 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinLLMs: A Framework for Financial Reasoning Dataset Generation with Large Language Models
Jan 19, 2024



Large Language models (LLMs) usually rely on extensive training datasets. In the financial domain, creating numerical reasoning datasets that include a mix of tables and long text often involves substantial manual annotation expenses. To address the limited data resources and reduce the annotation cost, we introduce FinLLMs, a method for generating financial question-answering data based on common financial formulas using Large Language Models. First, we compile a list of common financial formulas and construct a graph based on the variables these formulas employ. We then augment the formula set by combining those that share identical variables as new elements. Specifically, we explore formulas obtained by manual annotation and merge those formulas with shared variables by traversing the constructed graph. Finally, utilizing GPT-3.5, we generate financial question-answering data that encompasses both tabular information and long textual content, building on the collected formula set. Our experiments demonstrate that synthetic data generated by FinLLMs effectively enhances the performance of several large-scale numerical reasoning models in the financial domain, outperforming two established benchmark financial question-answering datasets.
DySuse: Susceptibility Estimation in Dynamic Social Networks
Aug 21, 2023



Influence estimation aims to predict the total influence spread in social networks and has received surged attention in recent years. Most current studies focus on estimating the total number of influenced users in a social network, and neglect susceptibility estimation that aims to predict the probability of each user being influenced from the individual perspective. As a more fine-grained estimation task, susceptibility estimation is full of attractiveness and practical value. Based on the significance of susceptibility estimation and dynamic properties of social networks, we propose a task, called susceptibility estimation in dynamic social networks, which is even more realistic and valuable in real-world applications. Susceptibility estimation in dynamic networks has yet to be explored so far and is computationally intractable to naively adopt Monte Carlo simulation to obtain the results. To this end, we propose a novel end-to-end framework DySuse based on dynamic graph embedding technology. Specifically, we leverage a structural feature module to independently capture the structural information of influence diffusion on each single graph snapshot. Besides, {we propose the progressive mechanism according to the property of influence diffusion,} to couple the structural and temporal information during diffusion tightly. Moreover, a self-attention block {is designed to} further capture temporal dependency by flexibly weighting historical timestamps. Experimental results show that our framework is superior to the existing dynamic graph embedding models and has satisfactory prediction performance in multiple influence diffusion models.
* This paper has been published in Expert Systems With Applications
Explicit Time Embedding Based Cascade Attention Network for Information Popularity Prediction
Aug 19, 2023Predicting information cascade popularity is a fundamental problem in social networks. Capturing temporal attributes and cascade role information (e.g., cascade graphs and cascade sequences) is necessary for understanding the information cascade. Current methods rarely focus on unifying this information for popularity predictions, which prevents them from effectively modeling the full properties of cascades to achieve satisfactory prediction performances. In this paper, we propose an explicit Time embedding based Cascade Attention Network (TCAN) as a novel popularity prediction architecture for large-scale information networks. TCAN integrates temporal attributes (i.e., periodicity, linearity, and non-linear scaling) into node features via a general time embedding approach (TE), and then employs a cascade graph attention encoder (CGAT) and a cascade sequence attention encoder (CSAT) to fully learn the representation of cascade graphs and cascade sequences. We use two real-world datasets (i.e., Weibo and APS) with tens of thousands of cascade samples to validate our methods. Experimental results show that TCAN obtains mean logarithm squared errors of 2.007 and 1.201 and running times of 1.76 hours and 0.15 hours on both datasets, respectively. Furthermore, TCAN outperforms other representative baselines by 10.4%, 3.8%, and 10.4% in terms of MSLE, MAE, and R-squared on average while maintaining good interpretability.
Securing Distributed SGD against Gradient Leakage Threats
May 10, 2023This paper presents a holistic approach to gradient leakage resilient distributed Stochastic Gradient Descent (SGD). First, we analyze two types of strategies for privacy-enhanced federated learning: (i) gradient pruning with random selection or low-rank filtering and (ii) gradient perturbation with additive random noise or differential privacy noise. We analyze the inherent limitations of these approaches and their underlying impact on privacy guarantee, model accuracy, and attack resilience. Next, we present a gradient leakage resilient approach to securing distributed SGD in federated learning, with differential privacy controlled noise as the tool. Unlike conventional methods with the per-client federated noise injection and fixed noise parameter strategy, our approach keeps track of the trend of per-example gradient updates. It makes adaptive noise injection closely aligned throughout the federated model training. Finally, we provide an empirical privacy analysis on the privacy guarantee, model utility, and attack resilience of the proposed approach. Extensive evaluation using five benchmark datasets demonstrates that our gradient leakage resilient approach can outperform the state-of-the-art methods with competitive accuracy performance, strong differential privacy guarantee, and high resilience against gradient leakage attacks. The code associated with this paper can be found: https://github.com/git-disl/Fed-alphaCDP.
Network Representation Learning: From Preprocessing, Feature Extraction to Node Embedding
Oct 14, 2021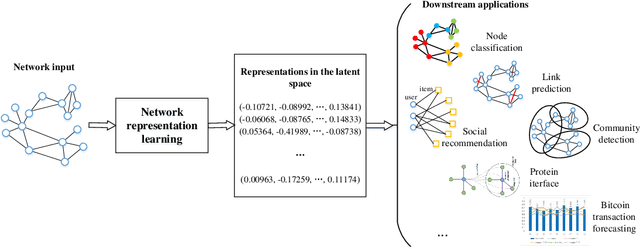

