 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
Feb 07, 2025We introduce Quantized Language-Image Pretraining (QLIP), a visual tokenization method that combines state-of-the-art reconstruction quality with state-of-the-art zero-shot image understanding. QLIP trains a binary-spherical-quantization-based autoencoder with reconstruction and language-image alignment objectives. We are the first to show that the two objectives do not need to be at odds. We balance the two loss terms dynamically during training and show that a two-stage training pipeline effectively mixes the large-batch requirements of image-language pre-training with the memory bottleneck imposed by the reconstruction objective. We validate the effectiveness of QLIP for multimodal understanding and text-conditioned image generation with a single model. Specifically, QLIP serves as a drop-in replacement for the visual encoder for LLaVA and the image tokenizer for LlamaGen with comparable or even better performance. Finally, we demonstrate that QLIP enables a unified mixed-modality auto-regressive model for understanding and generation.
Boosting LLM via Learning from Data Iteratively and Selectively
Dec 23, 2024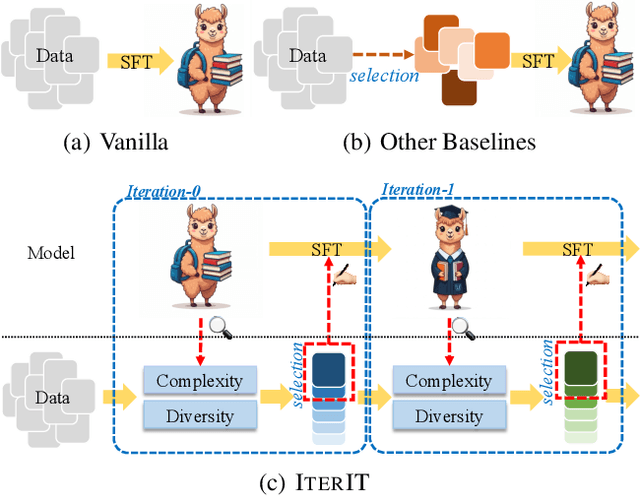
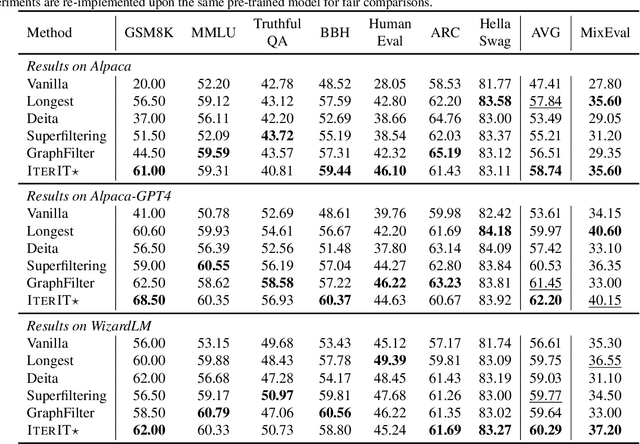
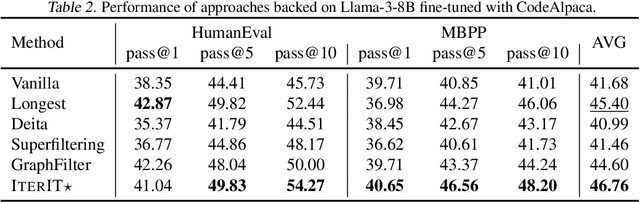
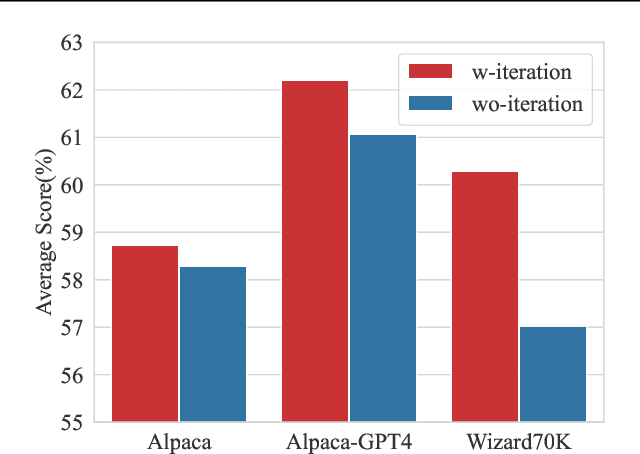
Datasets nowadays are generally constructed from multiple sources and using different synthetic techniques, making data de-noising and de-duplication crucial before being used for post-training. In this work, we propose to perform instruction tuning by iterative data selection (\ApproachName{}). We measure the quality of a sample from complexity and diversity simultaneously. Instead of calculating the complexity score once for all before fine-tuning, we highlight the importance of updating this model-specific score during fine-tuning to accurately accommodate the dynamic changes of the model. On the other hand, the diversity score is defined on top of the samples' responses under the consideration of their informativeness. IterIT integrates the strengths of both worlds by iteratively updating the complexity score for the top-ranked samples and greedily selecting the ones with the highest complexity-diversity score. Experiments on multiple instruction-tuning data demonstrate consistent improvements of IterIT over strong baselines. Moreover, our approach also generalizes well to domain-specific scenarios and different backbone models. All resources will be available at https://github.com/JiaQiSJTU/IterIT.
MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures
Oct 17, 2024



