 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Redundancy-Aware Diffusion for Multi-Agent Communication Structure Generation
May 11, 2026Compared with individual agents, large language model based multi-agent systems have shown great capabilities consistently across diverse tasks, including code generation, mathematical reasoning, and planning, etc. Despite their impressive performance, the effectiveness and robustness of these systems heavily rely on their communication topology, which is often fixed or generated in a single step. This restricts fine-grained structural exploration and flexible composition, resulting in excessive token utilization on simple tasks while limiting capability on complicated tasks. To mitigate this challenge, we introduce RADAR, a redundancy-aware and query-adaptive generative framework that actively reduce communication overhead. Motivated by recent progress in conditional discrete graph diffusion models, we formulate communication topology design as a step-by-step generation process, guided by the effective size of the graph. Comprehensive experiments on six benchmarks demonstrate that RADAR consistently outperforms recent baselines, achieving higher accuracy, lower token consumption, and greater robustness across diverse scenarios. Our code and data are available at https://github.com/cszhangzhen/RADAR.
TrajSurv: Learning Continuous Latent Trajectories from Electronic Health Records for Trustworthy Survival Prediction
Aug 01, 2025Trustworthy survival prediction is essential for clinical decision making. Longitudinal electronic health records (EHRs) provide a uniquely powerful opportunity for the prediction. However, it is challenging to accurately model the continuous clinical progression of patients underlying the irregularly sampled clinical features and to transparently link the progression to survival outcomes. To address these challenges, we develop TrajSurv, a model that learns continuous latent trajectories from longitudinal EHR data for trustworthy survival prediction. TrajSurv employs a neural controlled differential equation (NCDE) to extract continuous-time latent states from the irregularly sampled data, forming continuous latent trajectories. To ensure the latent trajectories reflect the clinical progression, TrajSurv aligns the latent state space with patient state space through a time-aware contrastive learning approach. To transparently link clinical progression to the survival outcome, TrajSurv uses latent trajectories in a two-step divide-and-conquer interpretation process. First, it explains how the changes in clinical features translate into the latent trajectory's evolution using a learned vector field. Second, it clusters these latent trajectories to identify key clinical progression patterns associated with different survival outcomes. Evaluations on two real-world medical datasets, MIMIC-III and eICU, show TrajSurv's competitive accuracy and superior transparency over existing deep learning methods.
HODDI: A Dataset of High-Order Drug-Drug Interactions for Computational Pharmacovigilance
Feb 10, 2025
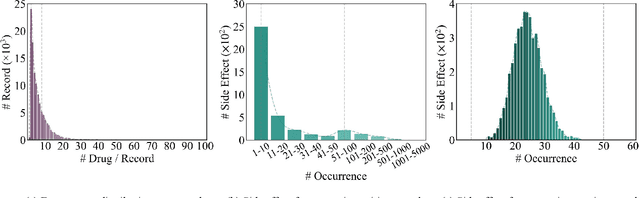
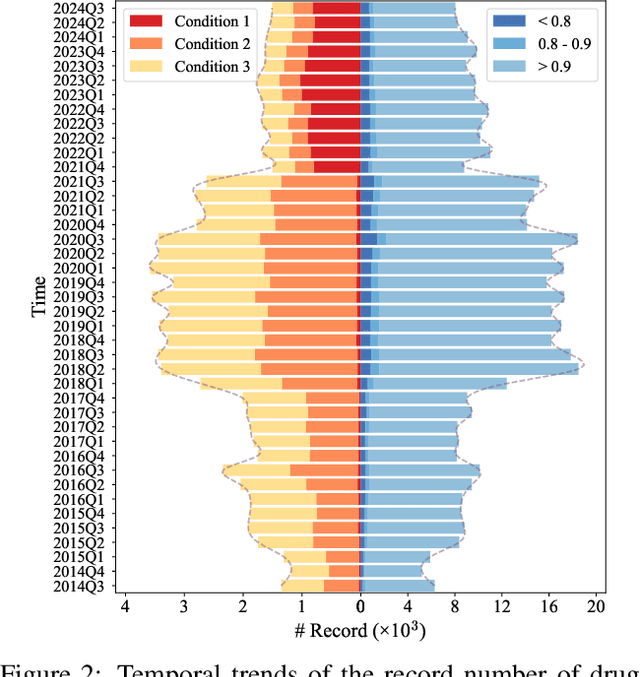
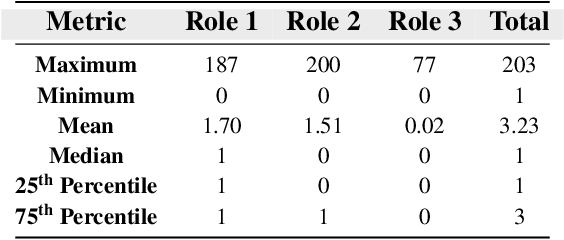
