 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Graph Convolution Network for Pose Forecasting
Apr 11, 2023


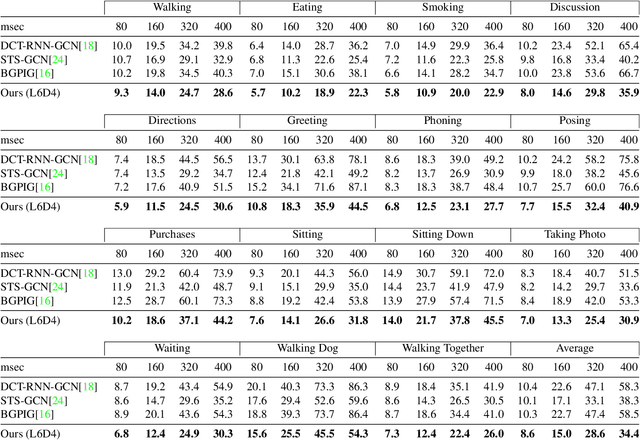
Recently, there has been a growing interest in predicting human motion, which involves forecasting future body poses based on observed pose sequences. This task is complex due to modeling spatial and temporal relationships. The most commonly used models for this task are autoregressive models, such as recurrent neural networks (RNNs) or variants, and Transformer Networks. However, RNNs have several drawbacks, such as vanishing or exploding gradients. Other researchers have attempted to solve the communication problem in the spatial dimension by integrating Graph Convolutional Networks (GCN) and Long Short-Term Memory (LSTM) models. These works deal with temporal and spatial information separately, which limits the effectiveness. To fix this problem, we propose a novel approach called the multi-graph convolution network (MGCN) for 3D human pose forecasting. This model simultaneously captures spatial and temporal information by introducing an augmented graph for pose sequences. Multiple frames give multiple parts, joined together in a single graph instance. Furthermore, we also explore the influence of natural structure and sequence-aware attention to our model. In our experimental evaluation of the large-scale benchmark datasets, Human3.6M, AMSS and 3DPW, MGCN outperforms the state-of-the-art in pose prediction.
PatchDCT: Patch Refinement for High Quality Instance Segmentation
Feb 07, 2023
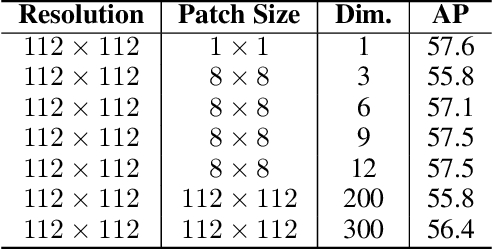
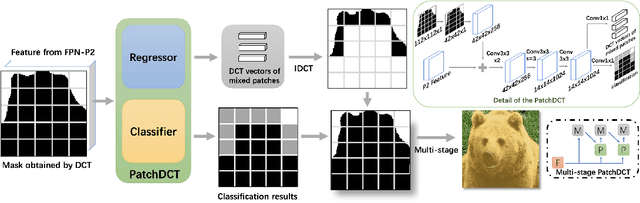
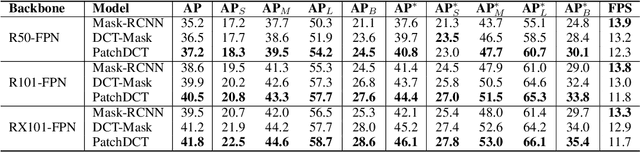
High-quality instance segmentation has shown emerging importance in computer vision. Without any refinement, DCT-Mask directly generates high-resolution masks by compressed vectors. To further refine masks obtained by compressed vectors, we propose for the first time a compressed vector based multi-stage refinement framework. However, the vanilla combination does not bring significant gains, because changes in some elements of the DCT vector will affect the prediction of the entire mask. Thus, we propose a simple and novel method named PatchDCT, which separates the mask decoded from a DCT vector into several patches and refines each patch by the designed classifier and regressor. Specifically, the classifier is used to distinguish mixed patches from all patches, and to correct previously mispredicted foreground and background patches. In contrast, the regressor is used for DCT vector prediction of mixed patches, further refining the segmentation quality at boundary locations. Experiments on COCO show that our method achieves 2.0%, 3.2%, 4.5% AP and 3.4%, 5.3%, 7.0% Boundary AP improvements over Mask-RCNN on COCO, LVIS, and Cityscapes, respectively. It also surpasses DCT-Mask by 0.7%, 1.1%, 1.3% AP and 0.9%, 1.7%, 4.2% Boundary AP on COCO, LVIS and Cityscapes. Besides, the performance of PatchDCT is also competitive with other state-of-the-art methods.
DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation
Nov 19, 2020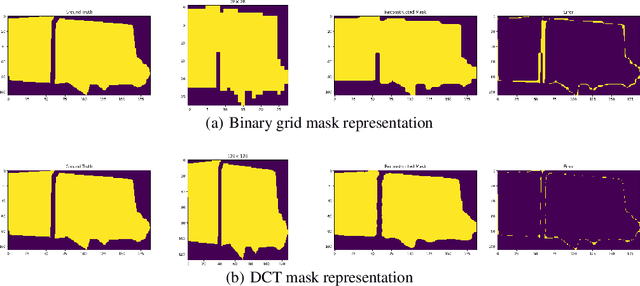
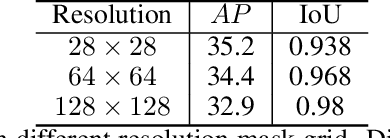
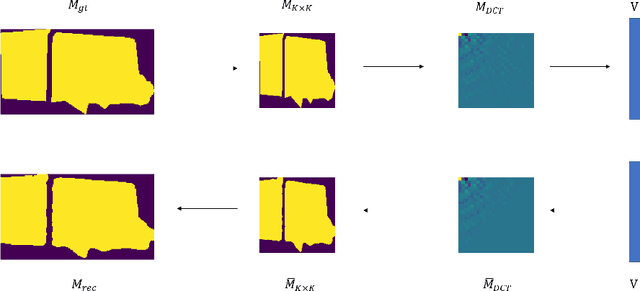
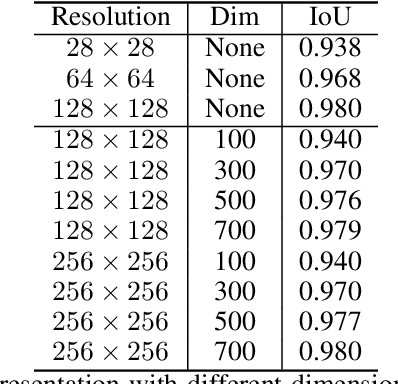
Binary grid mask representation is broadly used in instance segmentation. A representative instantiation is Mask R-CNN which predicts masks on a $28\times 28$ binary grid. Generally, a low-resolution grid is not sufficient to capture the details, while a high-resolution grid dramatically increases the training complexity. In this paper, we propose a new mask representation by applying the discrete cosine transform(DCT) to encode the high-resolution binary grid mask into a compact vector. Our method, termed DCT-Mask, could be easily integrated into most pixel-based instance segmentation methods. Without any bells and whistles, DCT-Mask yields significant gains on different frameworks, backbones, datasets, and training schedules. It does not require any pre-processing or pre-training, and almost no harm to the running speed. Especially, for higher-quality annotations and more complex backbones, our method has a greater improvement. Moreover, we analyze the performance of our method from the perspective of the quality of mask representation. The main reason why DCT-Mask works well is that it obtains a high-quality mask representation with low complexity. Code will be made available.
