 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Aware Guidance for Blind Image Restoration via Diffusion Models
Nov 19, 2024



Blind image restoration remains a significant challenge in low-level vision tasks. Recently, denoising diffusion models have shown remarkable performance in image synthesis. Guided diffusion models, leveraging the potent generative priors of pre-trained models along with a differential guidance loss, have achieved promising results in blind image restoration. However, these models typically consider data consistency solely in the spatial domain, often resulting in distorted image content. In this paper, we propose a novel frequency-aware guidance loss that can be integrated into various diffusion models in a plug-and-play manner. Our proposed guidance loss, based on 2D discrete wavelet transform, simultaneously enforces content consistency in both the spatial and frequency domains. Experimental results demonstrate the effectiveness of our method in three blind restoration tasks: blind image deblurring, imaging through turbulence, and blind restoration for multiple degradations. Notably, our method achieves a significant improvement in PSNR score, with a remarkable enhancement of 3.72\,dB in image deblurring. Moreover, our method exhibits superior capability in generating images with rich details and reduced distortion, leading to the best visual quality.
Intersectional Unfairness Discovery
May 31, 2024

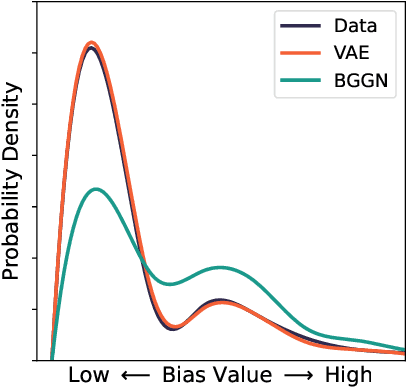
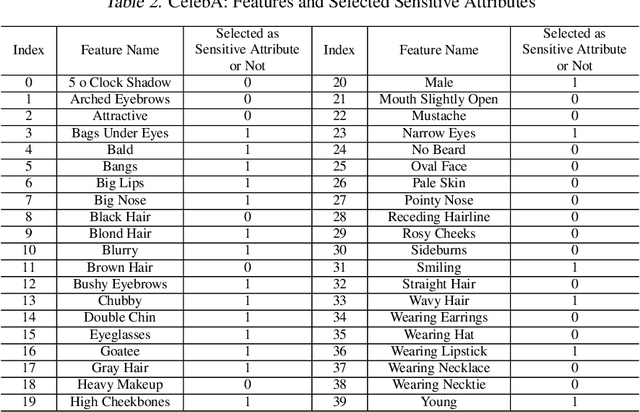
AI systems have been shown to produce unfair results for certain subgroups of population, highlighting the need to understand bias on certain sensitive attributes. Current research often falls short, primarily focusing on the subgroups characterized by a single sensitive attribute, while neglecting the nature of intersectional fairness of multiple sensitive attributes. This paper focuses on its one fundamental aspect by discovering diverse high-bias subgroups under intersectional sensitive attributes. Specifically, we propose a Bias-Guided Generative Network (BGGN). By treating each bias value as a reward, BGGN efficiently generates high-bias intersectional sensitive attributes. Experiments on real-world text and image datasets demonstrate a diverse and efficient discovery of BGGN. To further evaluate the generated unseen but possible unfair intersectional sensitive attributes, we formulate them as prompts and use modern generative AI to produce new texts and images. The results of frequently generating biased data provides new insights of discovering potential unfairness in popular modern generative AI systems. Warning: This paper contains generative examples that are offensive in nature.
Generalizing across Temporal Domains with Koopman Operators
Feb 15, 2024



In the field of domain generalization, the task of constructing a predictive model capable of generalizing to a target domain without access to target data remains challenging. This problem becomes further complicated when considering evolving dynamics between domains. While various approaches have been proposed to address this issue, a comprehensive understanding of the underlying generalization theory is still lacking. In this study, we contribute novel theoretic results that aligning conditional distribution leads to the reduction of generalization bounds. Our analysis serves as a key motivation for solving the Temporal Domain Generalization (TDG) problem through the application of Koopman Neural Operators, resulting in Temporal Koopman Networks (TKNets). By employing Koopman Operators, we effectively address the time-evolving distributions encountered in TDG using the principles of Koopman theory, where measurement functions are sought to establish linear transition relations between evolving domains. Through empirical evaluations conducted on synthetic and real-world datasets, we validate the effectiveness of our proposed approach.