Drug-side effect research is vital for understanding adverse reactions arising in complex multi-drug therapies. However, the scarcity of higher-order datasets that capture the combinatorial effects of multiple drugs severely limits progress in this field. Existing resources such as TWOSIDES primarily focus on pairwise interactions. To fill this critical gap, we introduce HODDI, the first Higher-Order Drug-Drug Interaction Dataset, constructed from U.S. Food and Drug Administration (FDA) Adverse Event Reporting System (FAERS) records spanning the past decade, to advance computational pharmacovigilance. HODDI contains 109,744 records involving 2,506 unique drugs and 4,569 unique side effects, specifically curated to capture multi-drug interactions and their collective impact on adverse effects. Comprehensive statistical analyses demonstrate HODDI's extensive coverage and robust analytical metrics, making it a valuable resource for studying higher-order drug relationships. Evaluating HODDI with multiple models, we found that simple Multi-Layer Perceptron (MLP) can outperform graph models, while hypergraph models demonstrate superior performance in capturing complex multi-drug interactions, further validating HODDI's effectiveness. Our findings highlight the inherent value of higher-order information in drug-side effect prediction and position HODDI as a benchmark dataset for advancing research in pharmacovigilance, drug safety, and personalized medicine. The dataset and codes are available at https://github.com/TIML-Group/HODDI.
LATTE: Label-efficient Incident Phenotyping from Longitudinal Electronic Health Records
May 19, 2023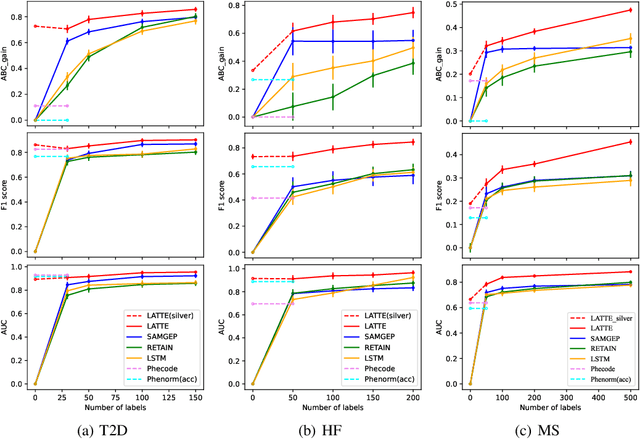
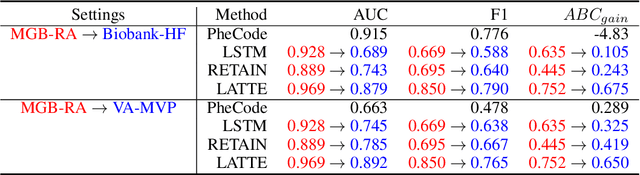

Electronic health record (EHR) data are increasingly used to support real-world evidence (RWE) studies. Yet its ability to generate reliable RWE is limited by the lack of readily available precise information on the timing of clinical events such as the onset time of heart failure. We propose a LAbel-efficienT incidenT phEnotyping (LATTE) algorithm to accurately annotate the timing of clinical events from longitudinal EHR data. By leveraging the pre-trained semantic embedding vectors from large-scale EHR data as prior knowledge, LATTE selects predictive EHR features in a concept re-weighting module by mining their relationship to the target event and compresses their information into longitudinal visit embeddings through a visit attention learning network. LATTE employs a recurrent neural network to capture the sequential dependency between the target event and visit embeddings before/after it. To improve label efficiency, LATTE constructs highly informative longitudinal silver-standard labels from large-scale unlabeled patients to perform unsupervised pre-training and semi-supervised joint training. Finally, LATTE enhances cross-site portability via contrastive representation learning. LATTE is evaluated on three analyses: the onset of type-2 diabetes, heart failure, and the onset and relapses of multiple sclerosis. We use various evaluation metrics present in the literature including the $ABC_{gain}$, the proportion of reduction in the area between the observed event indicator and the predicted cumulative incidences in reference to the prediction per incident prevalence. LATTE consistently achieves substantial improvement over benchmark methods such as SAMGEP and RETAIN in all settings.