Perceiving and generating diverse modalities are crucial for AI models to effectively learn from and engage with real-world signals, necessitating reliable evaluations for their development. We identify two major issues in current evaluations: (1) inconsistent standards, shaped by different communities with varying protocols and maturity levels; and (2) significant query, grading, and generalization biases. To address these, we introduce MixEval-X, the first any-to-any real-world benchmark designed to optimize and standardize evaluations across input and output modalities. We propose multi-modal benchmark mixture and adaptation-rectification pipelines to reconstruct real-world task distributions, ensuring evaluations generalize effectively to real-world use cases. Extensive meta-evaluations show our approach effectively aligns benchmark samples with real-world task distributions and the model rankings correlate strongly with that of crowd-sourced real-world evaluations (up to 0.98). We provide comprehensive leaderboards to rerank existing models and organizations and offer insights to enhance understanding of multi-modal evaluations and inform future research.
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Aug 21, 2024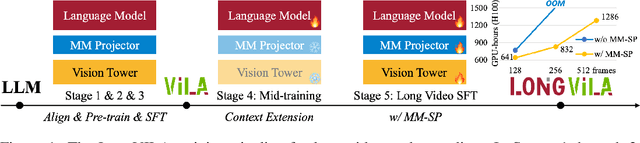

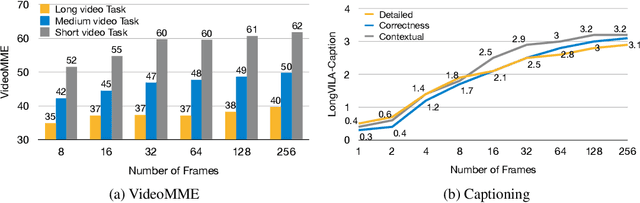
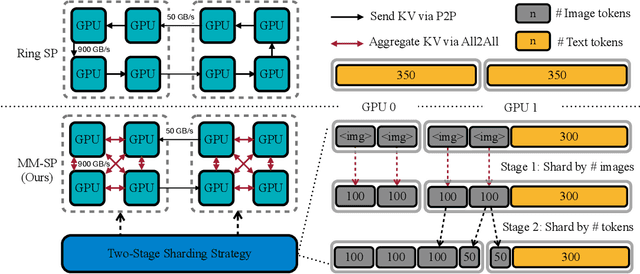
Long-context capability is critical for multi-modal foundation models, especially for long video understanding. We introduce LongVILA, a full-stack solution for long-context visual-language models by co-designing the algorithm and system. For model training, we upgrade existing VLMs to support long video understanding by incorporating two additional stages, i.e., long context extension and long supervised fine-tuning. However, training on long video is computationally and memory intensive. We introduce the long-context Multi-Modal Sequence Parallelism (MM-SP) system that efficiently parallelizes long video training and inference, enabling 2M context length training on 256 GPUs without any gradient checkpointing. LongVILA efficiently extends the number of video frames of VILA from 8 to 1024, improving the long video captioning score from 2.00 to 3.26 (out of 5), achieving 99.5% accuracy in 1400-frame (274k context length) video needle-in-a-haystack. LongVILA-8B demonstrates consistent accuracy improvements on long videos in the VideoMME benchmark as the number of frames increases. Besides, MM-SP is 2.1x - 5.7x faster than ring sequence parallelism and 1.1x - 1.4x faster than Megatron with context parallelism + tensor parallelism. Moreover, it seamlessly integrates with Hugging Face Transformers.
Wolf: Captioning Everything with a World Summarization Framework
Jul 26, 2024



