 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapientML: Synthesizing Machine Learning Pipelines by Learning from Human-Written Solutions
Feb 18, 2022
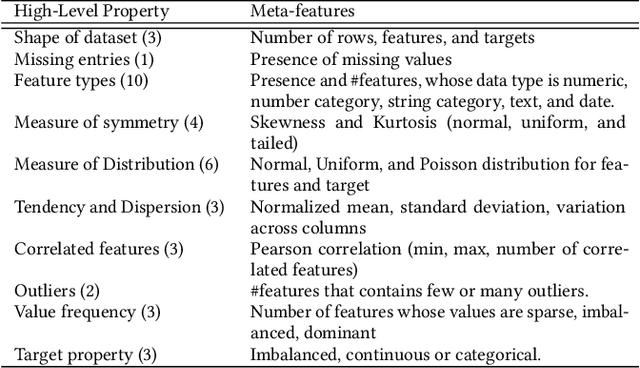

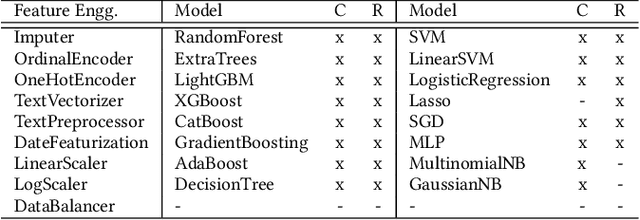
Automatic machine learning, or AutoML, holds the promise of truly democratizing the use of machine learning (ML), by substantially automating the work of data scientists. However, the huge combinatorial search space of candidate pipelines means that current AutoML techniques, generate sub-optimal pipelines, or none at all, especially on large, complex datasets. In this work we propose an AutoML technique SapientML, that can learn from a corpus of existing datasets and their human-written pipelines, and efficiently generate a high-quality pipeline for a predictive task on a new dataset. To combat the search space explosion of AutoML, SapientML employs a novel divide-and-conquer strategy realized as a three-stage program synthesis approach, that reasons on successively smaller search spaces. The first stage uses a machine-learned model to predict a set of plausible ML components to constitute a pipeline. In the second stage, this is then refined into a small pool of viable concrete pipelines using syntactic constraints derived from the corpus and the machine-learned model. Dynamically evaluating these few pipelines, in the third stage, provides the best solution. We instantiate SapientML as part of a fully automated tool-chain that creates a cleaned, labeled learning corpus by mining Kaggle, learns from it, and uses the learned models to then synthesize pipelines for new predictive tasks. We have created a training corpus of 1094 pipelines spanning 170 datasets, and evaluated SapientML on a set of 41 benchmark datasets, including 10 new, large, real-world datasets from Kaggle, and against 3 state-of-the-art AutoML tools and 2 baselines. Our evaluation shows that SapientML produces the best or comparable accuracy on 27 of the benchmarks while the second best tool fails to even produce a pipeline on 9 of the instances.
NeuroComb: Improving SAT Solving with Graph Neural Networks
Oct 28, 2021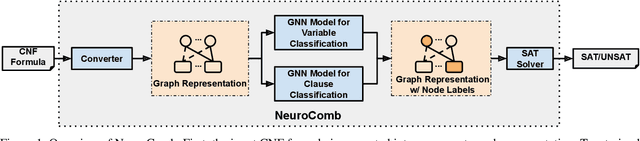
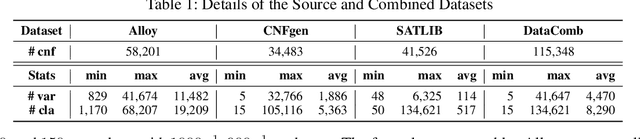
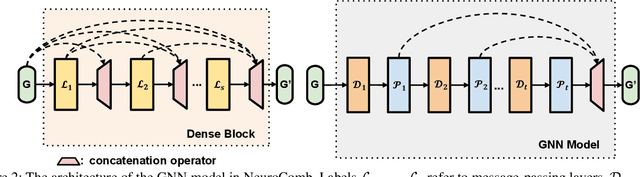
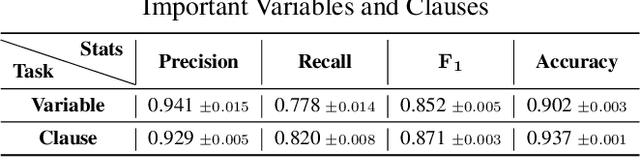
Propositional satisfiability (SAT) is an NP-complete problem that impacts many research fields, such as planning, verification, and security. Despite the remarkable success of modern SAT solvers, scalability still remains a challenge. Main stream modern SAT solvers are based on the Conflict-Driven Clause Learning (CDCL) algorithm. Recent work aimed to enhance CDCL SAT solvers by improving its variable branching heuristics through predictions generated by Graph Neural Networks (GNNs). However, so far this approach either has not made solving more effective, or has required frequent online accesses to substantial GPU resources. Aiming to make GNN improvements practical, this paper proposes an approach called NeuroComb, which builds on two insights: (1) predictions of important variables and clauses can be combined with dynamic branching into a more effective hybrid branching strategy, and (2) it is sufficient to query the neural model only once for the predictions before the SAT solving starts. Implemented as an enhancement to the classic MiniSat solver, NeuroComb allowed it to solve 18.5% more problems on the recent SATCOMP-2020 competition problem set. NeuroComb is therefore a practical approach to improving SAT solving through modern machine learning.