Discriminative Radial Domain Adaptation
Jan 01, 2023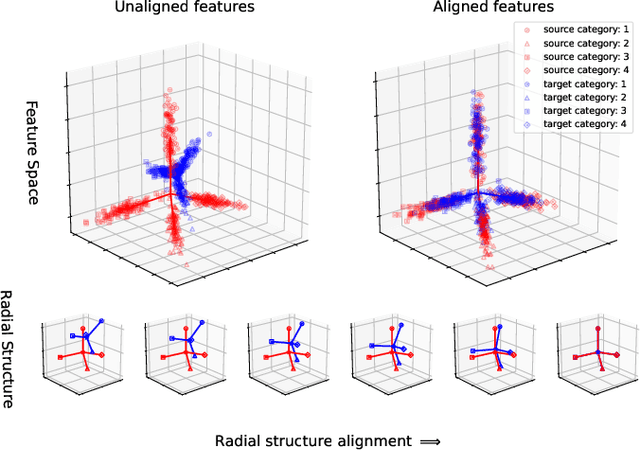
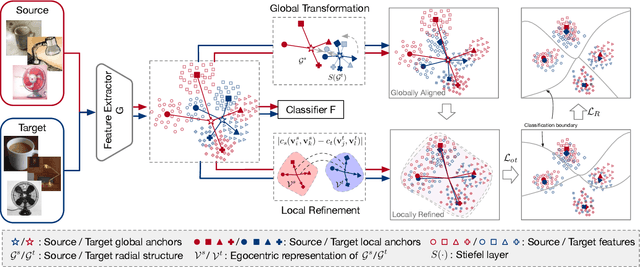
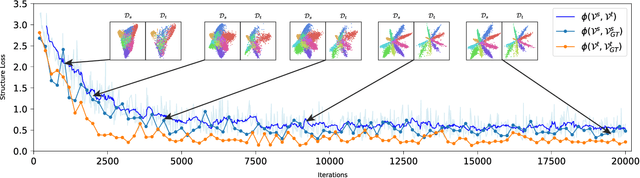
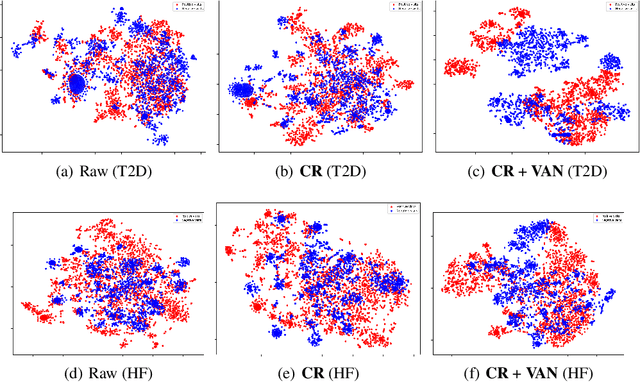
Domain adaptation methods reduce domain shift typically by learning domain-invariant features. Most existing methods are built on distribution matching, e.g., adversarial domain adaptation, which tends to corrupt feature discriminability. In this paper, we propose Discriminative Radial Domain Adaptation (DRDR) which bridges source and target domains via a shared radial structure. It's motivated by the observation that as the model is trained to be progressively discriminative, features of different categories expand outwards in different directions, forming a radial structure. We show that transferring such an inherently discriminative structure would enable to enhance feature transferability and discriminability simultaneously. Specifically, we represent each domain with a global anchor and each category a local anchor to form a radial structure and reduce domain shift via structure matching. It consists of two parts, namely isometric transformation to align the structure globally and local refinement to match each category. To enhance the discriminability of the structure, we further encourage samples to cluster close to the corresponding local anchors based on optimal-transport assignment. Extensively experimenting on multiple benchmarks, our method is shown to consistently outperforms state-of-the-art approaches on varied tasks, including the typical unsupervised domain adaptation, multi-source domain adaptation, domain-agnostic learning, and domain generalization.
