 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogit Scaling for Out-of-Distribution Detection
Sep 02, 2024The safe deployment of machine learning and AI models in open-world settings hinges critically on the ability to detect out-of-distribution (OOD) data accurately, data samples that contrast vastly from what the model was trained with. Current approaches to OOD detection often require further training the model, and/or statistics about the training data which may no longer be accessible. Additionally, many existing OOD detection methods struggle to maintain performance when transferred across different architectures. Our research tackles these issues by proposing a simple, post-hoc method that does not require access to the training data distribution, keeps a trained network intact, and holds strong performance across a variety of architectures. Our method, Logit Scaling (LTS), as the name suggests, simply scales the logits in a manner that effectively distinguishes between in-distribution (ID) and OOD samples. We tested our method on benchmarks across various scales, including CIFAR-10, CIFAR-100, ImageNet and OpenOOD. The experiments cover 3 ID and 14 OOD datasets, as well as 9 model architectures. Overall, we demonstrate state-of-the-art performance, robustness and adaptability across different architectures, paving the way towards a universally applicable solution for advanced OOD detection.
Incorporating LLM Priors into Tabular Learners
Nov 20, 2023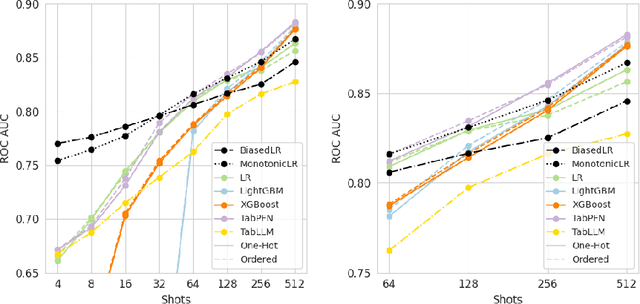
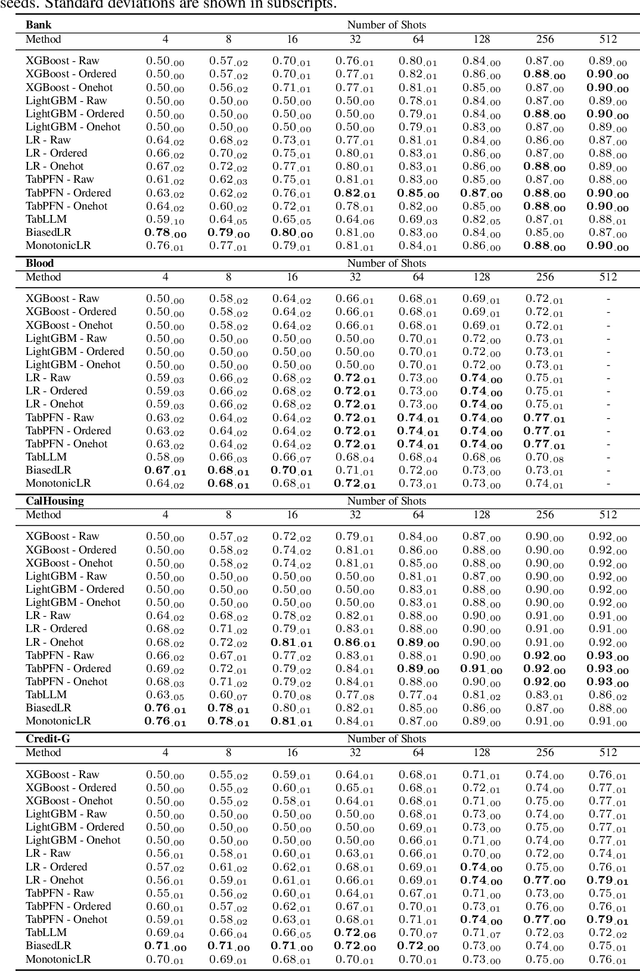
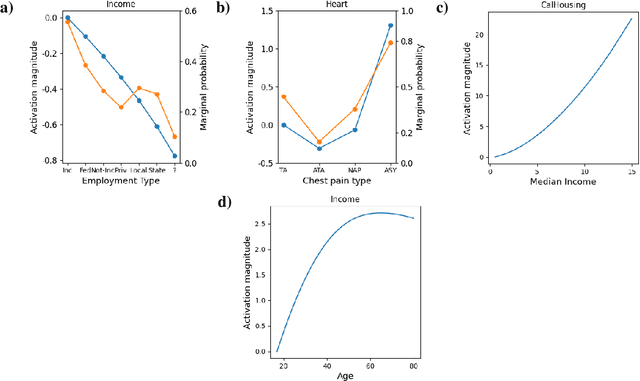
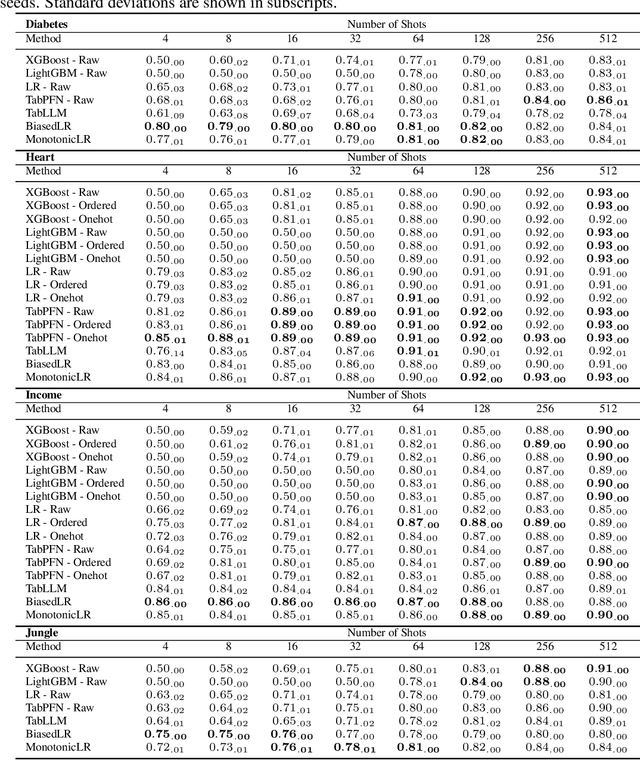
