 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Conditional Diffusion Models for Forecasting Future Multiple Sclerosis Lesion Masks Conditioned on Treatments
Aug 09, 2025Image-based personalized medicine has the potential to transform healthcare, particularly for diseases that exhibit heterogeneous progression such as Multiple Sclerosis (MS). In this work, we introduce the first treatment-aware spatio-temporal diffusion model that is able to generate future masks demonstrating lesion evolution in MS. Our voxel-space approach incorporates multi-modal patient data, including MRI and treatment information, to forecast new and enlarging T2 (NET2) lesion masks at a future time point. Extensive experiments on a multi-centre dataset of 2131 patient 3D MRIs from randomized clinical trials for relapsing-remitting MS demonstrate that our generative model is able to accurately predict NET2 lesion masks for patients across six different treatments. Moreover, we demonstrate our model has the potential for real-world clinical applications through downstream tasks such as future lesion count and location estimation, binary lesion activity classification, and generating counterfactual future NET2 masks for several treatments with different efficacies. This work highlights the potential of causal, image-based generative models as powerful tools for advancing data-driven prognostics in MS.
Conditional Diffusion Models are Medical Image Classifiers that Provide Explainability and Uncertainty for Free
Feb 06, 2025



Discriminative classifiers have become a foundational tool in deep learning for medical imaging, excelling at learning separable features of complex data distributions. However, these models often need careful design, augmentation, and training techniques to ensure safe and reliable deployment. Recently, diffusion models have become synonymous with generative modeling in 2D. These models showcase robustness across a range of tasks including natural image classification, where classification is performed by comparing reconstruction errors across images generated for each possible conditioning input. This work presents the first exploration of the potential of class conditional diffusion models for 2D medical image classification. First, we develop a novel majority voting scheme shown to improve the performance of medical diffusion classifiers. Next, extensive experiments on the CheXpert and ISIC Melanoma skin cancer datasets demonstrate that foundation and trained-from-scratch diffusion models achieve competitive performance against SOTA discriminative classifiers without the need for explicit supervision. In addition, we show that diffusion classifiers are intrinsically explainable, and can be used to quantify the uncertainty of their predictions, increasing their trustworthiness and reliability in safety-critical, clinical contexts. Further information is available on our project page: https://faverogian.github.io/med-diffusion-classifier.github.io/
DeCoDEx: Confounder Detector Guidance for Improved Diffusion-based Counterfactual Explanations
May 15, 2024Deep learning classifiers are prone to latching onto dominant confounders present in a dataset rather than on the causal markers associated with the target class, leading to poor generalization and biased predictions. Although explainability via counterfactual image generation has been successful at exposing the problem, bias mitigation strategies that permit accurate explainability in the presence of dominant and diverse artifacts remain unsolved. In this work, we propose the DeCoDEx framework and show how an external, pre-trained binary artifact detector can be leveraged during inference to guide a diffusion-based counterfactual image generator towards accurate explainability. Experiments on the CheXpert dataset, using both synthetic artifacts and real visual artifacts (support devices), show that the proposed method successfully synthesizes the counterfactual images that change the causal pathology markers associated with Pleural Effusion while preserving or ignoring the visual artifacts. Augmentation of ERM and Group-DRO classifiers with the DeCoDEx generated images substantially improves the results across underrepresented groups that are out of distribution for each class. The code is made publicly available at https://github.com/NimaFathi/DeCoDEx.
HyperFusion: A Hypernetwork Approach to Multimodal Integration of Tabular and Medical Imaging Data for Predictive Modeling
Mar 20, 2024



The integration of diverse clinical modalities such as medical imaging and the tabular data obtained by the patients' Electronic Health Records (EHRs) is a crucial aspect of modern healthcare. The integrative analysis of multiple sources can provide a comprehensive understanding of a patient's condition and can enhance diagnoses and treatment decisions. Deep Neural Networks (DNNs) consistently showcase outstanding performance in a wide range of multimodal tasks in the medical domain. However, the complex endeavor of effectively merging medical imaging with clinical, demographic and genetic information represented as numerical tabular data remains a highly active and ongoing research pursuit. We present a novel framework based on hypernetworks to fuse clinical imaging and tabular data by conditioning the image processing on the EHR's values and measurements. This approach aims to leverage the complementary information present in these modalities to enhance the accuracy of various medical applications. We demonstrate the strength and the generality of our method on two different brain Magnetic Resonance Imaging (MRI) analysis tasks, namely, brain age prediction conditioned by subject's sex, and multiclass Alzheimer's Disease (AD) classification conditioned by tabular data. We show that our framework outperforms both single-modality models and state-of-the-art MRI-tabular data fusion methods. The code, enclosed to this manuscript will be made publicly available.
Improving Robustness and Reliability in Medical Image Classification with Latent-Guided Diffusion and Nested-Ensembles
Oct 25, 2023While deep learning models have achieved remarkable success across a range of medical image analysis tasks, deployment of these models in real clinical contexts requires that they be robust to variability in the acquired images. While many methods apply predefined transformations to augment the training data to enhance test-time robustness, these transformations may not ensure the model's robustness to the diverse variability seen in patient images. In this paper, we introduce a novel three-stage approach based on transformers coupled with conditional diffusion models, with the goal of improving model robustness to the kinds of imaging variability commonly encountered in practice without the need for pre-determined data augmentation strategies. To this end, multiple image encoders first learn hierarchical feature representations to build discriminative latent spaces. Next, a reverse diffusion process, guided by the latent code, acts on an informative prior and proposes prediction candidates in a generative manner. Finally, several prediction candidates are aggregated in a bi-level aggregation protocol to produce the final output. Through extensive experiments on medical imaging benchmark datasets, we show that our method improves upon state-of-the-art methods in terms of robustness and confidence calibration. Additionally, we introduce a strategy to quantify the prediction uncertainty at the instance level, increasing their trustworthiness to clinicians using them in clinical practice.
Debiasing Counterfactuals In the Presence of Spurious Correlations
Aug 21, 2023