Contrast-reconstruction Representation Learning for Self-supervised Skeleton-based Action Recognition
Nov 22, 2021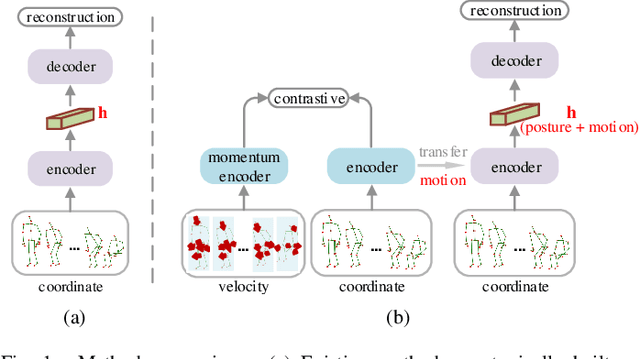
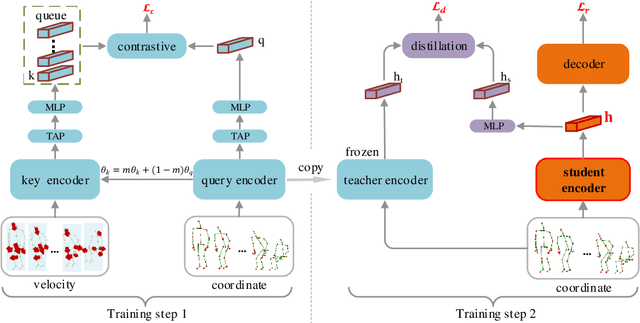
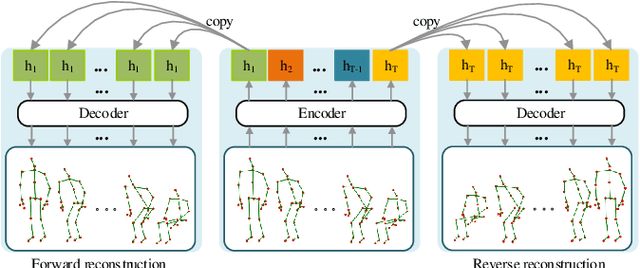
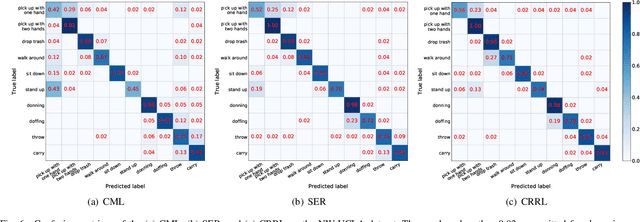
Skeleton-based action recognition is widely used in varied areas, e.g., surveillance and human-machine interaction. Existing models are mainly learned in a supervised manner, thus heavily depending on large-scale labeled data which could be infeasible when labels are prohibitively expensive. In this paper, we propose a novel Contrast-Reconstruction Representation Learning network (CRRL) that simultaneously captures postures and motion dynamics for unsupervised skeleton-based action recognition. It mainly consists of three parts: Sequence Reconstructor, Contrastive Motion Learner, and Information Fuser. The Sequence Reconstructor learns representation from skeleton coordinate sequence via reconstruction, thus the learned representation tends to focus on trivial postural coordinates and be hesitant in motion learning. To enhance the learning of motions, the Contrastive Motion Learner performs contrastive learning between the representations learned from coordinate sequence and additional velocity sequence, respectively. Finally, in the Information Fuser, we explore varied strategies to combine the Sequence Reconstructor and Contrastive Motion Learner, and propose to capture postures and motions simultaneously via a knowledge-distillation based fusion strategy that transfers the motion learning from the Contrastive Motion Learner to the Sequence Reconstructor. Experimental results on several benchmarks, i.e., NTU RGB+D 60, NTU RGB+D 120, CMU mocap, and NW-UCLA, demonstrate the promise of the proposed CRRL method by far outperforming state-of-the-art approaches.
