 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Graph Convolution Network for Pose Forecasting
Paper and Code
Apr 11, 2023


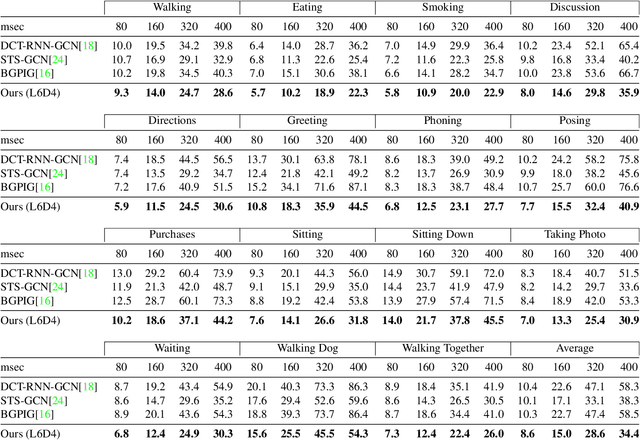
Recently, there has been a growing interest in predicting human motion, which involves forecasting future body poses based on observed pose sequences. This task is complex due to modeling spatial and temporal relationships. The most commonly used models for this task are autoregressive models, such as recurrent neural networks (RNNs) or variants, and Transformer Networks. However, RNNs have several drawbacks, such as vanishing or exploding gradients. Other researchers have attempted to solve the communication problem in the spatial dimension by integrating Graph Convolutional Networks (GCN) and Long Short-Term Memory (LSTM) models. These works deal with temporal and spatial information separately, which limits the effectiveness. To fix this problem, we propose a novel approach called the multi-graph convolution network (MGCN) for 3D human pose forecasting. This model simultaneously captures spatial and temporal information by introducing an augmented graph for pose sequences. Multiple frames give multiple parts, joined together in a single graph instance. Furthermore, we also explore the influence of natural structure and sequence-aware attention to our model. In our experimental evaluation of the large-scale benchmark datasets, Human3.6M, AMSS and 3DPW, MGCN outperforms the state-of-the-art in pose prediction.