 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriAttention: Efficient Long Reasoning with Trigonometric KV Compression
Apr 06, 2026Extended reasoning in large language models (LLMs) creates severe KV cache memory bottlenecks. Leading KV cache compression methods estimate KV importance using attention scores from recent post-RoPE queries. However, queries rotate with position during RoPE, making representative queries very few, leading to poor top-key selection and unstable reasoning. To avoid this issue, we turn to the pre-RoPE space, where we observe that Q and K vectors are highly concentrated around fixed non-zero centers and remain stable across positions -- Q/K concentration. We show that this concentration causes queries to preferentially attend to keys at specific distances (e.g., nearest keys), with the centers determining which distances are preferred via a trigonometric series. Based on this, we propose TriAttention to estimate key importance by leveraging these centers. Via the trigonometric series, we use the distance preference characterized by these centers to score keys according to their positions, and also leverage Q/K norms as an additional signal for importance estimation. On AIME25 with 32K-token generation, TriAttention matches Full Attention reasoning accuracy while achieving 2.5x higher throughput or 10.7x KV memory reduction, whereas leading baselines achieve only about half the accuracy at the same efficiency. TriAttention enables OpenClaw deployment on a single consumer GPU, where long context would otherwise cause out-of-memory with Full Attention.
SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing
Apr 06, 2026Image spatial editing performs geometry-driven transformations, allowing precise control over object layout and camera viewpoints. Current models are insufficient for fine-grained spatial manipulations, motivating a dedicated assessment suite. Our contributions are listed: (i) We introduce SpatialEdit-Bench, a complete benchmark that evaluates spatial editing by jointly measuring perceptual plausibility and geometric fidelity via viewpoint reconstruction and framing analysis. (ii) To address the data bottleneck for scalable training, we construct SpatialEdit-500k, a synthetic dataset generated with a controllable Blender pipeline that renders objects across diverse backgrounds and systematic camera trajectories, providing precise ground-truth transformations for both object- and camera-centric operations. (iii) Building on this data, we develop SpatialEdit-16B, a baseline model for fine-grained spatial editing. Our method achieves competitive performance on general editing while substantially outperforming prior methods on spatial manipulation tasks. All resources will be made public at https://github.com/EasonXiao-888/SpatialEdit.
Harli: SLO-Aware Co-location of LLM Inference and PEFT-based Finetuning on Model-as-a-Service Platforms
Nov 19, 2025Large language models (LLMs) are increasingly deployed under the Model-as-a-Service (MaaS) paradigm. To meet stringent quality-of-service (QoS) requirements, existing LLM serving systems disaggregate the prefill and decode phases of inference. However, decode instances often experience low GPU utilization due to their memory-bound nature and insufficient batching in dynamic workloads, leaving compute resources underutilized. We introduce Harli, a serving system that improves GPU utilization by co-locating parameter-efficient finetuning (PEFT) tasks with LLM decode instances. PEFT tasks are compute-bound and memory-efficient, making them ideal candidates for safe co-location. Specifically, Harli addresses key challenges--limited memory and unpredictable interference--using three components: a unified memory allocator for runtime memory reuse, a two-stage latency predictor for decode latency modeling, and a QoS-guaranteed throughput-maximizing scheduler for throughput maximization. Experimental results show that Harli improves the finetune throughput by 46.2% on average (up to 92.0%) over state-of-the-art serving systems, while maintaining strict QoS guarantees for inference decode.
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Oct 10, 2025Vision-language models (VLMs) could power real-time assistants and autonomous agents, but they face a critical challenge: understanding near-infinite video streams without escalating latency and memory usage. Processing entire videos with full attention leads to quadratic computational costs and poor performance on long videos. Meanwhile, simple sliding window methods are also flawed, as they either break coherence or suffer from high latency due to redundant recomputation. In this paper, we introduce StreamingVLM, a model designed for real-time, stable understanding of infinite visual input. Our approach is a unified framework that aligns training with streaming inference. During inference, we maintain a compact KV cache by reusing states of attention sinks, a short window of recent vision tokens, and a long window of recent text tokens. This streaming ability is instilled via a simple supervised fine-tuning (SFT) strategy that applies full attention on short, overlapped video chunks, which effectively mimics the inference-time attention pattern without training on prohibitively long contexts. For evaluation, we build Inf-Streams-Eval, a new benchmark with videos averaging over two hours that requires dense, per-second alignment between frames and text. On Inf-Streams-Eval, StreamingVLM achieves a 66.18% win rate against GPT-4O mini and maintains stable, real-time performance at up to 8 FPS on a single NVIDIA H100. Notably, our SFT strategy also enhances general VQA abilities without any VQA-specific fine-tuning, improving performance on LongVideoBench by +4.30 and OVOBench Realtime by +5.96. Code is available at https://github.com/mit-han-lab/streaming-vlm.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
3D Aware Region Prompted Vision Language Model
Sep 16, 2025



We present Spatial Region 3D (SR-3D) aware vision-language model that connects single-view 2D images and multi-view 3D data through a shared visual token space. SR-3D supports flexible region prompting, allowing users to annotate regions with bounding boxes, segmentation masks on any frame, or directly in 3D, without the need for exhaustive multi-frame labeling. We achieve this by enriching 2D visual features with 3D positional embeddings, which allows the 3D model to draw upon strong 2D priors for more accurate spatial reasoning across frames, even when objects of interest do not co-occur within the same view. Extensive experiments on both general 2D vision language and specialized 3D spatial benchmarks demonstrate that SR-3D achieves state-of-the-art performance, underscoring its effectiveness for unifying 2D and 3D representation space on scene understanding. Moreover, we observe applicability to in-the-wild videos without sensory 3D inputs or ground-truth 3D annotations, where SR-3D accurately infers spatial relationships and metric measurements.
