 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF2IDiff: Real-world Image Super-resolution using Feature to Image Diffusion Foundation Model
Dec 30, 2025With the advent of Generative AI, Single Image Super-Resolution (SISR) quality has seen substantial improvement, as the strong priors learned by Text-2-Image Diffusion (T2IDiff) Foundation Models (FM) can bridge the gap between High-Resolution (HR) and Low-Resolution (LR) images. However, flagship smartphone cameras have been slow to adopt generative models because strong generation can lead to undesirable hallucinations. For substantially degraded LR images, as seen in academia, strong generation is required and hallucinations are more tolerable because of the wide gap between LR and HR images. In contrast, in consumer photography, the LR image has substantially higher fidelity, requiring only minimal hallucination-free generation. We hypothesize that generation in SISR is controlled by the stringency and richness of the FM's conditioning feature. First, text features are high level features, which often cannot describe subtle textures in an image. Additionally, Smartphone LR images are at least $12MP$, whereas SISR networks built on T2IDiff FM are designed to perform inference on much smaller images ($<1MP$). As a result, SISR inference has to be performed on small patches, which often cannot be accurately described by text feature. To address these shortcomings, we introduce an SISR network built on a FM with lower-level feature conditioning, specifically DINOv2 features, which we call a Feature-to-Image Diffusion (F2IDiff) Foundation Model (FM). Lower level features provide stricter conditioning while being rich descriptors of even small patches.
SapientML: Synthesizing Machine Learning Pipelines by Learning from Human-Written Solutions
Feb 18, 2022
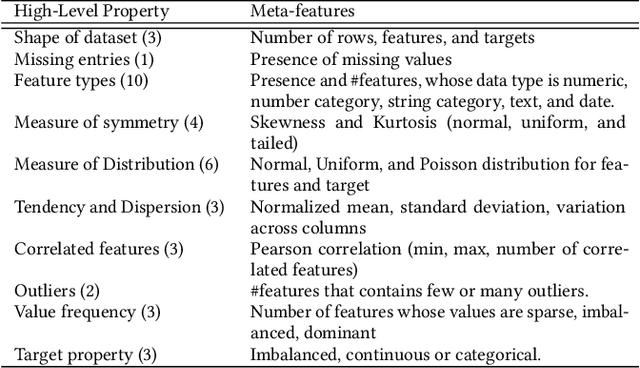

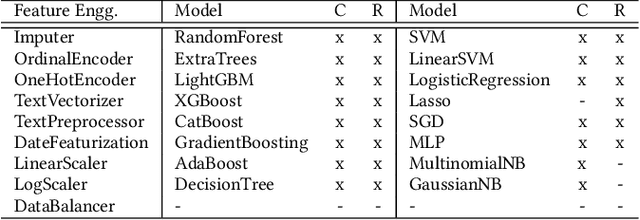
Automatic machine learning, or AutoML, holds the promise of truly democratizing the use of machine learning (ML), by substantially automating the work of data scientists. However, the huge combinatorial search space of candidate pipelines means that current AutoML techniques, generate sub-optimal pipelines, or none at all, especially on large, complex datasets. In this work we propose an AutoML technique SapientML, that can learn from a corpus of existing datasets and their human-written pipelines, and efficiently generate a high-quality pipeline for a predictive task on a new dataset. To combat the search space explosion of AutoML, SapientML employs a novel divide-and-conquer strategy realized as a three-stage program synthesis approach, that reasons on successively smaller search spaces. The first stage uses a machine-learned model to predict a set of plausible ML components to constitute a pipeline. In the second stage, this is then refined into a small pool of viable concrete pipelines using syntactic constraints derived from the corpus and the machine-learned model. Dynamically evaluating these few pipelines, in the third stage, provides the best solution. We instantiate SapientML as part of a fully automated tool-chain that creates a cleaned, labeled learning corpus by mining Kaggle, learns from it, and uses the learned models to then synthesize pipelines for new predictive tasks. We have created a training corpus of 1094 pipelines spanning 170 datasets, and evaluated SapientML on a set of 41 benchmark datasets, including 10 new, large, real-world datasets from Kaggle, and against 3 state-of-the-art AutoML tools and 2 baselines. Our evaluation shows that SapientML produces the best or comparable accuracy on 27 of the benchmarks while the second best tool fails to even produce a pipeline on 9 of the instances.