 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Modernization of Machine Learning Engineering Notebooks for Reproducibility
Feb 06, 2026Interactive computational notebooks (e.g., Jupyter notebooks) are widely used in machine learning engineering (MLE) to program and share end-to-end pipelines, from data preparation to model training and evaluation. However, environment erosion-the rapid evolution of hardware and software ecosystems for machine learning-has rendered many published MLE notebooks non-reproducible in contemporary environments, hindering code reuse and scientific progress. To quantify this gap, we study 12,720 notebooks mined from 79 popular Kaggle competitions: only 35.4% remain reproducible today. Crucially, we find that environment backporting, i.e., downgrading dependencies to match the submission time, does not improve reproducibility but rather introduces additional failure modes. To address environment erosion, we design and implement MLEModernizer, an LLM-driven agentic framework that treats the contemporary environment as a fixed constraint and modernizes notebook code to restore reproducibility. MLEModernizer iteratively executes notebooks, collects execution feedback, and applies targeted fixes in three types: error-repair, runtime-reduction, and score-calibration. Evaluated on 7,402 notebooks that are non-reproducible under the baseline environment, MLEModernizer makes 5,492 (74.2%) reproducible. MLEModernizer enables practitioners to validate, reuse, and maintain MLE artifacts as the hardware and software ecosystems continue to evolve.
C2PSA-Enhanced YOLOv11 Architecture: A Novel Approach for Small Target Detection in Cotton Disease Diagnosis
Aug 17, 2025This study presents a deep learning-based optimization of YOLOv11 for cotton disease detection, developing an intelligent monitoring system. Three key challenges are addressed: (1) low precision in early spot detection (35% leakage rate for sub-5mm2 spots), (2) performance degradation in field conditions (25% accuracy drop), and (3) high error rates (34.7%) in multi-disease scenarios. The proposed solutions include: C2PSA module for enhanced small-target feature extraction; Dynamic category weighting to handle sample imbalance; Improved data augmentation via Mosaic-MixUp scaling. Experimental results on a 4,078-image dataset show: mAP50: 0.820 (+8.0% improvement); mAP50-95: 0.705 (+10.5% improvement); Inference speed: 158 FPS. The mobile-deployed system enables real-time disease monitoring and precision treatment in agricultural applications.
Scalable Machine Learning Training Infrastructure for Online Ads Recommendation and Auction Scoring Modeling at Google
Jan 17, 2025



Large-scale Ads recommendation and auction scoring models at Google scale demand immense computational resources. While specialized hardware like TPUs have improved linear algebra computations, bottlenecks persist in large-scale systems. This paper proposes solutions for three critical challenges that must be addressed for efficient end-to-end execution in a widely used production infrastructure: (1) Input Generation and Ingestion Pipeline: Efficiently transforming raw features (e.g., "search query") into numerical inputs and streaming them to TPUs; (2) Large Embedding Tables: Optimizing conversion of sparse features into dense floating-point vectors for neural network consumption; (3) Interruptions and Error Handling: Minimizing resource wastage in large-scale shared datacenters. To tackle these challenges, we propose a shared input generation technique to reduce computational load of input generation by amortizing costs across many models. Furthermore, we propose partitioning, pipelining, and RPC (Remote Procedure Call) coalescing software techniques to optimize embedding operations. To maintain efficiency at scale, we describe novel preemption notice and training hold mechanisms that minimize resource wastage, and ensure prompt error resolution. These techniques have demonstrated significant improvement in Google production, achieving a 116% performance boost and an 18% reduction in training costs across representative models.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
FinLLMs: A Framework for Financial Reasoning Dataset Generation with Large Language Models
Jan 19, 2024



Large Language models (LLMs) usually rely on extensive training datasets. In the financial domain, creating numerical reasoning datasets that include a mix of tables and long text often involves substantial manual annotation expenses. To address the limited data resources and reduce the annotation cost, we introduce FinLLMs, a method for generating financial question-answering data based on common financial formulas using Large Language Models. First, we compile a list of common financial formulas and construct a graph based on the variables these formulas employ. We then augment the formula set by combining those that share identical variables as new elements. Specifically, we explore formulas obtained by manual annotation and merge those formulas with shared variables by traversing the constructed graph. Finally, utilizing GPT-3.5, we generate financial question-answering data that encompasses both tabular information and long textual content, building on the collected formula set. Our experiments demonstrate that synthetic data generated by FinLLMs effectively enhances the performance of several large-scale numerical reasoning models in the financial domain, outperforming two established benchmark financial question-answering datasets.