Scaling RL to Long Videos
Jul 10, 2025We introduce a full-stack framework that scales up reasoning in vision-language models (VLMs) to long videos, leveraging reinforcement learning. We address the unique challenges of long video reasoning by integrating three critical components: (1) a large-scale dataset, LongVideo-Reason, comprising 52K long video QA pairs with high-quality reasoning annotations across diverse domains such as sports, games, and vlogs; (2) a two-stage training pipeline that extends VLMs with chain-of-thought supervised fine-tuning (CoT-SFT) and reinforcement learning (RL); and (3) a training infrastructure for long video RL, named Multi-modal Reinforcement Sequence Parallelism (MR-SP), which incorporates sequence parallelism and a vLLM-based engine tailored for long video, using cached video embeddings for efficient rollout and prefilling. In experiments, LongVILA-R1-7B achieves strong performance on long video QA benchmarks such as VideoMME. It also outperforms Video-R1-7B and even matches Gemini-1.5-Pro across temporal reasoning, goal and purpose reasoning, spatial reasoning, and plot reasoning on our LongVideo-Reason-eval benchmark. Notably, our MR-SP system achieves up to 2.1x speedup on long video RL training. LongVILA-R1 demonstrates consistent performance gains as the number of input video frames scales. LongVILA-R1 marks a firm step towards long video reasoning in VLMs. In addition, we release our training system for public availability that supports RL training on various modalities (video, text, and audio), various models (VILA and Qwen series), and even image and video generation models. On a single A100 node (8 GPUs), it supports RL training on hour-long videos (e.g., 3,600 frames / around 256k tokens).
MindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPO
May 19, 2025



Recent text-to-image systems face limitations in handling multimodal inputs and complex reasoning tasks. We introduce MindOmni, a unified multimodal large language model that addresses these challenges by incorporating reasoning generation through reinforcement learning. MindOmni leverages a three-phase training strategy: i) design of a unified vision language model with a decoder-only diffusion module, ii) supervised fine-tuning with Chain-of-Thought (CoT) instruction data, and iii) our proposed Reasoning Generation Policy Optimization (RGPO) algorithm, utilizing multimodal feedback to effectively guide policy updates. Experimental results demonstrate that MindOmni outperforms existing models, achieving impressive performance on both understanding and generation benchmarks, meanwhile showcasing advanced fine-grained reasoning generation capabilities, especially with mathematical reasoning instruction. All codes will be made public at \href{https://github.com/EasonXiao-888/MindOmni}{https://github.com/EasonXiao-888/MindOmni}.
TraveLLaMA: Facilitating Multi-modal Large Language Models to Understand Urban Scenes and Provide Travel Assistance
Apr 23, 2025Tourism and travel planning increasingly rely on digital assistance, yet existing multimodal AI systems often lack specialized knowledge and contextual understanding of urban environments. We present TraveLLaMA, a specialized multimodal language model designed for urban scene understanding and travel assistance. Our work addresses the fundamental challenge of developing practical AI travel assistants through a novel large-scale dataset of 220k question-answer pairs. This comprehensive dataset uniquely combines 130k text QA pairs meticulously curated from authentic travel forums with GPT-enhanced responses, alongside 90k vision-language QA pairs specifically focused on map understanding and scene comprehension. Through extensive fine-tuning experiments on state-of-the-art vision-language models (LLaVA, Qwen-VL, Shikra), we demonstrate significant performance improvements ranging from 6.5\%-9.4\% in both pure text travel understanding and visual question answering tasks. Our model exhibits exceptional capabilities in providing contextual travel recommendations, interpreting map locations, and understanding place-specific imagery while offering practical information such as operating hours and visitor reviews. Comparative evaluations show TraveLLaMA significantly outperforms general-purpose models in travel-specific tasks, establishing a new benchmark for multi-modal travel assistance systems.