Semi-Supervised Hypothesis Transfer for Source-Free Domain Adaptation
Jul 14, 2021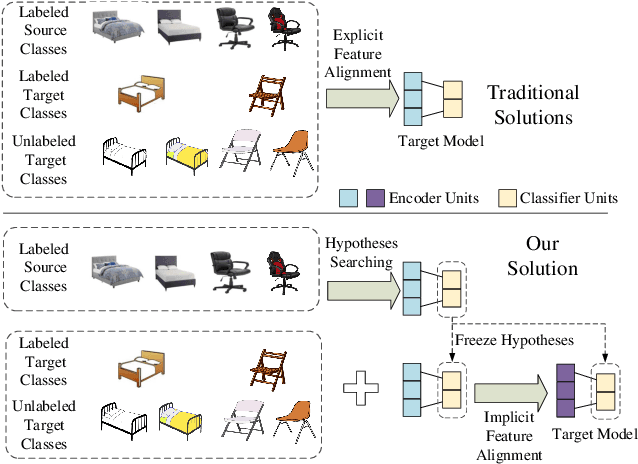
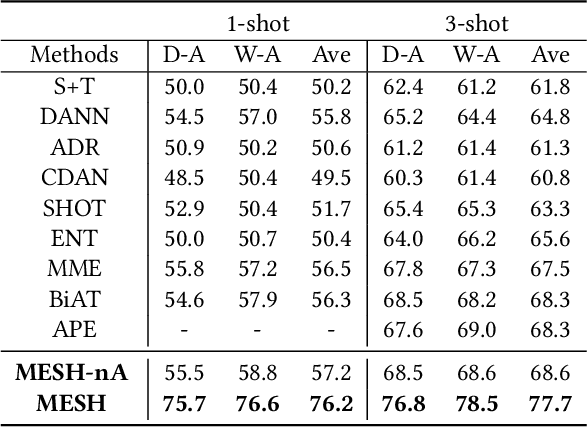
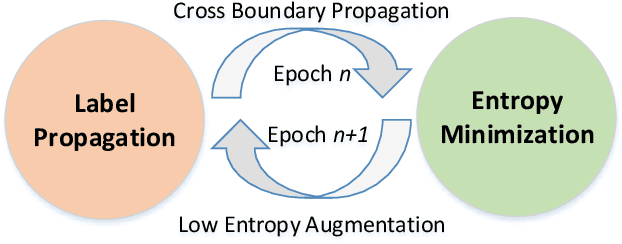
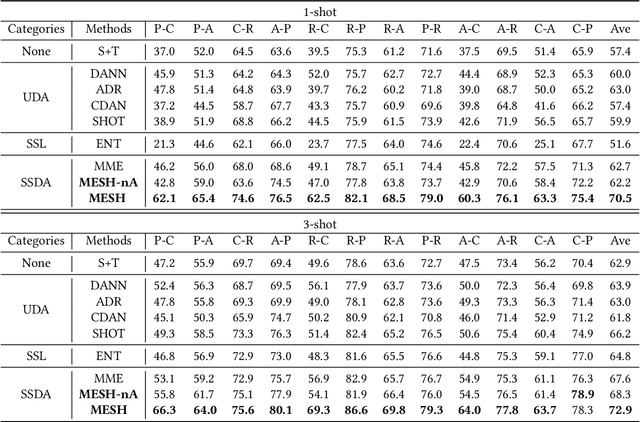
Domain Adaptation has been widely used to deal with the distribution shift in vision, language, multimedia etc. Most domain adaptation methods learn domain-invariant features with data from both domains available. However, such a strategy might be infeasible in practice when source data are unavailable due to data-privacy concerns. To address this issue, we propose a novel adaptation method via hypothesis transfer without accessing source data at adaptation stage. In order to fully use the limited target data, a semi-supervised mutual enhancement method is proposed, in which entropy minimization and augmented label propagation are used iteratively to perform inter-domain and intra-domain alignments. Compared with state-of-the-art methods, the experimental results on three public datasets demonstrate that our method gets up to 19.9% improvements on semi-supervised adaptation tasks.