SuPerPM: A Large Deformation-Robust Surgical Perception Framework Based on Deep Point Matching Learned from Physical Constrained Simulation Data
Sep 25, 2023Manipulation of tissue with surgical tools often results in large deformations that current methods in tracking and reconstructing algorithms have not effectively addressed. A major source of tracking errors during large deformations stems from wrong data association between observed sensor measurements with previously tracked scene. To mitigate this issue, we present a surgical perception framework, SuPerPM, that leverages learning-based non-rigid point cloud matching for data association, thus accommodating larger deformations. The learning models typically require training data with ground truth point cloud correspondences, which is challenging or even impractical to collect in surgical environments. Thus, for tuning the learning model, we gather endoscopic data of soft tissue being manipulated by a surgical robot and then establish correspondences between point clouds at different time points to serve as ground truth. This was achieved by employing a position-based dynamics (PBD) simulation to ensure that the correspondences adhered to physical constraints. The proposed framework is demonstrated on several challenging surgical datasets that are characterized by large deformations, achieving superior performance over state-of-the-art surgical scene tracking algorithms.
AnyOKP: One-Shot and Instance-Aware Object Keypoint Extraction with Pretrained ViT
Sep 15, 2023



Towards flexible object-centric visual perception, we propose a one-shot instance-aware object keypoint (OKP) extraction approach, AnyOKP, which leverages the powerful representation ability of pretrained vision transformer (ViT), and can obtain keypoints on multiple object instances of arbitrary category after learning from a support image. An off-the-shelf petrained ViT is directly deployed for generalizable and transferable feature extraction, which is followed by training-free feature enhancement. The best-prototype pairs (BPPs) are searched for in support and query images based on appearance similarity, to yield instance-unaware candidate keypoints.Then, the entire graph with all candidate keypoints as vertices are divided to sub-graphs according to the feature distributions on the graph edges. Finally, each sub-graph represents an object instance. AnyOKP is evaluated on real object images collected with the cameras of a robot arm, a mobile robot, and a surgical robot, which not only demonstrates the cross-category flexibility and instance awareness, but also show remarkable robustness to domain shift and viewpoint change.
Symbolic Discovery of Optimization Algorithms
Feb 17, 2023



We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
A Study of the Learnability of Relational Properties
Dec 25, 2019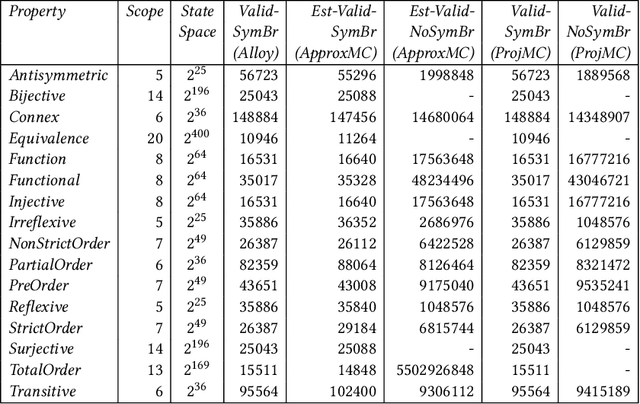
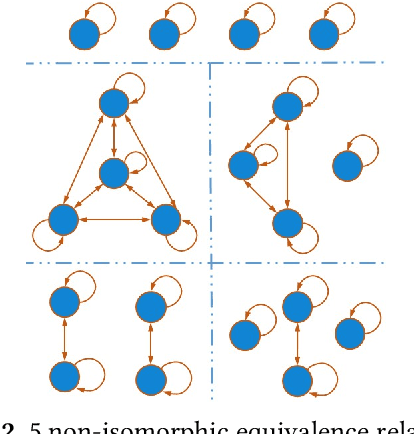
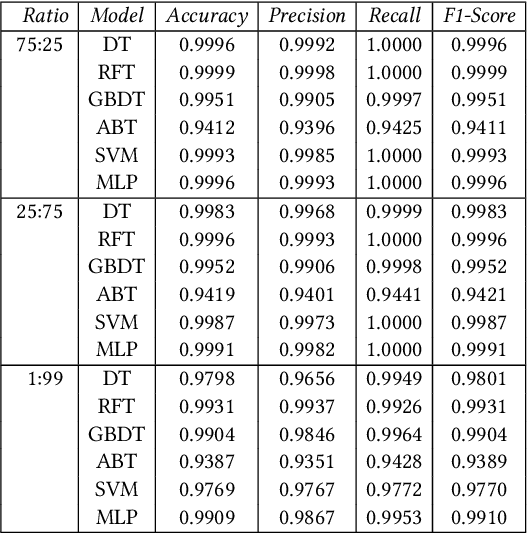
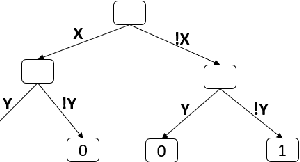
Relational properties, e.g., the connectivity structure of nodes in a distributed system, have many applications in software design and analysis. However, such properties often have to be written manually, which can be costly and error-prone. This paper introduces the MCML approach for empirically studying the learnability of a key class of such properties that can be expressed in the well-known software design language Alloy. A key novelty of MCML is quantification of the performance of and semantic differences among trained machine learning (ML) models, specifically decision trees, with respect to entire input spaces (up to a bound on the input size), and not just for given training and test datasets (as is the common practice). MCML reduces the quantification problems to the classic complexity theory problem of model counting, and employs state-of-the-art approximate and exact model counters for high efficiency. The results show that relatively simple ML models can achieve surprisingly high performance (accuracy and F1 score) at learning relational properties when evaluated in the common setting of using training and test datasets -- even when the training dataset is much smaller than the test dataset -- indicating the seeming simplicity of learning these properties. However, the use of MCML metrics based on model counting shows that the performance can degrade substantially when tested against the whole (bounded) input space, indicating the high complexity of precisely learning these properties, and the usefulness of model counting in quantifying the true accuracy.