Hessian Aware Low-Rank Weight Perturbation for Continual Learning
Nov 26, 2023Continual learning aims to learn a series of tasks sequentially without forgetting the knowledge acquired from the previous ones. In this work, we propose the Hessian Aware Low-Rank Perturbation algorithm for continual learning. By modeling the parameter transitions along the sequential tasks with the weight matrix transformation, we propose to apply the low-rank approximation on the task-adaptive parameters in each layer of the neural networks. Specifically, we theoretically demonstrate the quantitative relationship between the Hessian and the proposed low-rank approximation. The approximation ranks are then globally determined according to the marginal increment of the empirical loss estimated by the layer-specific gradient and low-rank approximation error. Furthermore, we control the model capacity by pruning less important parameters to diminish the parameter growth. We conduct extensive experiments on various benchmarks, including a dataset with large-scale tasks, and compare our method against some recent state-of-the-art methods to demonstrate the effectiveness and scalability of our proposed method. Empirical results show that our method performs better on different benchmarks, especially in achieving task order robustness and handling the forgetting issue. A demo code can be found at https://github.com/lijiaqi/HALRP.
Mitigating Calibration Bias Without Fixed Attribute Grouping for Improved Fairness in Medical Imaging Analysis
Jul 20, 2023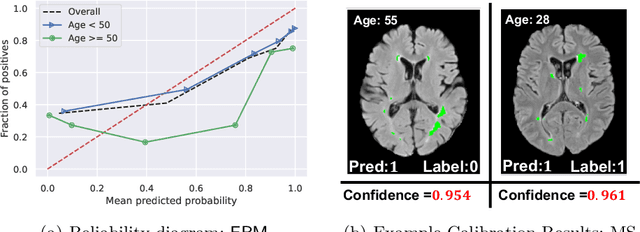
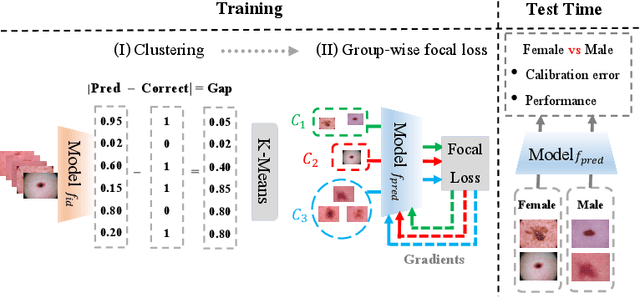

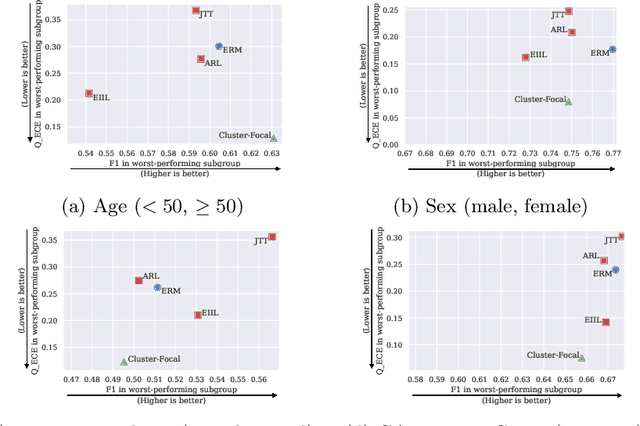
Trustworthy deployment of deep learning medical imaging models into real-world clinical practice requires that they be calibrated. However, models that are well calibrated overall can still be poorly calibrated for a sub-population, potentially resulting in a clinician unwittingly making poor decisions for this group based on the recommendations of the model. Although methods have been shown to successfully mitigate biases across subgroups in terms of model accuracy, this work focuses on the open problem of mitigating calibration biases in the context of medical image analysis. Our method does not require subgroup attributes during training, permitting the flexibility to mitigate biases for different choices of sensitive attributes without re-training. To this end, we propose a novel two-stage method: Cluster-Focal to first identify poorly calibrated samples, cluster them into groups, and then introduce group-wise focal loss to improve calibration bias. We evaluate our method on skin lesion classification with the public HAM10000 dataset, and on predicting future lesional activity for multiple sclerosis (MS) patients. In addition to considering traditional sensitive attributes (e.g. age, sex) with demographic subgroups, we also consider biases among groups with different image-derived attributes, such as lesion load, which are required in medical image analysis. Our results demonstrate that our method effectively controls calibration error in the worst-performing subgroups while preserving prediction performance, and outperforming recent baselines.
