 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongVILA: Scaling Long-Context Visual Language Models for Long Videos
Paper and Code
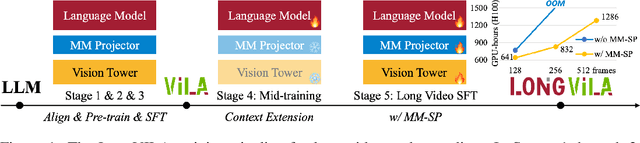

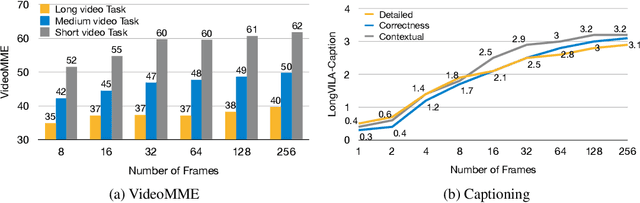
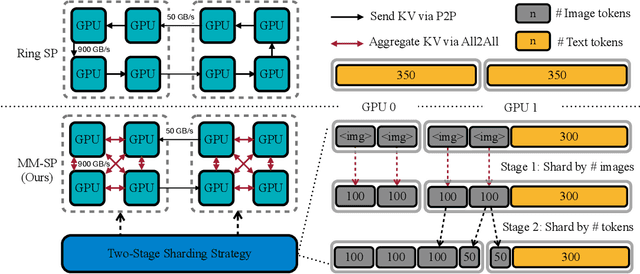
Long-context capability is critical for multi-modal foundation models, especially for long video understanding. We introduce LongVILA, a full-stack solution for long-context visual-language models by co-designing the algorithm and system. For model training, we upgrade existing VLMs to support long video understanding by incorporating two additional stages, i.e., long context extension and long supervised fine-tuning. However, training on long video is computationally and memory intensive. We introduce the long-context Multi-Modal Sequence Parallelism (MM-SP) system that efficiently parallelizes long video training and inference, enabling 2M context length training on 256 GPUs without any gradient checkpointing. LongVILA efficiently extends the number of video frames of VILA from 8 to 1024, improving the long video captioning score from 2.00 to 3.26 (out of 5), achieving 99.5% accuracy in 1400-frame (274k context length) video needle-in-a-haystack. LongVILA-8B demonstrates consistent accuracy improvements on long videos in the VideoMME benchmark as the number of frames increases. Besides, MM-SP is 2.1x - 5.7x faster than ring sequence parallelism and 1.1x - 1.4x faster than Megatron with context parallelism + tensor parallelism. Moreover, it seamlessly integrates with Hugging Face Transformers.