Programming and Training Rate-Independent Chemical Reaction Networks
Sep 20, 2021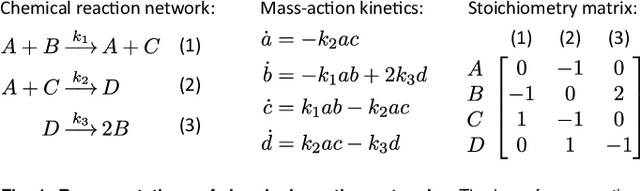
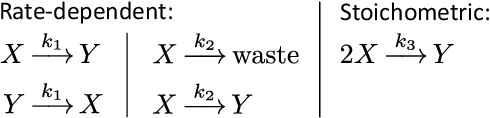
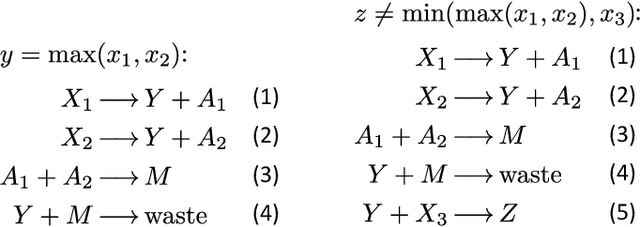
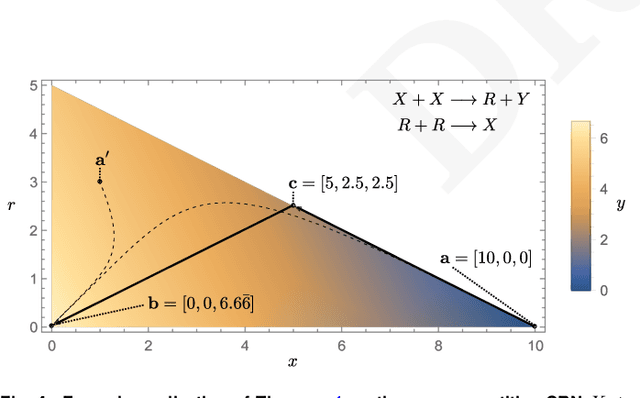
Embedding computation in biochemical environments incompatible with traditional electronics is expected to have wide-ranging impact in synthetic biology, medicine, nanofabrication and other fields. Natural biochemical systems are typically modeled by chemical reaction networks (CRNs), and CRNs can be used as a specification language for synthetic chemical computation. In this paper, we identify a class of CRNs called non-competitive (NC) whose equilibria are absolutely robust to reaction rates and kinetic rate law, because their behavior is captured solely by their stoichiometric structure. Unlike prior work on rate-independent CRNs, checking non-competition and using it as a design criterion is easy and promises robust output. We also present a technique to program NC-CRNs using well-founded deep learning methods, showing a translation procedure from rectified linear unit (ReLU) neural networks to NC-CRNs. In the case of binary weight ReLU networks, our translation procedure is surprisingly tight in the sense that a single bimolecular reaction corresponds to a single ReLU node and vice versa. This compactness argues that neural networks may be a fitting paradigm for programming rate-independent chemical computation. As proof of principle, we demonstrate our scheme with numerical simulations of CRNs translated from neural networks trained on traditional machine learning datasets (IRIS and MNIST), as well as tasks better aligned with potential biological applications including virus detection and spatial pattern formation.