Interventional Domain Adaptation
Nov 07, 2020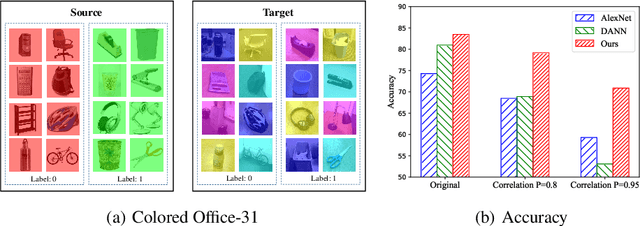
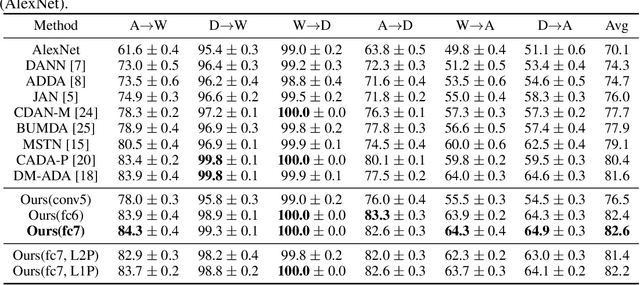
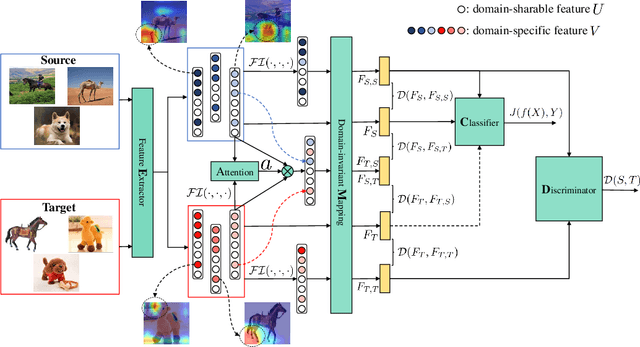
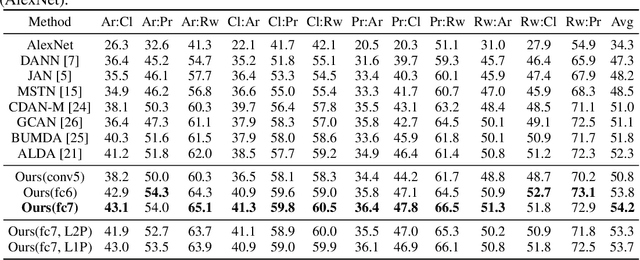
Domain adaptation (DA) aims to transfer discriminative features learned from source domain to target domain. Most of DA methods focus on enhancing feature transferability through domain-invariance learning. However, source-learned discriminability itself might be tailored to be biased and unsafely transferable by spurious correlations, \emph{i.e.}, part of source-specific features are correlated with category labels. We find that standard domain-invariance learning suffers from such correlations and incorrectly transfers the source-specifics. To address this issue, we intervene in the learning of feature discriminability using unlabeled target data to guide it to get rid of the domain-specific part and be safely transferable. Concretely, we generate counterfactual features that distinguish the domain-specifics from domain-sharable part through a novel feature intervention strategy. To prevent the residence of domain-specifics, the feature discriminability is trained to be invariant to the mutations in the domain-specifics of counterfactual features. Experimenting on typical \emph{one-to-one} unsupervised domain adaptation and challenging domain-agnostic adaptation tasks, the consistent performance improvements of our method over state-of-the-art approaches validate that the learned discriminative features are more safely transferable and generalize well to novel domains.