FGAGT: Flow-Guided Adaptive Graph Tracking
Nov 04, 2020
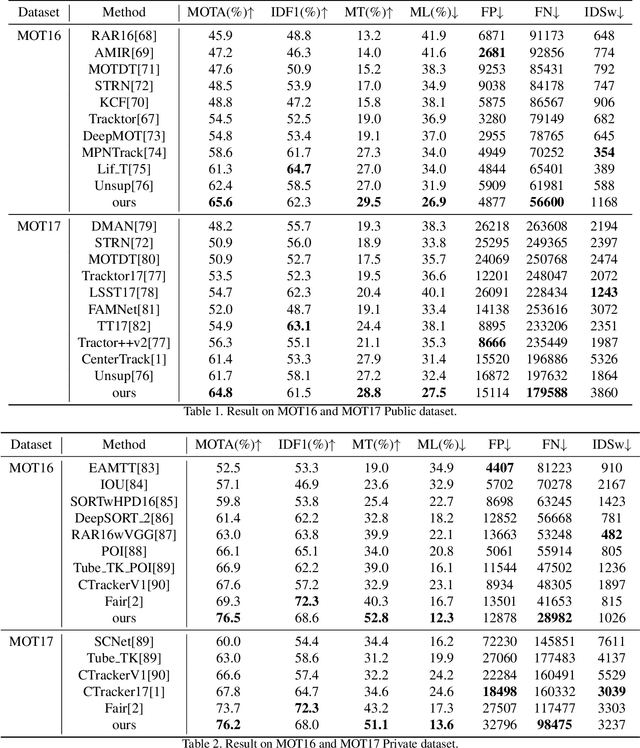
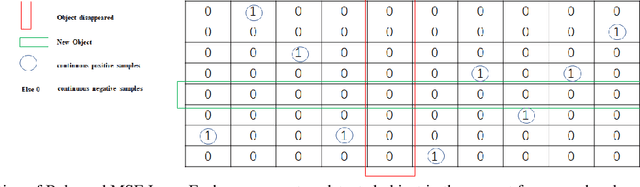
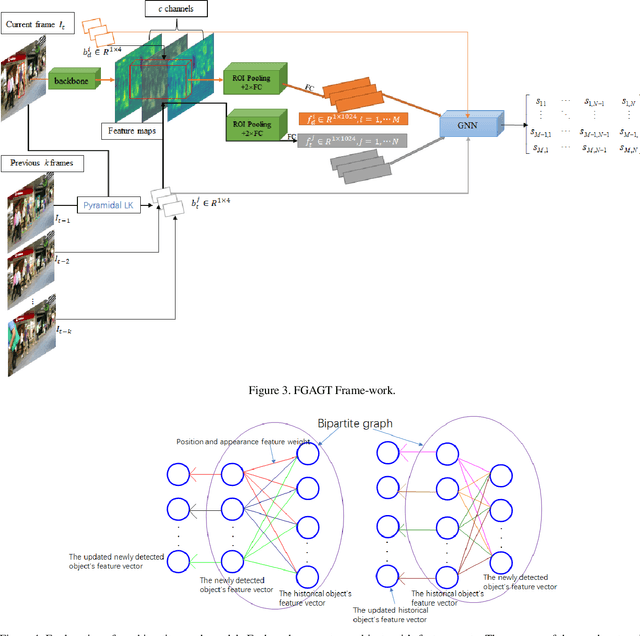
Most previous tracking methods usually use the optical flow method to estimate the position of the historical object in the current frame and then use the linear combination of feature similarity and IOU(Intersection over Union) to perform association matching near the position. However, the features used in these methods are not aligned, i.e., the features of the historical objects are extracted from the historical feature maps, not from the current frame, even the same object may undergo posture, angle, etc. changes during the movement, and even light intensity changes. In addition, most methods only use the appearance information when extracting the feature vector, not the position relationship, nor the feature information of the historical object, so the information is not fully utilized. In order to solve the above problems, we proposed the FGAGT tracker, which uses the optical flow method to predict the center position of the historical object in the current frame and extract the feature vector, so that the feature of the historical object can be aligned with the feature of the object in the current frame. Then these features are input into the graph neural network, and the global Spatio-temporal position and appearance information are integrated to update the feature vectors of all objects. In the training phase, we propose the Balanced MSE LOSS to balance the sample distribution for data association. Experiments show that our method reaches the level of state-of-the-art, where the MOTA index exceeds FairMOT by 2.5 points, and CenterTrack by 8.4 points on the MOT17 dataset, exceeds FairMOT by 1.6 points on the MOT16 dataset. Code will be avaliable.