Deep Molecular Programming: A Natural Implementation of Binary-Weight ReLU Neural Networks
Apr 21, 2020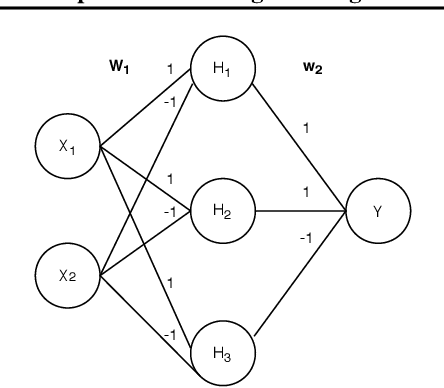
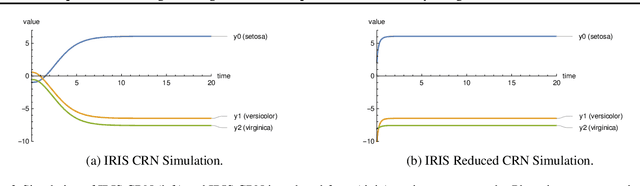
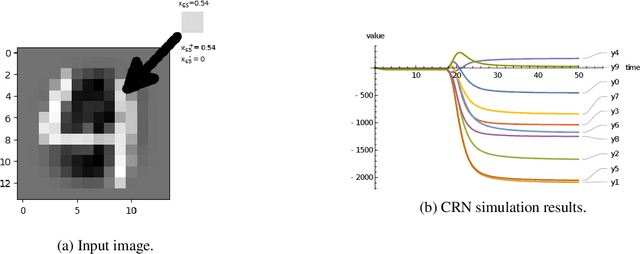
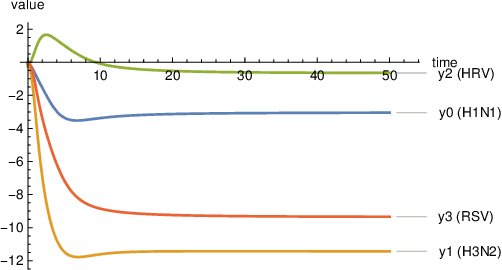
Embedding computation in molecular contexts incompatible with traditional electronics is expected to have wide ranging impact in synthetic biology, medicine, nanofabrication and other fields. A key remaining challenge lies in developing programming paradigms for molecular computation that are well-aligned with the underlying chemical hardware and do not attempt to shoehorn ill-fitting electronics paradigms. We discover a surprisingly tight connection between a popular class of neural networks (Binary-weight ReLU aka BinaryConnect) and a class of coupled chemical reactions that are absolutely robust to reaction rates. The robustness of rate-independent chemical computation makes it a promising target for bioengineering implementation. We show how a BinaryConnect neural network trained in silico using well-founded deep learning optimization techniques, can be compiled to an equivalent chemical reaction network, providing a novel molecular programming paradigm. We illustrate such translation on the paradigmatic IRIS and MNIST datasets. Toward intended applications of chemical computation, we further use our method to generate a CRN that can discriminate between different virus types based on gene expression levels. Our work sets the stage for rich knowledge transfer between neural network and molecular programming communities.
A Study of the Learnability of Relational Properties
Dec 25, 2019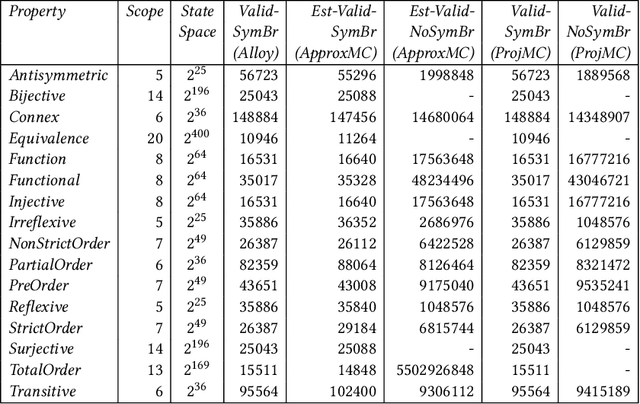
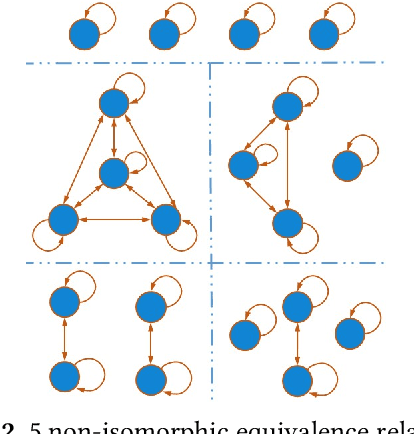
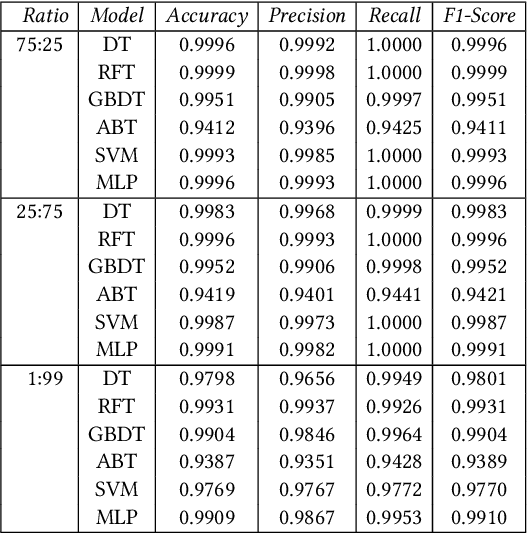
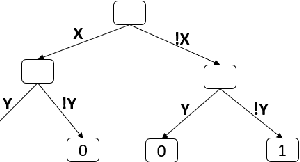
Relational properties, e.g., the connectivity structure of nodes in a distributed system, have many applications in software design and analysis. However, such properties often have to be written manually, which can be costly and error-prone. This paper introduces the MCML approach for empirically studying the learnability of a key class of such properties that can be expressed in the well-known software design language Alloy. A key novelty of MCML is quantification of the performance of and semantic differences among trained machine learning (ML) models, specifically decision trees, with respect to entire input spaces (up to a bound on the input size), and