Evaluating the Fairness of Deep Learning Uncertainty Estimates in Medical Image Analysis
Mar 06, 2023



Although deep learning (DL) models have shown great success in many medical image analysis tasks, deployment of the resulting models into real clinical contexts requires: (1) that they exhibit robustness and fairness across different sub-populations, and (2) that the confidence in DL model predictions be accurately expressed in the form of uncertainties. Unfortunately, recent studies have indeed shown significant biases in DL models across demographic subgroups (e.g., race, sex, age) in the context of medical image analysis, indicating a lack of fairness in the models. Although several methods have been proposed in the ML literature to mitigate a lack of fairness in DL models, they focus entirely on the absolute performance between groups without considering their effect on uncertainty estimation. In this work, we present the first exploration of the effect of popular fairness models on overcoming biases across subgroups in medical image analysis in terms of bottom-line performance, and their effects on uncertainty quantification. We perform extensive experiments on three different clinically relevant tasks: (i) skin lesion classification, (ii) brain tumour segmentation, and (iii) Alzheimer's disease clinical score regression. Our results indicate that popular ML methods, such as data-balancing and distributionally robust optimization, succeed in mitigating fairness issues in terms of the model performances for some of the tasks. However, this can come at the cost of poor uncertainty estimates associated with the model predictions. This tradeoff must be mitigated if fairness models are to be adopted in medical image analysis.
Clinically Plausible Pathology-Anatomy Disentanglement in Patient Brain MRI with Structured Variational Priors
Nov 16, 2022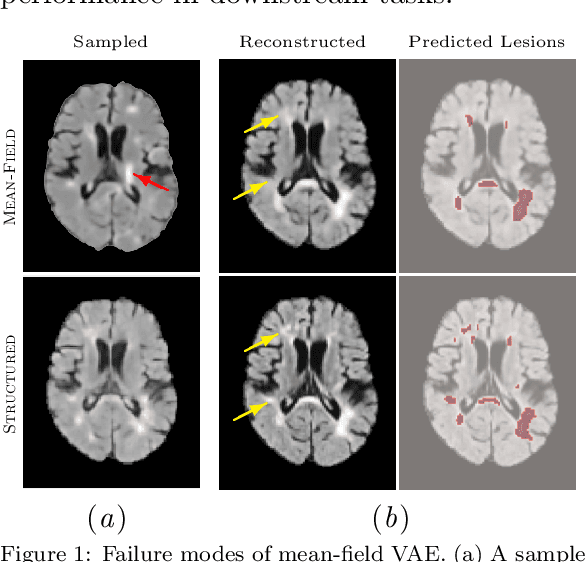

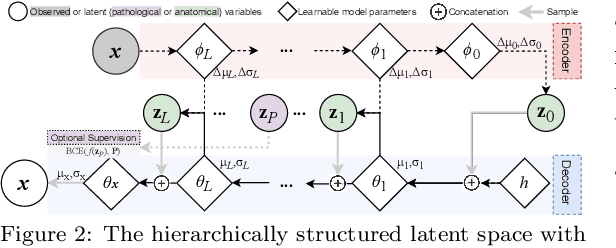
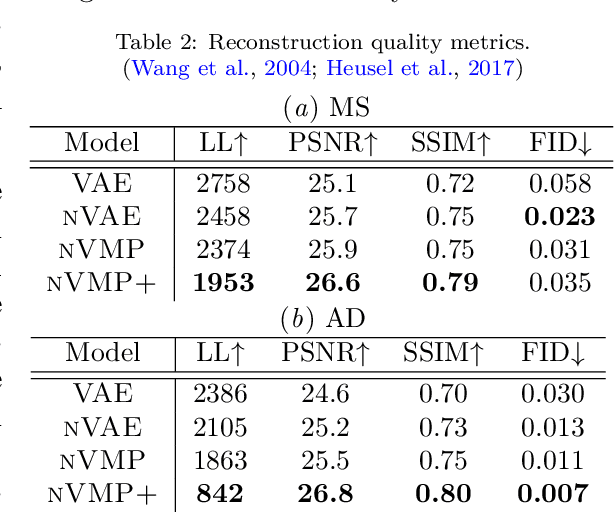
We propose a hierarchically structured variational inference model for accurately disentangling observable evidence of disease (e.g. brain lesions or atrophy) from subject-specific anatomy in brain MRIs. With flexible, partially autoregressive priors, our model (1) addresses the subtle and fine-grained dependencies that typically exist between anatomical and pathological generating factors of an MRI to ensure the clinical validity of generated samples; (2) preserves and disentangles finer pathological details pertaining to a patient's disease state. Additionally, we experiment with an alternative training configuration where we provide supervision to a subset of latent units. It is shown that (1) a partially supervised latent space achieves a higher degree of disentanglement between evidence of disease and subject-specific anatomy; (2) when the prior is formulated with an autoregressive structure, knowledge from the supervision can propagate to the unsupervised latent units, resulting in more informative latent representations capable of modelling anatomy-pathology interdependencies.
