 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast-reconstruction Representation Learning for Self-supervised Skeleton-based Action Recognition
Paper and Code
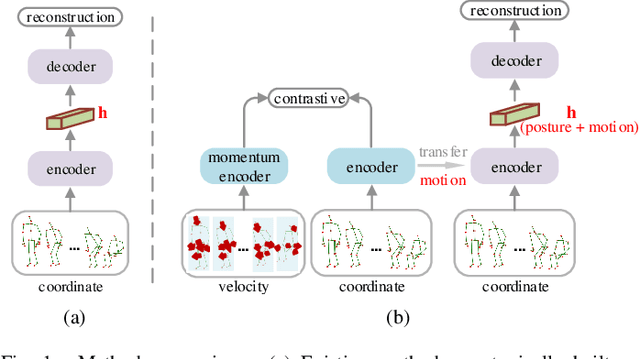
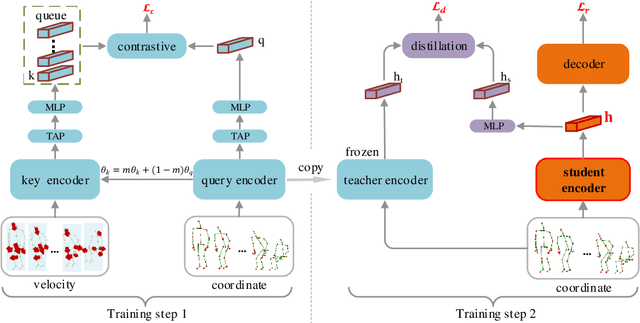
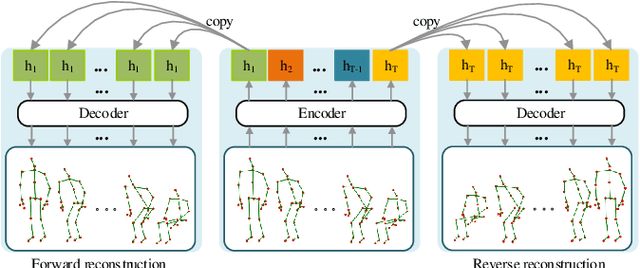
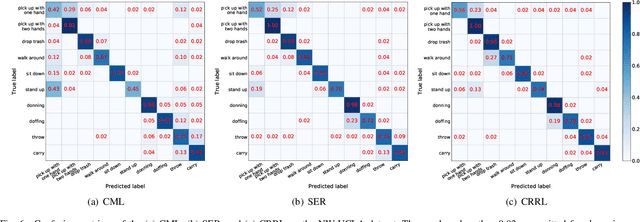
Skeleton-based action recognition is widely used in varied areas, e.g., surveillance and human-machine interaction. Existing models are mainly learned in a supervised manner, thus heavily depending on large-scale labeled data which could be infeasible when labels are prohibitively expensive. In this paper, we propose a novel Contrast-Reconstruction Representation Learning network (CRRL) that simultaneously captures postures and motion dynamics for unsupervised skeleton-based action recognition. It mainly consists of three parts: Sequence Reconstructor, Contrastive Motion Learner, and Information Fuser. The Sequence Reconstructor learns representation from skeleton coordinate sequence via reconstruction, thus the learned representation tends to focus on trivial postural coordinates and be hesitant in motion learning. To enhance the learning of motions, the Contrastive Motion Learner performs contrastive learning between the representations learned from coordinate sequence and additional velocity sequence, respectively. Finally, in the Information Fuser, we explore varied strategies to combine the Sequence Reconstructor and Contrastive Motion Learner, and propose to capture postures and motions simultaneously via a knowledge-distillation based fusion strategy that transfers the motion learning from the Contrastive Motion Learner to the Sequence Reconstructor. Experimental results on several benchmarks, i.e., NTU RGB+D 60, NTU RGB+D 120, CMU mocap, and NW-UCLA, demonstrate the promise of the proposed CRRL method by far outperforming state-of-the-art approaches.