We present a method to integrate Large Language Models (LLMs) and traditional tabular data classification techniques, addressing LLMs challenges like data serialization sensitivity and biases. We introduce two strategies utilizing LLMs for ranking categorical variables and generating priors on correlations between continuous variables and targets, enhancing performance in few-shot scenarios. We focus on Logistic Regression, introducing MonotonicLR that employs a non-linear monotonic function for mapping ordinals to cardinals while preserving LLM-determined orders. Validation against baseline models reveals the superior performance of our approach, especially in low-data scenarios, while remaining interpretable.
Tabular Few-Shot Generalization Across Heterogeneous Feature Spaces
Nov 16, 2023Despite the prevalence of tabular datasets, few-shot learning remains under-explored within this domain. Existing few-shot methods are not directly applicable to tabular datasets due to varying column relationships, meanings, and permutational invariance. To address these challenges, we propose FLAT-a novel approach to tabular few-shot learning, encompassing knowledge sharing between datasets with heterogeneous feature spaces. Utilizing an encoder inspired by Dataset2Vec, FLAT learns low-dimensional embeddings of datasets and their individual columns, which facilitate knowledge transfer and generalization to previously unseen datasets. A decoder network parametrizes the predictive target network, implemented as a Graph Attention Network, to accommodate the heterogeneous nature of tabular datasets. Experiments on a diverse collection of 118 UCI datasets demonstrate FLAT's successful generalization to new tabular datasets and a considerable improvement over the baselines.