On Learning Fairness and Accuracy on Multiple Subgroups
Oct 19, 2022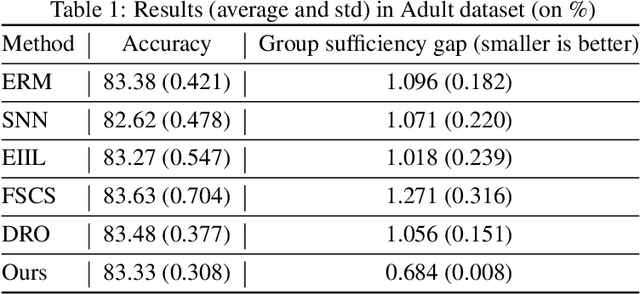
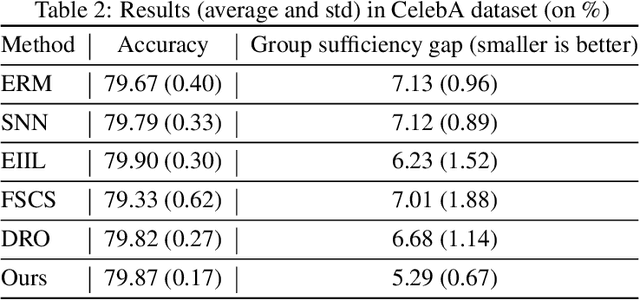
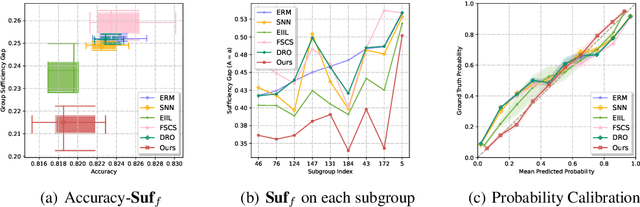
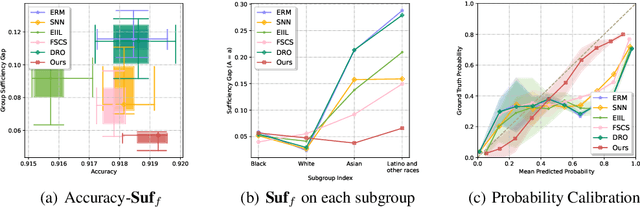
We propose an analysis in fair learning that preserves the utility of the data while reducing prediction disparities under the criteria of group sufficiency. We focus on the scenario where the data contains multiple or even many subgroups, each with limited number of samples. As a result, we present a principled method for learning a fair predictor for all subgroups via formulating it as a bilevel objective. Specifically, the subgroup specific predictors are learned in the lower-level through a small amount of data and the fair predictor. In the upper-level, the fair predictor is updated to be close to all subgroup specific predictors. We further prove that such a bilevel objective can effectively control the group sufficiency and generalization error. We evaluate the proposed framework on real-world datasets. Empirical evidence suggests the consistently improved fair predictions, as well as the comparable accuracy to the baselines.