We propose Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf is an automated captioning framework that adopts a mixture-of-experts approach, leveraging complementary strengths of Vision Language Models (VLMs). By utilizing both image and video models, our framework captures different levels of information and summarizes them efficiently. Our approach can be applied to enhance video understanding, auto-labeling, and captioning. To evaluate caption quality, we introduce CapScore, an LLM-based metric to assess the similarity and quality of generated captions compared to the ground truth captions. We further build four human-annotated datasets in three domains: autonomous driving, general scenes, and robotics, to facilitate comprehensive comparisons. We show that Wolf achieves superior captioning performance compared to state-of-the-art approaches from the research community (VILA1.5, CogAgent) and commercial solutions (Gemini-Pro-1.5, GPT-4V). For instance, in comparison with GPT-4V, Wolf improves CapScore both quality-wise by 55.6% and similarity-wise by 77.4% on challenging driving videos. Finally, we establish a benchmark for video captioning and introduce a leaderboard, aiming to accelerate advancements in video understanding, captioning, and data alignment. Leaderboard: https://wolfv0.github.io/leaderboard.html.
MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures
Jun 03, 2024



Evaluating large language models (LLMs) is challenging. Traditional ground-truth-based benchmarks fail to capture the comprehensiveness and nuance of real-world queries, while LLM-as-judge benchmarks suffer from grading biases and limited query quantity. Both of them may also become contaminated over time. User-facing evaluation, such as Chatbot Arena, provides reliable signals but is costly and slow. In this work, we propose MixEval, a new paradigm for establishing efficient, gold-standard LLM evaluation by strategically mixing off-the-shelf benchmarks. It bridges (1) comprehensive and well-distributed real-world user queries and (2) efficient and fairly-graded ground-truth-based benchmarks, by matching queries mined from the web with similar queries from existing benchmarks. Based on MixEval, we further build MixEval-Hard, which offers more room for model improvement. Our benchmarks' advantages lie in (1) a 0.96 model ranking correlation with Chatbot Arena arising from the highly impartial query distribution and grading mechanism, (2) fast, cheap, and reproducible execution (6% of the time and cost of MMLU), and (3) dynamic evaluation enabled by the rapid and stable data update pipeline. We provide extensive meta-evaluation and analysis for our and existing LLM benchmarks to deepen the community's understanding of LLM evaluation and guide future research directions.
OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models
Jan 29, 2024



