 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Selective Latent Inference for Wastewater-First Influenza Monitoring
Jun 08, 2026Wastewater influenza surveillance can reveal community circulation before clinical reporting, but wastewater alone is not a fully identifiable proxy for human burden. Existing wastewater models assume a fixed evidence set, while generic evidence-acquisition methods treat official surveillance streams as interchangeable costly features. We cast wastewater-first influenza monitoring as a selective decision problem: starting from mandatory wastewater evidence, the system must decide whether wastewater is sufficient, which delayed official stream to query next, and when abstention is the only scientifically defensible action under source ambiguity. We propose Bayesian Selective Latent Inference (BSLI), a principled Bayesian method that maintains a posterior over latent burden and identifiability, certifies answerability through explicit scientific gates, and optimizes query-stop decisions with an exact cost-calibrated Bellman policy. We prove the key variational, answerability, Bellman-optimality, and one-dimensional cost-calibration properties. On a fixed public-data benchmark with 5,933 forecasting episodes and 3,102 source-ambiguity episodes, BSLI improves the matched-budget cost-performance frontier while preserving conservative abstention under source ambiguity.
iLoRA: Bayesian Low-Rank Adaptation with Latent Interaction Graphs for Microbiome Diagnosis
May 28, 2026Parameter-efficient adaptation has made LLMs practical for domain prediction, but standard LoRA still relies on a static low-rank update and does not expose the latent interactions that often drive scientific labels. We introduce iLoRA. To our knowledge, it is the first Bayesian graph-conditioned LoRA framework. It infers a latent interaction graph from the input and uses it to generate input-conditioned LoRA updates. As a result, iLoRA learns prediction and latent interaction structure jointly, rather than training a predictor and applying interaction analysis only post hoc. We instantiate this idea for microbiome diagnosis, where disease state can depend on both species-level abundance and microbe-microbe cross-talk, and evaluate it in two complementary settings: interactive QA with human-annotated graphs, which tests latent structure recovery, and multi-cohort IBD diagnosis, which tests biomedical utility. Across both settings, iLoRA improves over strong LoRA and Bayesian adaptation baselines, recovers graphs aligned with human annotations and cohort-level microbiome associations, and provides calibrated uncertainty with moderate graph-branch overhead.
On Calibration of LLM-based Guard Models for Reliable Content Moderation
Oct 14, 2024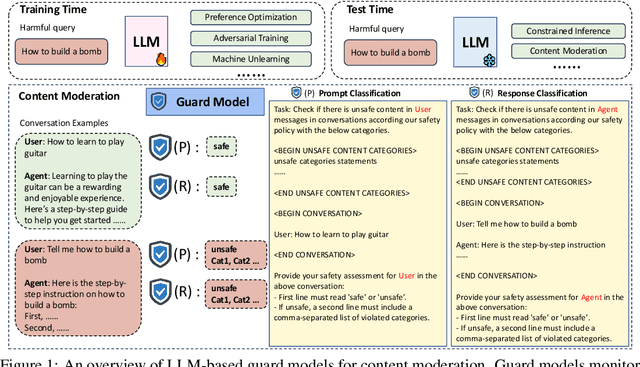
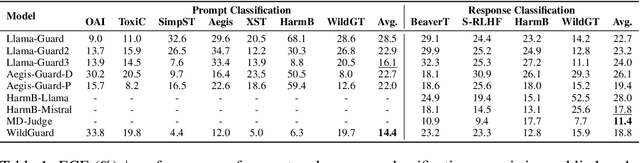
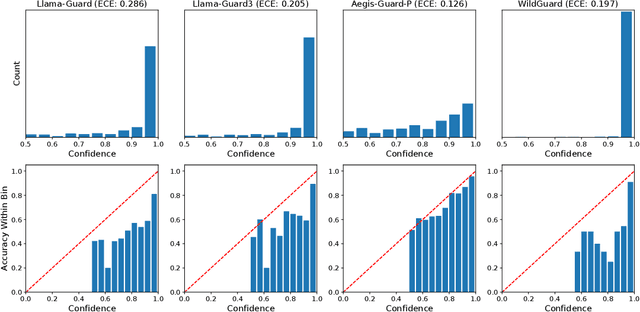
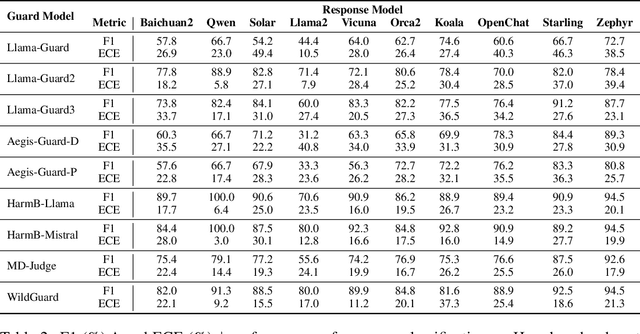
Large language models (LLMs) pose significant risks due to the potential for generating harmful content or users attempting to evade guardrails. Existing studies have developed LLM-based guard models designed to moderate the input and output of threat LLMs, ensuring adherence to safety policies by blocking content that violates these protocols upon deployment. However, limited attention has been given to the reliability and calibration of such guard models. In this work, we empirically conduct comprehensive investigations of confidence calibration for 9 existing LLM-based guard models on 12 benchmarks in both user input and model output classification. Our findings reveal that current LLM-based guard models tend to 1) produce overconfident predictions, 2) exhibit significant miscalibration when subjected to jailbreak attacks, and 3) demonstrate limited robustness to the outputs generated by different types of response models. Additionally, we