Interpretable Medical Diagnostics with Structured Data Extraction by Large Language Models
Jun 08, 2023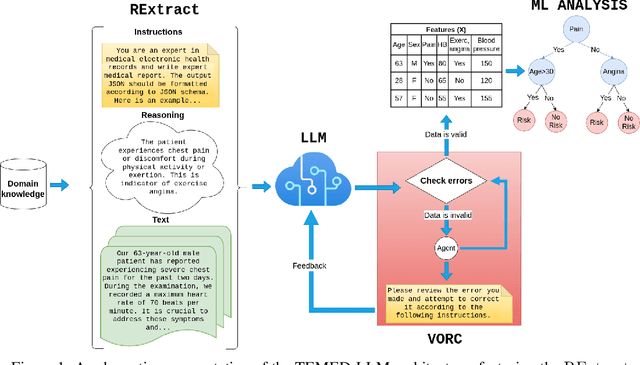
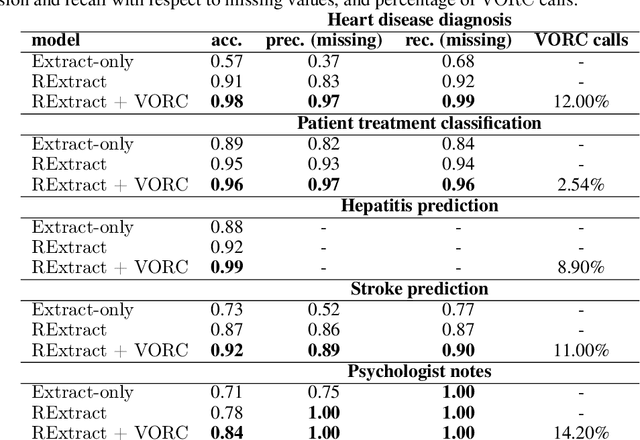
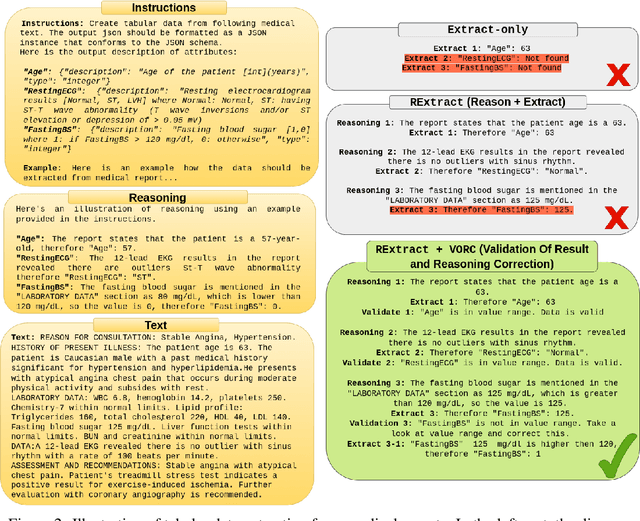
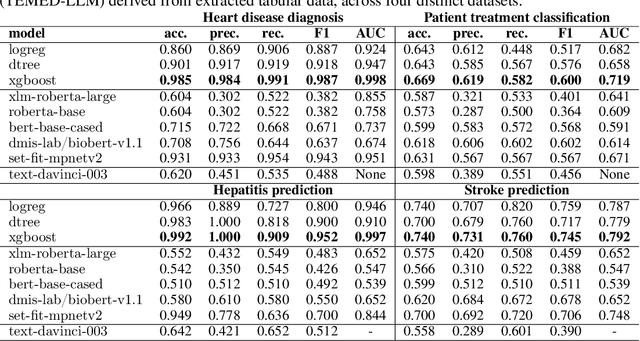
Tabular data is often hidden in text, particularly in medical diagnostic reports. Traditional machine learning (ML) models designed to work with tabular data, cannot effectively process information in such form. On the other hand, large language models (LLMs) which excel at textual tasks, are probably not the best tool for modeling tabular data. Therefore, we propose a novel, simple, and effective methodology for extracting structured tabular data from textual medical reports, called TEMED-LLM. Drawing upon the reasoning capabilities of LLMs, TEMED-LLM goes beyond traditional extraction techniques, accurately inferring tabular features, even when their names are not explicitly mentioned in the text. This is achieved by combining domain-specific reasoning guidelines with a proposed data validation and reasoning correction feedback loop. By applying interpretable ML models such as decision trees and logistic regression over the extracted and validated data, we obtain end-to-end interpretable predictions. We demonstrate that our approach significantly outperforms state-of-the-art text classification models in medical diagnostics. Given its predictive performance, simplicity, and interpretability, TEMED-LLM underscores the potential of leveraging LLMs to improve the performance and trustworthiness of ML models in medical applications.