MoËT: Interpretable and Verifiable Reinforcement Learning via Mixture of Expert Trees
Jun 16, 2019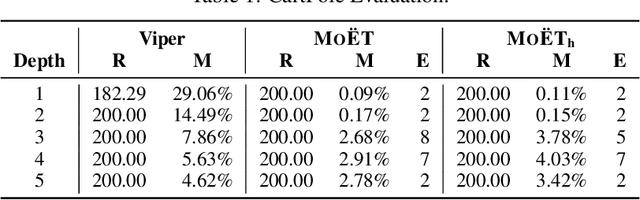
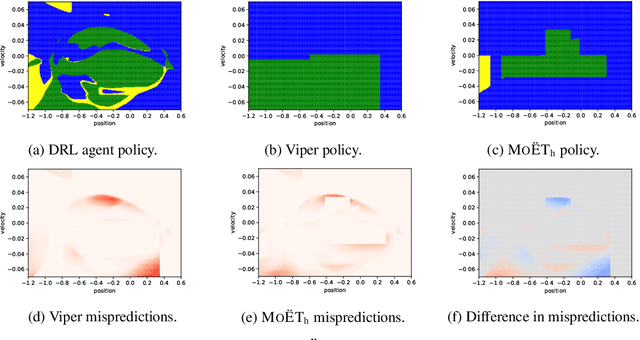
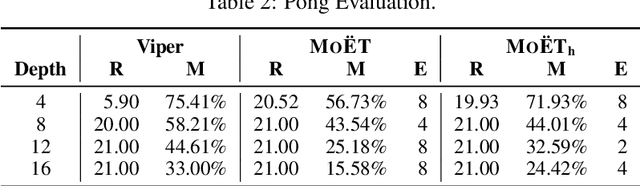
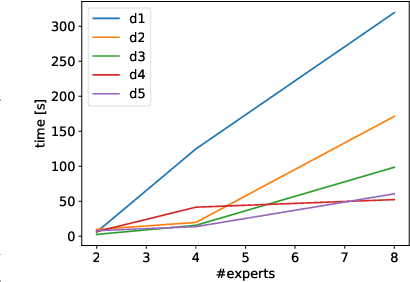
Deep Reinforcement Learning (DRL) has led to many recent breakthroughs on complex control tasks, such as defeating the best human player in the game of Go. However, decisions made by the DRL agent are not explainable, hindering its applicability in safety-critical settings. Viper, a recently proposed technique, constructs a decision tree policy by mimicking the DRL agent. Decision trees are interpretable as each action made can be traced back to the decision rule path that lead to it. However, one global decision tree approximating the DRL policy has significant limitations with respect to the geometry of decision boundaries. We propose Mo\"ET, a more expressive, yet still interpretable model based on Mixture of Experts, consisting of a gating function that partitions the state space, and multiple decision tree experts that specialize on different partitions. We propose a training procedure to support non-differentiable decision tree experts and integrate it into imitation learning procedure of Viper. We evaluate our algorithm on four OpenAI gym environments, and show that the policy constructed in such a way is more performant and better mimics the DRL agent by lowering mispredictions and increasing the reward. We also show that Mo\"ET policies are amenable for verification using off-the-shelf automated theorem provers such as Z3.