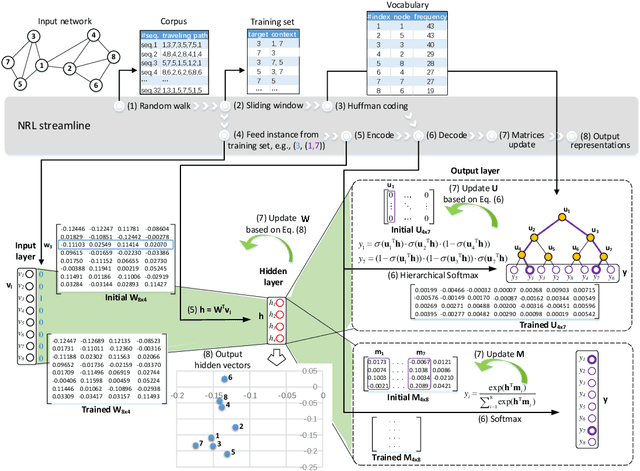
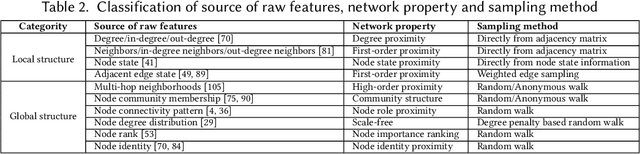
Network representation learning (NRL) advances the conventional graph mining of social networks, knowledge graphs, and complex biomedical and physics information networks. Over dozens of network representation learning algorithms have been reported in the literature. Most of them focus on learning node embeddings for homogeneous networks, but they differ in the specific encoding schemes and specific types of node semantics captured and used for learning node embedding. This survey paper reviews the design principles and the different node embedding techniques for network representation learning over homogeneous networks. To facilitate the comparison of different node embedding algorithms, we introduce a unified reference framework to divide and generalize the node embedding learning process on a given network into preprocessing steps, node feature extraction steps and node embedding model training for a NRL task such as link prediction and node clustering. With this unifying reference framework, we highlight the representative methods, models, and techniques used at different stages of the node embedding model learning process. This survey not only helps researchers and practitioners to gain an in-depth understanding of different network representation learning techniques but also provides practical guidelines for designing and developing the next generation of network representation learning algorithms and systems.