Beyond $\mathcal{H}$-Divergence: Domain Adaptation Theory With Jensen-Shannon Divergence
Jul 30, 2020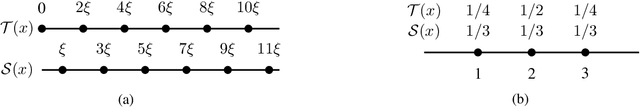

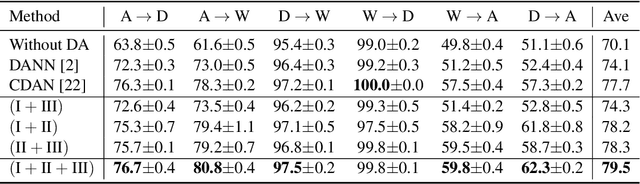
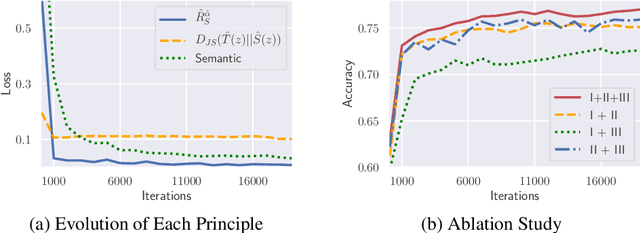
We reveal the incoherence between the widely-adopted empirical domain adversarial training and its generally-assumed theoretical counterpart based on $\mathcal{H}$-divergence. Concretely, we find that $\mathcal{H}$-divergence is not equivalent to Jensen-Shannon divergence, the optimization objective in domain adversarial training. To this end, we establish a new theoretical framework by directly proving the upper and lower target risk bounds based on joint distributional Jensen-Shannon divergence. We further derive bi-directional upper bounds for marginal and conditional shifts. Our framework exhibits inherent flexibilities for different transfer learning problems, which is usable for various scenarios where $\mathcal{H}$-divergence-based theory fails to adapt. From an algorithmic perspective, our theory enables a generic guideline unifying principles of semantic conditional matching, feature marginal matching, and label marginal shift correction. We employ algorithms for each principle and empirically validate the benefits of our framework on real datasets.
Deep Robotic Prediction with hierarchical RGB-D Fusion
Sep 17, 2019
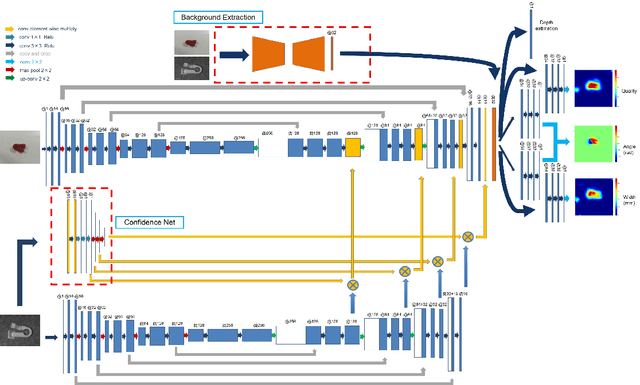


Robotic arm grasping is a fundamental operation in robotic control task goals. Most current methods for robotic grasping focus on RGB-D policy in the table surface scenario or 3D point cloud analysis and inference in the 3D space. Comparing to these methods, we propose a novel real-time multimodal hierarchical encoder-decoder neural network that fuses RGB and depth data to realize robotic humanoid grasping in 3D space with only partial observation. The quantification of raw depth data's uncertainty and depth estimation fusing RGB is considered. We develop a general labeling method to label ground-truth on common RGB-D datasets. We evaluate the effectiveness and performance of our method on a physical robot setup and our method achieves over 90\% success rate in both table surface and 3D space scenarios.