 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIM1: Physics-Aligned Simulator as Zero-Shot Data Scaler in Deformable Worlds
Apr 09, 2026Robotic manipulation with deformable objects represents a data-intensive regime in embodied learning, where shape, contact, and topology co-evolve in ways that far exceed the variability of rigids. Although simulation promises relief from the cost of real-world data acquisition, prevailing sim-to-real pipelines remain rooted in rigid-body abstractions, producing mismatched geometry, fragile soft dynamics, and motion primitives poorly suited for cloth interaction. We posit that simulation fails not for being synthetic, but for being ungrounded. To address this, we introduce SIM1, a physics-aligned real-to-sim-to-real data engine that grounds simulation in the physical world. Given limited demonstrations, the system digitizes scenes into metric-consistent twins, calibrates deformable dynamics through elastic modeling, and expands behaviors via diffusion-based trajectory generation with quality filtering. This pipeline transforms sparse observations into scaled synthetic supervision with near-demonstration fidelity. Experiments show that policies trained on purely synthetic data achieve parity with real-data baselines at a 1:15 equivalence ratio, while delivering 90% zero-shot success and 50% generalization gains in real-world deployment. These results validate physics-aligned simulation as scalable supervision for deformable manipulation and a practical pathway for data-efficient policy learning.
Tac2Real: Reliable and GPU Visuotactile Simulation for Online Reinforcement Learning and Zero-Shot Real-World Deployment
Mar 30, 2026Visuotactile sensors are indispensable for contact-rich robotic manipulation tasks. However, policy learning with tactile feedback in simulation, especially for online reinforcement learning (RL), remains a critical challenge, as it demands a delicate balance between physics fidelity and computational efficiency. To address this challenge, we present Tac2Real, a lightweight visuotactile simulation framework designed to enable efficient online RL training. Tac2Real integrates the Preconditioned Nonlinear Conjugate Gradient Incremental Potential Contact (PNCG-IPC) method with a multi-node, multi-GPU high-throughput parallel simulation architecture, which can generate marker displacement fields at interactive rates. Meanwhile, we propose a systematic approach, TacAlign, to narrow both structured and stochastic sources of domain gap, ensuring a reliable zero-shot sim-to-real transfer. We further evaluate Tac2Real on the contact-rich peg insertion task. The zero-shot transfer results achieve a high success rate in the real-world scenario, verifying the effectiveness and robustness of our framework. The project page is: https://ningyurichard.github.io/tac2real-project-page/
Verbalized Probabilistic Graphical Modeling with Large Language Models
Jun 08, 2024Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
Improving Robustness and Reliability in Medical Image Classification with Latent-Guided Diffusion and Nested-Ensembles
Oct 25, 2023While deep learning models have achieved remarkable success across a range of medical image analysis tasks, deployment of these models in real clinical contexts requires that they be robust to variability in the acquired images. While many methods apply predefined transformations to augment the training data to enhance test-time robustness, these transformations may not ensure the model's robustness to the diverse variability seen in patient images. In this paper, we introduce a novel three-stage approach based on transformers coupled with conditional diffusion models, with the goal of improving model robustness to the kinds of imaging variability commonly encountered in practice without the need for pre-determined data augmentation strategies. To this end, multiple image encoders first learn hierarchical feature representations to build discriminative latent spaces. Next, a reverse diffusion process, guided by the latent code, acts on an informative prior and proposes prediction candidates in a generative manner. Finally, several prediction candidates are aggregated in a bi-level aggregation protocol to produce the final output. Through extensive experiments on medical imaging benchmark datasets, we show that our method improves upon state-of-the-art methods in terms of robustness and confidence calibration. Additionally, we introduce a strategy to quantify the prediction uncertainty at the instance level, increasing their trustworthiness to clinicians using them in clinical practice.
DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation
Nov 19, 2020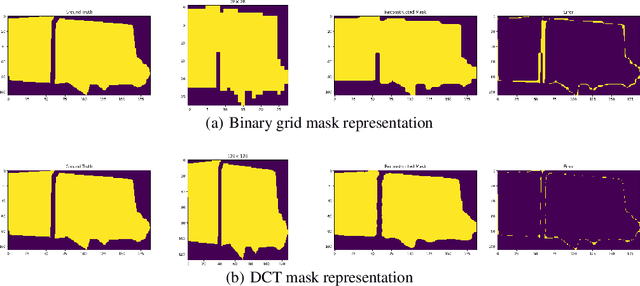
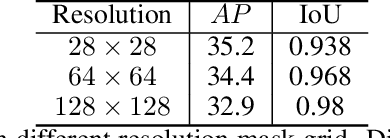
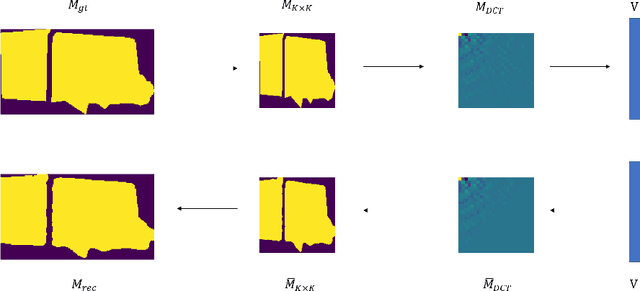
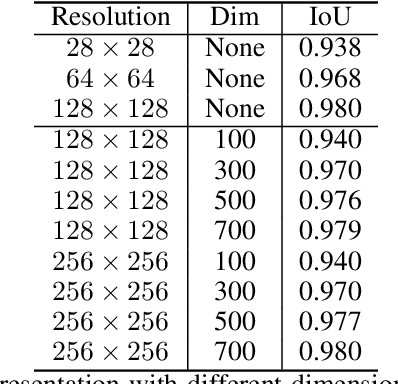
Binary grid mask representation is broadly used in instance segmentation. A representative instantiation is Mask R-CNN which predicts masks on a $28\times 28$ binary grid. Generally, a low-resolution grid is not sufficient to capture the details, while a high-resolution grid dramatically increases the training complexity. In this paper, we propose a new mask representation by applying the discrete cosine transform(DCT) to encode the high-resolution binary grid mask into a compact vector. Our method, termed DCT-Mask, could be easily integrated into most pixel-based instance segmentation methods. Without any bells and whistles, DCT-Mask yields significant gains on different frameworks, backbones, datasets, and training schedules. It does not require any pre-processing or pre-training, and almost no harm to the running speed. Especially, for higher-quality annotations and more complex backbones, our method has a greater improvement. Moreover, we analyze the performance of our method from the perspective of the quality of mask representation. The main reason why DCT-Mask works well is that it obtains a high-quality mask representation with low complexity. Code will be made available.