To help the open-source community have a better understanding of Mixture-of-Experts (MoE) based large language models (LLMs), we train and release OpenMoE, a series of fully open-sourced and reproducible decoder-only MoE LLMs, ranging from 650M to 34B parameters and trained on up to over 1T tokens. Our investigation confirms that MoE-based LLMs can offer a more favorable cost-effectiveness trade-off than dense LLMs, highlighting the potential effectiveness for future LLM development. One more important contribution of this study is an in-depth analysis of the routing mechanisms within our OpenMoE models, leading to three significant findings: Context-Independent Specialization, Early Routing Learning, and Drop-towards-the-End. We discovered that routing decisions in MoE models are predominantly based on token IDs, with minimal context relevance. The token-to-expert assignments are determined early in the pre-training phase and remain largely unchanged. This imperfect routing can result in performance degradation, particularly in sequential tasks like multi-turn conversations, where tokens appearing later in a sequence are more likely to be dropped. Finally, we rethink our design based on the above-mentioned observations and analysis. To facilitate future MoE LLM development, we propose potential strategies for mitigating the issues we found and further improving off-the-shelf MoE LLM designs.
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline
May 22, 2023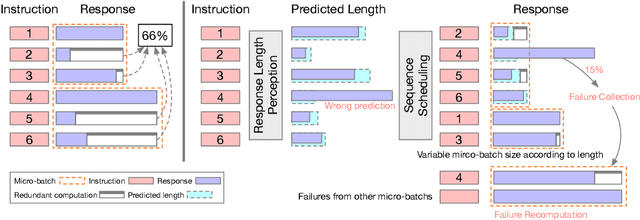



Large language models (LLMs) have revolutionized the field of AI, demonstrating unprecedented capacity across various tasks. However, the inference process for LLMs comes with significant computational costs. In this paper, we propose an efficient LLM inference pipeline that harnesses the power of LLMs. Our approach begins by tapping into the potential of LLMs to accurately perceive and predict the response length with minimal overhead. By leveraging this information, we introduce an efficient sequence scheduling technique that groups queries with similar response lengths into micro-batches. We evaluate our approach on real-world instruction datasets using the LLaMA-based model, and our results demonstrate an impressive 86% improvement in inference throughput without compromising effectiveness. Notably, our method is orthogonal to other inference acceleration techniques, making it a valuable addition to many existing toolkits (e.g., FlashAttention, Quantization) for LLM inference.
To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis
May 22, 2023Recent research has highlighted the importance of dataset size in scaling language models. However, large language models (LLMs) are notoriously token-hungry during pre-training, and high-quality text data on the web is approaching its scaling limit for LLMs. To further enhance LLMs, a straightforward approach is to repeat the pre-training data for additional epochs. In this study, we empirically investigate three key aspects under this approach. First, we explore the consequences of repeating pre-training data, revealing that the model is susceptible to overfitting, leading to multi-epoch degradation. Second, we examine the key factors contributing to multi-epoch degradation, finding that significant factors include dataset size, model parameters, and training objectives, while less influential factors consist of dataset quality and model FLOPs. Finally, we explore whether widely used regularization can alleviate multi-epoch degradation. Most regularization techniques do not yield significant improvements, except for dropout, which demonstrates remarkable effectiveness but requires careful tuning when scaling up the model size. Additionally, we discover that leveraging mixture-of-experts (MoE) enables cost-effective and efficient hyper-parameter tuning for computationally intensive dense LLMs with comparable trainable parameters, potentially impacting efficient LLM development on a broader scale.
Hierarchical Dialogue Understanding with Special Tokens and Turn-level Attention
Apr 29, 2023



Compared with standard text, understanding dialogue is more challenging for machines as the dynamic and unexpected semantic changes in each turn. To model such inconsistent semantics, we propose a simple but effective Hierarchical Dialogue Understanding model, HiDialog. Specifically, we first insert multiple special tokens into a dialogue and propose the turn-level attention to learn turn embeddings hierarchically. Then, a heterogeneous graph module is leveraged to polish the learned embeddings. We evaluate our model on various dialogue understanding tasks including dialogue relation extraction, dialogue emotion recognition, and dialogue act classification. Results show that our simple approach achieves state-of-the-art performance on all three tasks above. All our source code is publicly available at https://github.com/ShawX825/HiDialog.