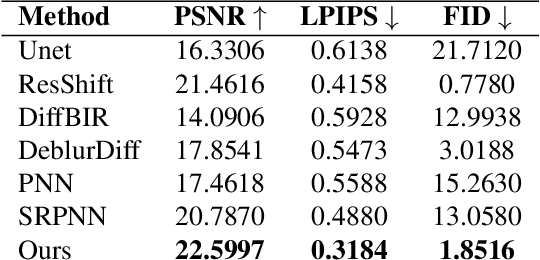


Metalenses offer a path toward creating ultra-thin optical systems, but they inherently suffer from severe, spatially varying optical aberrations, especially chromatic aberration, which makes image reconstruction a significant challenge. This paper presents a novel algorithmic solution to this problem, designed to reconstruct a sharp, full-color image from two inputs: a sharp, bandpass-filtered grayscale ``structure image'' and a heavily distorted ``color cue'' image, both captured by the metalens system. Our method utilizes a dual-branch diffusion model, built upon a pre-trained Stable Diffusion XL framework, to fuse information from the two inputs. We demonstrate through quantitative and qualitative comparisons that our approach significantly outperforms existing deblurring and pansharpening methods, effectively restoring high-frequency details while accurately colorizing the image.
Quanta Video Restoration
Oct 19, 2024The proliferation of single-photon image sensors has opened the door to a plethora of high-speed and low-light imaging applications. However, data collected by these sensors are often 1-bit or few-bit, and corrupted by noise and strong motion. Conventional video restoration methods are not designed to handle this situation, while specialized quanta burst algorithms have limited performance when the number of input frames is low. In this paper, we introduce Quanta Video Restoration (QUIVER), an end-to-end trainable network built on the core ideas of classical quanta restoration methods, i.e., pre-filtering, flow estimation, fusion, and refinement. We also collect and publish I2-2000FPS, a high-speed video dataset with the highest temporal resolution of 2000 frames-per-second, for training and testing. On simulated and real data, QUIVER outperforms existing quanta restoration methods by a significant margin. Code and dataset available at https://github.com/chennuriprateek/Quanta_Video_Restoration-QUIVER-