WorldModelBench: Judging Video Generation Models As World Models
Feb 28, 2025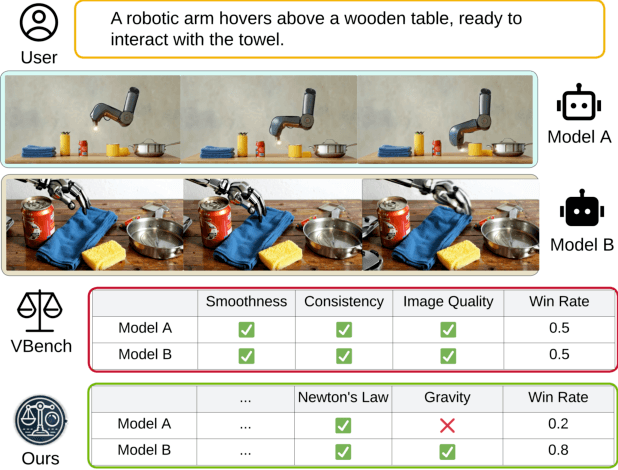
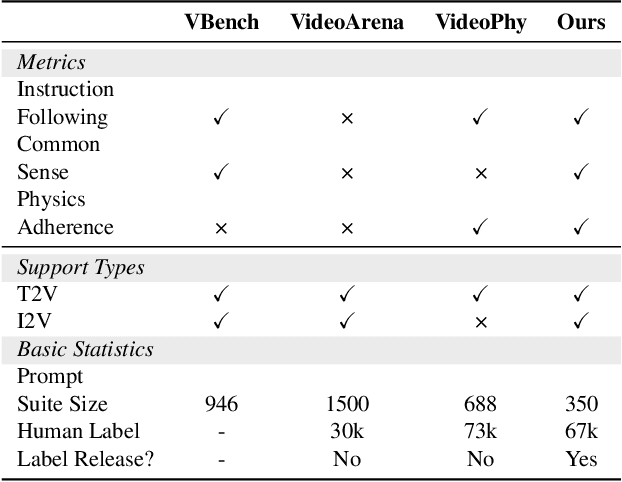
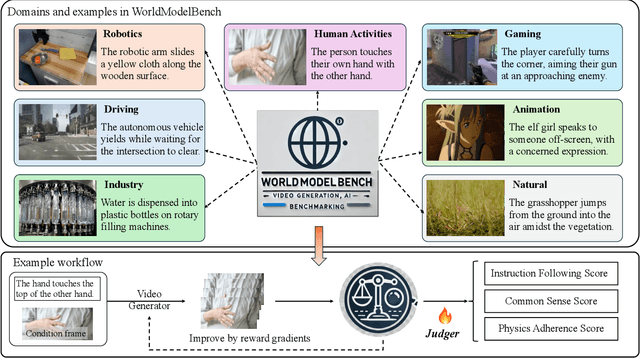
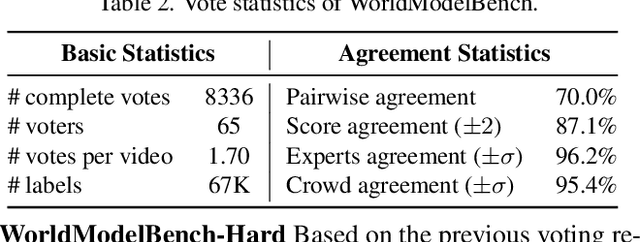
Video generation models have rapidly progressed, positioning themselves as video world models capable of supporting decision-making applications like robotics and autonomous driving. However, current benchmarks fail to rigorously evaluate these claims, focusing only on general video quality, ignoring important factors to world models such as physics adherence. To bridge this gap, we propose WorldModelBench, a benchmark designed to evaluate the world modeling capabilities of video generation models in application-driven domains. WorldModelBench offers two key advantages: (1) Against to nuanced world modeling violations: By incorporating instruction-following and physics-adherence dimensions, WorldModelBench detects subtle violations, such as irregular changes in object size that breach the mass conservation law - issues overlooked by prior benchmarks. (2) Aligned with large-scale human preferences: We crowd-source 67K human labels to accurately measure 14 frontier models. Using our high-quality human labels, we further fine-tune an accurate judger to automate the evaluation procedure, achieving 8.6% higher average accuracy in predicting world modeling violations than GPT-4o with 2B parameters. In addition, we demonstrate that training to align human annotations by maximizing the rewards from the judger noticeably improve the world modeling capability. The website is available at https://worldmodelbench-team.github.io.