Information Gain Sampling for Active Learning in Medical Image Classification
Aug 01, 2022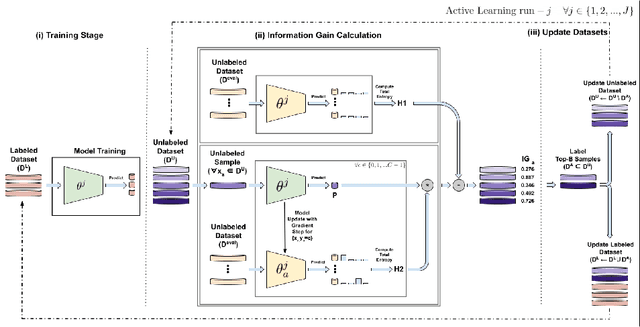
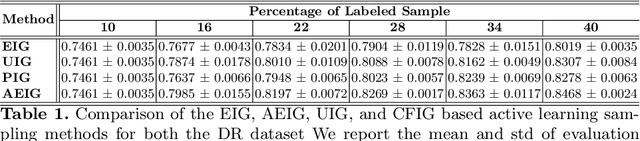
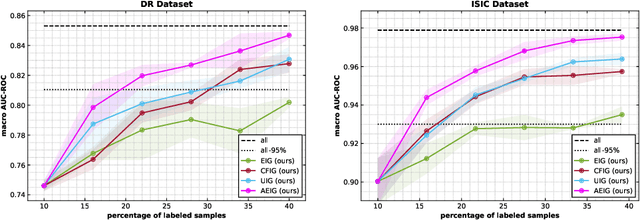
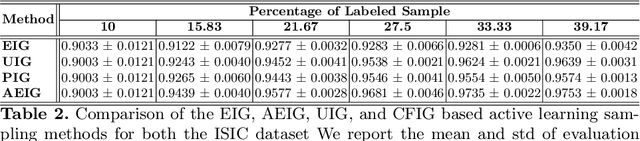
Large, annotated datasets are not widely available in medical image analysis due to the prohibitive time, costs, and challenges associated with labelling large datasets. Unlabelled datasets are easier to obtain, and in many contexts, it would be feasible for an expert to provide labels for a small subset of images. This work presents an information-theoretic active learning framework that guides the optimal selection of images from the unlabelled pool to be labeled based on maximizing the expected information gain (EIG) on an evaluation dataset. Experiments are performed on two different medical image classification datasets: multi-class diabetic retinopathy disease scale classification and multi-class skin lesion classification. Results indicate that by adapting EIG to account for class-imbalances, our proposed Adapted Expected Information Gain (AEIG) outperforms several popular baselines including the diversity based CoreSet and uncertainty based maximum entropy sampling. Specifically, AEIG achieves ~95% of overall performance with only 19% of the training data, while other active learning approaches require around 25%. We show that, by careful design choices, our model can be integrated into existing deep learning classifiers.
Evolving Domain Generalization
Jun 07, 2022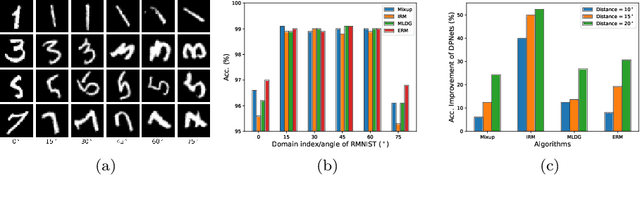
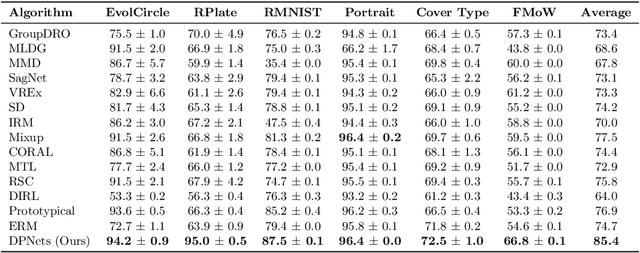


Domain generalization aims to learn a predictive model from multiple different but related source tasks that can generalize well to a target task without the need of accessing any target data. Existing domain generalization methods ignore the relationship between tasks, implicitly assuming that all the tasks are sampled from a stationary environment. Therefore, they can fail when deployed in an evolving environment. To this end, we formulate and study the \emph{evolving domain generalization} (EDG) scenario, which exploits not only the source data but also their evolving pattern to generate a model for the unseen task. Our theoretical result reveals the benefits of modeling the relation between two consecutive tasks by learning a globally consistent directional mapping function. In practice, our analysis also suggests solving the DDG problem in a meta-learning manner, which leads to \emph{directional prototypical network}, the first method for the DDG problem. Empirical evaluation of both synthetic and real-world data sets validates the effectiveness of our approach.