 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCU: Improving Machine Unlearning through Mode Connectivity
May 16, 2025Machine Unlearning (MU) aims to remove the information of specific training data from a trained model, ensuring compliance with privacy regulations and user requests. While one line of existing MU methods relies on linear parameter updates via task arithmetic, they suffer from weight entanglement. In this work, we propose a novel MU framework called Mode Connectivity Unlearning (MCU) that leverages mode connectivity to find an unlearning pathway in a nonlinear manner. To further enhance performance and efficiency, we introduce a parameter mask strategy that not only improves unlearning effectiveness but also reduces computational overhead. Moreover, we propose an adaptive adjustment strategy for our unlearning penalty coefficient to adaptively balance forgetting quality and predictive performance during training, eliminating the need for empirical hyperparameter tuning. Unlike traditional MU methods that identify only a single unlearning model, MCU uncovers a spectrum of unlearning models along the pathway. Overall, MCU serves as a plug-and-play framework that seamlessly integrates with any existing MU methods, consistently improving unlearning efficacy. Extensive experiments on the image classification task demonstrate that MCU achieves superior performance.
HODDI: A Dataset of High-Order Drug-Drug Interactions for Computational Pharmacovigilance
Feb 10, 2025
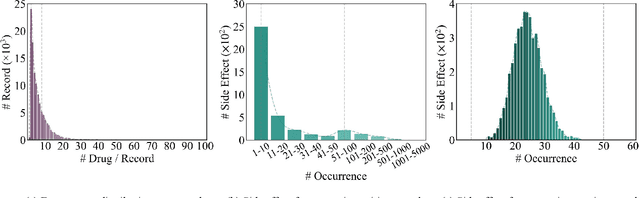
Drug-side effect research is vital for understanding adverse reactions arising in complex multi-drug therapies. However, the scarcity of higher-order datasets that capture the combinatorial effects of multiple drugs severely limits progress in this field. Existing resources such as TWOSIDES primarily focus on pairwise interactions. To fill this critical gap, we introduce HODDI, the first Higher-Order Drug-Drug Interaction Dataset, constructed from U.S. Food and Drug Administration (FDA) Adverse Event Reporting System (FAERS) records spanning the past decade, to advance computational pharmacovigilance. HODDI contains 109,744 records involving 2,506 unique drugs and 4,569 unique side effects, specifically curated to capture multi-drug interactions and their collective impact on adverse effects. Comprehensive statistical analyses demonstrate HODDI's extensive coverage and robust analytical metrics, making it a valuable resource for studying higher-order drug relationships. Evaluating HODDI with multiple models, we found that simple Multi-Layer Perceptron (MLP) can outperform graph models, while hypergraph models demonstrate superior performance in capturing complex multi-drug interactions, further validating HODDI's effectiveness. Our findings highlight the inherent value of higher-order information in drug-side effect prediction and position HODDI as a benchmark dataset for advancing research in pharmacovigilance, drug safety, and personalized medicine. The dataset and codes are available at https://github.com/TIML-Group/HODDI.
Redefining Machine Unlearning: A Conformal Prediction-Motivated Approach
Jan 31, 2025



Machine unlearning seeks to systematically remove specified data from a trained model, effectively achieving a state as though the data had never been encountered during training. While metrics such as Unlearning Accuracy (UA) and Membership Inference Attack (MIA) provide a baseline for assessing unlearning performance, they fall short of evaluating the completeness and reliability of forgetting. This is because the ground truth labels remain potential candidates within the scope of uncertainty quantification, leaving gaps in the evaluation of true forgetting. In this paper, we identify critical limitations in existing unlearning metrics and propose enhanced evaluation metrics inspired by conformal prediction. Our metrics can effectively capture the extent to which ground truth labels are excluded from the prediction set. Furthermore, we observe that many existing machine unlearning methods do not achieve satisfactory forgetting performance when evaluated with our new metrics. To address this, we propose an unlearning framework that integrates conformal prediction insights into Carlini & Wagner adversarial attack loss. Extensive experiments on the image classification task demonstrate that our enhanced metrics offer deeper insights into unlearning effectiveness, and that our unlearning framework significantly improves the forgetting quality of unlearning methods.
DySuse: Susceptibility Estimation in Dynamic Social Networks
Aug 21, 2023



Influence estimation aims to predict the total influence spread in social networks and has received surged attention in recent years. Most current studies focus on estimating the total number of influenced users in a social network, and neglect susceptibility estimation that aims to predict the probability of each user being influenced from the individual perspective. As a more fine-grained estimation task, susceptibility estimation is full of attractiveness and practical value. Based on the significance of susceptibility estimation and dynamic properties of social networks, we propose a task, called susceptibility estimation in dynamic social networks, which is even more realistic and valuable in real-world applications. Susceptibility estimation in dynamic networks has yet to be explored so far and is computationally intractable to naively adopt Monte Carlo simulation to obtain the results. To this end, we propose a novel end-to-end framework DySuse based on dynamic graph embedding technology. Specifically, we leverage a structural feature module to independently capture the structural information of influence diffusion on each single graph snapshot. Besides, {we propose the progressive mechanism according to the property of influence diffusion,} to couple the structural and temporal information during diffusion tightly. Moreover, a self-attention block {is designed to} further capture temporal dependency by flexibly weighting historical timestamps. Experimental results show that our framework is superior to the existing dynamic graph embedding models and has satisfactory prediction performance in multiple influence diffusion models.
* This paper has been published in Expert Systems With Applications