MoËT: Interpretable and Verifiable Reinforcement Learning via Mixture of Expert Trees
Jun 16, 2019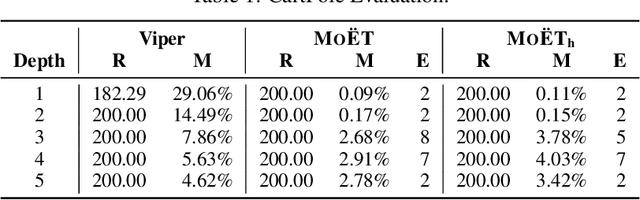
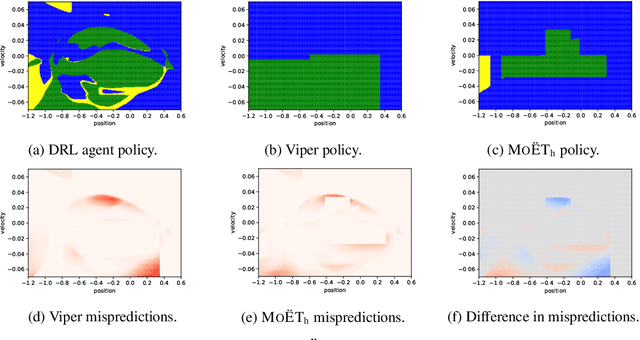
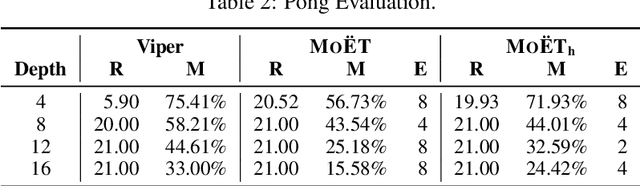
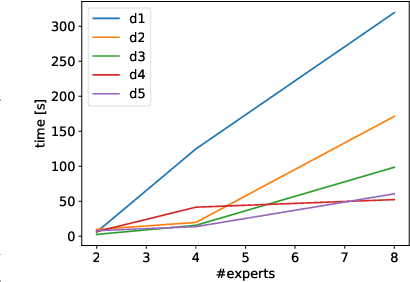
Deep Reinforcement Learning (DRL) has led to many recent breakthroughs on complex control tasks, such as defeating the best human player in the game of Go. However, decisions made by the DRL agent are not explainable, hindering its applicability in safety-critical settings. Viper, a recently proposed technique, constructs a decision tree policy by mimicking the DRL agent. Decision trees are interpretable as each action made can be traced back to the decision rule path that lead to it. However, one global decision tree approximating the DRL policy has significant limitations with respect to the geometry of decision boundaries. We propose Mo\"ET, a more expressive, yet still interpretable model based on Mixture of Experts, consisting of a gating function that partitions the state space, and multiple decision tree experts that specialize on different partitions. We propose a training procedure to support non-differentiable decision tree experts and integrate it into imitation learning procedure of Viper. We evaluate our algorithm on four OpenAI gym environments, and show that the policy constructed in such a way is more performant and better mimics the DRL agent by lowering mispredictions and increasing the reward. We also show that Mo\"ET policies are amenable for verification using off-the-shelf automated theorem provers such as Z3.