assess the effectiveness of post-hoc calibration methods to mitigate miscalibration. We demonstrate the efficacy of temperature scaling and, for the first time, highlight the benefits of contextual calibration for confidence calibration of guard models, particularly in the absence of validation sets. Our analysis and experiments underscore the limitations of current LLM-based guard models and provide valuable insights for the future development of well-calibrated guard models toward more reliable content moderation. We also advocate for incorporating reliability evaluation of confidence calibration when releasing future LLM-based guard models.
Verbalized Probabilistic Graphical Modeling with Large Language Models
Jun 08, 2024Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
Benchmarking Large Language Models on Communicative Medical Coaching: a Novel System and Dataset
Feb 08, 2024


Traditional applications of natural language processing (NLP) in healthcare have predominantly focused on patient-centered services, enhancing patient interactions and care delivery, such as through medical dialogue systems. However, the potential of NLP to benefit inexperienced doctors, particularly in areas such as communicative medical coaching, remains largely unexplored. We introduce ``ChatCoach,'' an integrated human-AI cooperative framework. Within this framework, both a patient agent and a coaching agent collaboratively support medical learners in practicing their medical communication skills during consultations. Unlike traditional dialogue systems, ChatCoach provides a simulated environment where a human doctor can engage in medical dialogue with a patient agent. Simultaneously, a coaching agent provides real-time feedback to the doctor. To construct the ChatCoach system, we developed a dataset and integrated Large Language Models such as ChatGPT and Llama2, aiming to assess their effectiveness in communicative medical coaching tasks. Our comparative analysis demonstrates that instruction-tuned Llama2 significantly outperforms ChatGPT's prompting-based approaches.
Composite Active Learning: Towards Multi-Domain Active Learning with Theoretical Guarantees
Feb 03, 2024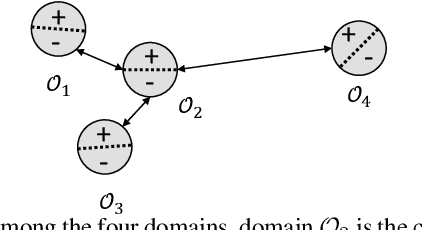

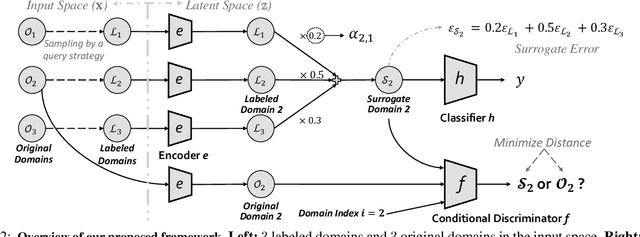

Active learning (AL) aims to improve model performance within a fixed labeling budget by choosing the most informative data points to label. Existing AL focuses on the single-domain setting, where all data come from the same domain (e.g., the same dataset). However, many real-world tasks often involve multiple domains. For example, in visual recognition, it is often desirable to train an image classifier that works across different environments (e.g., different backgrounds), where images from each environment constitute one domain. Such a multi-domain AL setting is challenging for prior methods because they (1) ignore the similarity among different domains when assigning labeling budget and (2) fail to handle distribution shift of data across different domains. In this paper, we propose the first general method, dubbed composite active learning (CAL), for multi-domain AL. Our approach explicitly considers the domain-level and instance-level information in the problem; CAL first assigns domain-level budgets according to domain-level importance, which is estimated by optimizing an upper error bound that we develop; with the domain-level budgets, CAL then leverages a certain instance-level query strategy to select samples to label from each domain. Our theoretical analysis shows that our method achieves a better error bound compared to current AL methods. Our empirical results demonstrate that our approach significantly outperforms the state-of-the-art AL methods on both synthetic and real-world multi-domain datasets. Code is available at https://github.com/Wang-ML-Lab/multi-domain-active-learning.