not just for given training and test datasets (as is the common practice). MCML reduces the quantification problems to the classic complexity theory problem of model counting, and employs state-of-the-art approximate and exact model counters for high efficiency. The results show that relatively simple ML models can achieve surprisingly high performance (accuracy and F1 score) at learning relational properties when evaluated in the common setting of using training and test datasets -- even when the training dataset is much smaller than the test dataset -- indicating the seeming simplicity of learning these properties. However, the use of MCML metrics based on model counting shows that the performance can degrade substantially when tested against the whole (bounded) input space, indicating the high complexity of precisely learning these properties, and the usefulness of model counting in quantifying the true accuracy.
MoËT: Interpretable and Verifiable Reinforcement Learning via Mixture of Expert Trees
Jun 16, 2019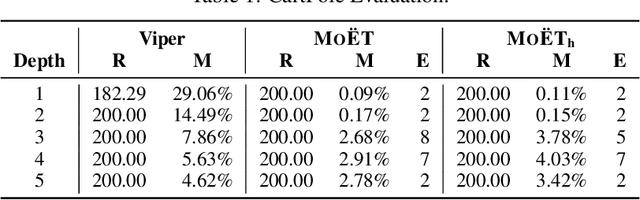
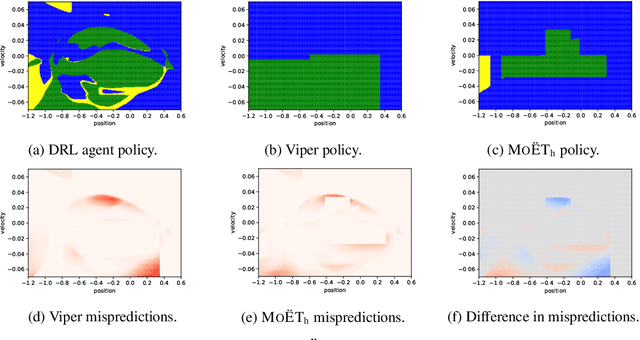
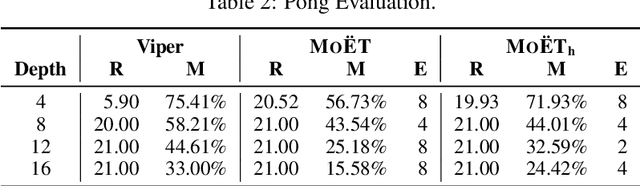
Deep Reinforcement Learning (DRL) has led to many recent breakthroughs on complex control tasks, such as defeating the best human player in the game of Go. However, decisions made by the DRL agent are not explainable, hindering its applicability in safety-critical settings. Viper, a recently proposed technique, constructs a decision tree policy by mimicking the DRL agent. Decision trees are interpretable as each action made can be traced back to the decision rule path that lead to it. However, one global decision tree approximating the DRL policy has significant limitations with respect to the geometry of decision boundaries. We propose Mo\"ET, a more expressive, yet still interpretable model based on Mixture of Experts, consisting of a gating function that partitions the state space, and multiple decision tree experts that specialize on different partitions. We propose a training procedure to support non-differentiable decision tree experts and integrate it into imitation learning procedure of Viper. We evaluate our algorithm on four OpenAI gym environments, and show that the policy constructed in such a way is more performant and better mimics the DRL agent by lowering mispredictions and increasing the reward. We also show that Mo\"ET policies are amenable for verification using off-the-shelf automated theorem provers such as Z3.