Software Verification and Graph Similarity for Automated Evaluation of Students' Assignments
Jun 29, 2012
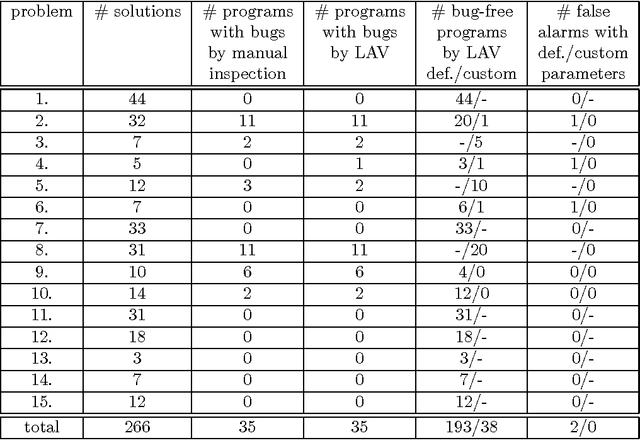


In this paper we promote introducing software verification and control flow graph similarity measurement in automated evaluation of students' programs. We present a new grading framework that merges results obtained by combination of these two approaches with results obtained by automated testing, leading to improved quality and precision of automated grading. These two approaches are also useful in providing a comprehensible feedback that can help students to improve the quality of their programs We also present our corresponding tools that are publicly available and open source. The tools are based on LLVM low-level intermediate code representation, so they could be applied to a number of programming languages. Experimental evaluation of the proposed grading framework is performed on a corpus of university students' programs written in programming language C. Results of the experiments show that automatically generated grades are highly correlated with manually determined grades suggesting that the presented tools can find real-world applications in studying and grading.
Simple Algorithm Portfolio for SAT
Dec 13, 2011
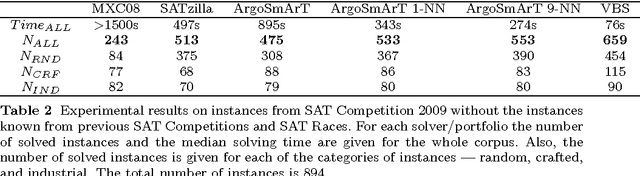
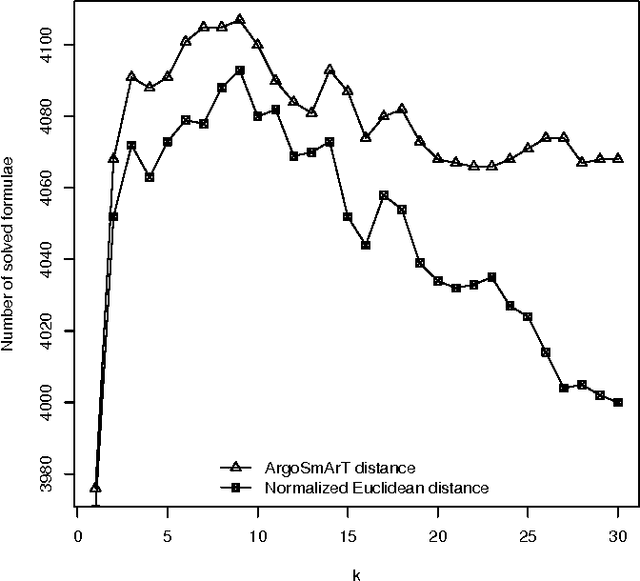
The importance of algorithm portfolio techniques for SAT has long been noted, and a number of very successful systems have been devised, including the most successful one --- SATzilla. However, all these systems are quite complex (to understand, reimplement, or modify). In this paper we propose a new algorithm portfolio for SAT that is extremely simple, but in the same time so efficient that it outperforms SATzilla. For a new SAT instance to be solved, our portfolio finds its k-nearest neighbors from the training set and invokes a solver that performs the best at those instances. The main distinguishing feature of our algorithm portfolio is the locality of the selection procedure --- the selection of a SAT solver is based only on few instances similar to the input one.
Measuring Similarity of Graphs and their Nodes by Neighbor Matching
Sep 27, 2010



The problem of measuring similarity of graphs and their nodes is important in a range of practical problems. There is a number of proposed measures, some of them being based on iterative calculation of similarity between two graphs and the principle that two nodes are as similar as their neighbors are. In our work, we propose one novel method of that sort, with a refined concept of similarity of two nodes that involves matching of their neighbors. We prove convergence of the proposed method and show that it has some additional desirable properties that, to our knowledge, the existing methods lack. We illustrate the method on two specific problems and empirically compare it to other methods.