Deep learning models can perform well in complex medical imaging classification tasks, even when basing their conclusions on spurious correlations (i.e. confounders), should they be prevalent in the training dataset, rather than on the causal image markers of interest. This would thereby limit their ability to generalize across the population. Explainability based on counterfactual image generation can be used to expose the confounders but does not provide a strategy to mitigate the bias. In this work, we introduce the first end-to-end training framework that integrates both (i) popular debiasing classifiers (e.g. distributionally robust optimization (DRO)) to avoid latching onto the spurious correlations and (ii) counterfactual image generation to unveil generalizable imaging markers of relevance to the task. Additionally, we propose a novel metric, Spurious Correlation Latching Score (SCLS), to quantify the extent of the classifier reliance on the spurious correlation as exposed by the counterfactual images. Through comprehensive experiments on two public datasets (with the simulated and real visual artifacts), we demonstrate that the debiasing method: (i) learns generalizable markers across the population, and (ii) successfully ignores spurious correlations and focuses on the underlying disease pathology.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Rethinking Generalization: The Impact of Annotation Style on Medical Image Segmentation
Oct 31, 2022Generalization is an important attribute of machine learning models, particularly for those that are to be deployed in a medical context, where unreliable predictions can have real world consequences. While the failure of models to generalize across datasets is typically attributed to a mismatch in the data distributions, performance gaps are often a consequence of biases in the ``ground-truth" label annotations. This is particularly important in the context of medical image segmentation of pathological structures (e.g. lesions), where the annotation process is much more subjective, and affected by a number underlying factors, including the annotation protocol, rater education/experience, and clinical aims, among others. In this paper, we show that modeling annotation biases, rather than ignoring them, poses a promising way of accounting for differences in annotation style across datasets. To this end, we propose a generalized conditioning framework to (1) learn and account for different annotation styles across multiple datasets using a single model, (2) identify similar annotation styles across different datasets in order to permit their effective aggregation, and (3) fine-tune a fully trained model to a new annotation style with just a few samples. Next, we present an image-conditioning approach to model annotation styles that correlate with specific image features, potentially enabling detection biases to be more easily identified.
Counterfactual Image Synthesis for Discovery of Personalized Predictive Image Markers
Aug 03, 2022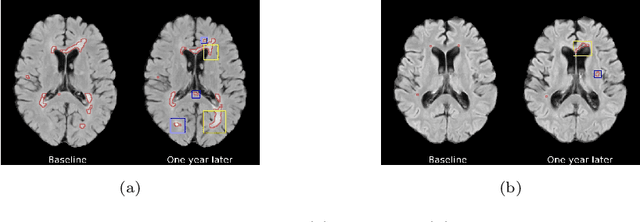

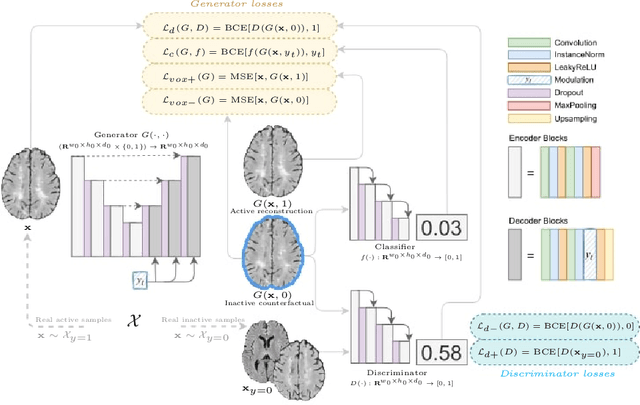

The discovery of patient-specific imaging markers that are predictive of future disease outcomes can help us better understand individual-level heterogeneity of disease evolution. In fact, deep learning models that can provide data-driven personalized markers are much more likely to be adopted in medical practice. In this work, we demonstrate that data-driven biomarker discovery can be achieved through a counterfactual synthesis process. We show how a deep conditional generative model can be used to perturb local imaging features in baseline images that are pertinent to subject-specific future disease evolution and result in a counterfactual image that is expected to have a different future outcome. Candidate biomarkers, therefore, result from examining the set of features that are perturbed in this process. Through several experiments on a large-scale, multi-scanner, multi-center multiple sclerosis (MS) clinical trial magnetic resonance imaging (MRI) dataset of relapsing-remitting (RRMS) patients, we demonstrate that our model produces counterfactuals with changes in imaging features that reflect established clinical markers predictive of future MRI lesional activity at the population level. Additional qualitative results illustrate that our model has the potential to discover novel and subject-specific predictive markers of future activity.