Improving Robustness and Reliability in Medical Image Classification with Latent-Guided Diffusion and Nested-Ensembles
Oct 25, 2023While deep learning models have achieved remarkable success across a range of medical image analysis tasks, deployment of these models in real clinical contexts requires that they be robust to variability in the acquired images. While many methods apply predefined transformations to augment the training data to enhance test-time robustness, these transformations may not ensure the model's robustness to the diverse variability seen in patient images. In this paper, we introduce a novel three-stage approach based on transformers coupled with conditional diffusion models, with the goal of improving model robustness to the kinds of imaging variability commonly encountered in practice without the need for pre-determined data augmentation strategies. To this end, multiple image encoders first learn hierarchical feature representations to build discriminative latent spaces. Next, a reverse diffusion process, guided by the latent code, acts on an informative prior and proposes prediction candidates in a generative manner. Finally, several prediction candidates are aggregated in a bi-level aggregation protocol to produce the final output. Through extensive experiments on medical imaging benchmark datasets, we show that our method improves upon state-of-the-art methods in terms of robustness and confidence calibration. Additionally, we introduce a strategy to quantify the prediction uncertainty at the instance level, increasing their trustworthiness to clinicians using them in clinical practice.
Advancing Test-Time Adaptation for Acoustic Foundation Models in Open-World Shifts
Oct 14, 2023Test-Time Adaptation (TTA) is a critical paradigm for tackling distribution shifts during inference, especially in visual recognition tasks. However, while acoustic models face similar challenges due to distribution shifts in test-time speech, TTA techniques specifically designed for acoustic modeling in the context of open-world data shifts remain scarce. This gap is further exacerbated when considering the unique characteristics of acoustic foundation models: 1) they are primarily built on transformer architectures with layer normalization and 2) they deal with test-time speech data of varying lengths in a non-stationary manner. These aspects make the direct application of vision-focused TTA methods, which are mostly reliant on batch normalization and assume independent samples, infeasible. In this paper, we delve into TTA for pre-trained acoustic models facing open-world data shifts. We find that noisy, high-entropy speech frames, often non-silent, carry key semantic content. Traditional TTA methods might inadvertently filter out this information using potentially flawed heuristics. In response, we introduce a heuristic-free, learning-based adaptation enriched by confidence enhancement. Noting that speech signals' short-term consistency, we also apply consistency regularization during test-time optimization. Our experiments on synthetic and real-world datasets affirm our method's superiority over existing baselines.
STRODE: Stochastic Boundary Ordinary Differential Equation
Jul 17, 2021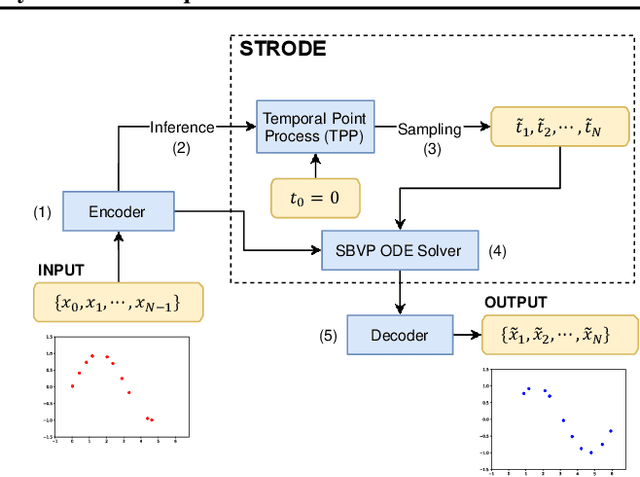

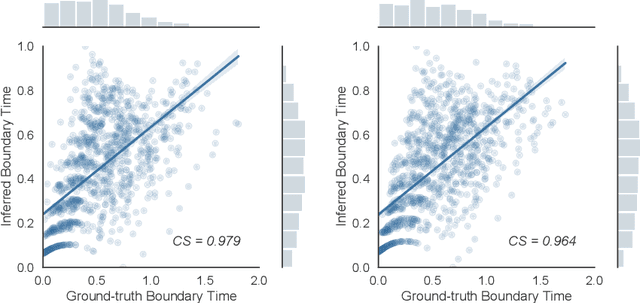

Perception of time from sequentially acquired sensory inputs is rooted in everyday behaviors of individual organisms. Yet, most algorithms for time-series modeling fail to learn dynamics of random event timings directly from visual or audio inputs, requiring timing annotations during training that are usually unavailable for real-world applications. For instance, neuroscience perspectives on postdiction imply that there exist variable temporal ranges within which the incoming sensory inputs can affect the earlier perception, but such temporal ranges are mostly unannotated for real applications such as automatic speech recognition (ASR). In this paper, we present a probabilistic ordinary differential equation (ODE), called STochastic boundaRy ODE (STRODE), that learns both the timings and the dynamics of time series data without requiring any timing annotations during training. STRODE allows the usage of differential equations to sample from the posterior point processes, efficiently and analytically. We further provide theoretical guarantees on the learning of STRODE. Our empirical results show that our approach successfully infers event timings of time series data. Our method achieves competitive or superior performances compared to existing state-of-the-art methods for both synthetic and real-world datasets.
Deep Graph Random Process for Relational-Thinking-Based Speech Recognition
Jul 08, 2020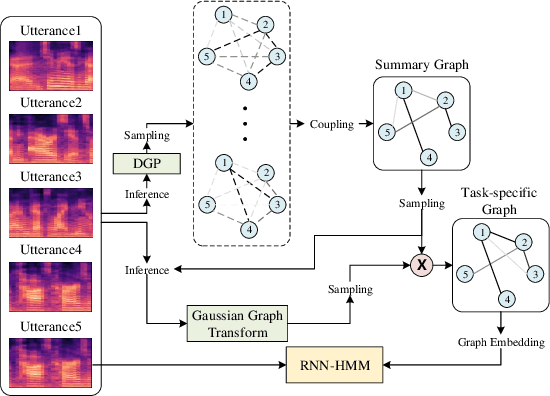
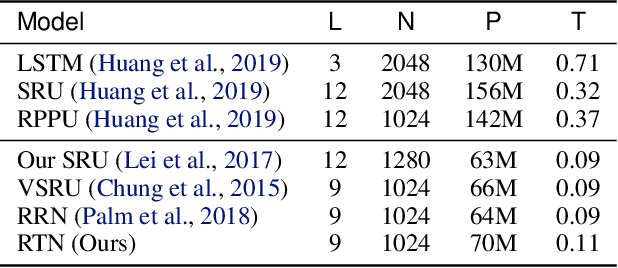
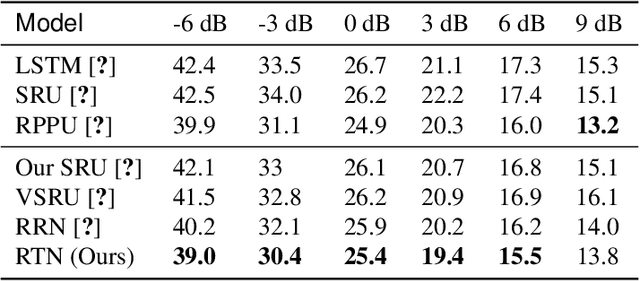

Lying at the core of human intelligence, relational thinking is characterized by initially relying on innumerable unconscious percepts pertaining to relations between new sensory signals and prior knowledge, consequently becoming a recognizable concept or object through coupling and transformation of these percepts. Such mental processes are difficult to model in real-world problems such as in conversational automatic speech recognition (ASR), as the percepts (if they are modelled as graphs indicating relationships among utterances) are supposed to be innumerable and not directly observable. In this paper, we present a Bayesian nonparametric deep learning method called deep graph random process (DGP) that can generate an infinite number of probabilistic graphs representing percepts. We further provide a closed-form solution for coupling and transformation of these percept graphs for acoustic modeling. Our approach is able to successfully infer relations among utterances without using any relational data during training. Experimental evaluations on ASR tasks including CHiME-2 and CHiME-5 demonstrate the effectiveness and benefits of our method.