 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Text Prompts: Visual-to-Visual Generation as A Unified Paradigm
May 12, 2026Humans often specify and create through visual artifacts: typography sheets, sketches, reference images, and annotated scenes. Yet modern visual generators still ask users to serialize this intent into text, a bottleneck that compresses signals like spatial structure, exact appearance, and glyph shape. We propose \textbf{\emph{visual-to-visual} (V2V)} generation, in which the user conditions a generative model with a visual specification page rather than a text prompt. The page is not an edit target, but a visual document that specifies the desired output. We introduce \textbf{V2V-Zero}, a training-free framework that exposes this interface in existing vision-language model (VLM) conditioned generators by replacing text-only conditioning with final-layer hidden states extracted from visual pages, exploiting the fact that the frozen VLM already maps both text and images into the generator's conditioning space. On GenEval, V2V-Zero reaches 0.85 with a frozen Qwen-Image backbone, closely matching its optimized text-to-image performance without fine-tuning. To evaluate the broader V2V space, we introduce \textbf{Simple-V2V Bench}, spanning seven visual-conditioning tasks and seven models, including GPT Image 2, Nano Banana 2, Seedream 5.0 Lite, open-weight baselines, and a video extension. V2V-Zero scores 32.7/100, outperforming evaluated open-weight image baselines and revealing a clear capability hierarchy: attribute binding is strong, content generation is unreliable, and structural control remains hard even for commercial systems. A HunyuanVideo-1.5 extension scores 20.2/100, showing the interface transfers beyond images. Mechanistic analysis shows the default reasoning path is primarily visually routed, with 95.0\% of conditioning-token attention mass on visual-page hidden states.
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
SearchGym: Bootstrapping Real-World Search Agents via Cost-Effective and High-Fidelity Environment Simulation
Jan 21, 2026Search agents have emerged as a pivotal paradigm for solving open-ended, knowledge-intensive reasoning tasks. However, training these agents via Reinforcement Learning (RL) faces a critical dilemma: interacting with live commercial Web APIs is prohibitively expensive, while relying on static data snapshots often introduces noise due to data misalignment. This misalignment generates corrupted reward signals that destabilize training by penalizing correct reasoning or rewarding hallucination. To address this, we propose SearchGym, a simulation environment designed to bootstrap robust search agents. SearchGym employs a rigorous generative pipeline to construct a verifiable knowledge graph and an aligned document corpus, ensuring that every reasoning task is factually grounded and strictly solvable. Building on this controllable environment, we introduce SearchGym-RL, a curriculum learning methodology that progressively optimizes agent policies through purified feedback, evolving from basic interactions to complex, long-horizon planning. Extensive experiments across the Llama and Qwen families demonstrate strong Sim-to-Real generalization. Notably, our Qwen2.5-7B-Base model trained within SearchGym surpasses the web-enhanced ASearcher baseline across nine diverse benchmarks by an average relative margin of 10.6%. Our results validate that high-fidelity simulation serves as a scalable and highly cost-effective methodology for developing capable search agents.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
VisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis
Dec 22, 2025Generative models can now produce photorealistic imagery, yet they still struggle with the long, multi-goal prompts that professional designers issue. To expose this gap and better evaluate models' performance in real-world settings, we introduce Long Goal Bench (LGBench), a 2,000-task suite (1,000 T2I and 1,000 I2I) whose average instruction contains 18 to 22 tightly coupled goals spanning global layout, local object placement, typography, and logo fidelity. We find that even state-of-the-art models satisfy fewer than 72 percent of the goals and routinely miss localized edits, confirming the brittleness of current pipelines. To address this, we present VisionDirector, a training-free vision-language supervisor that (i) extracts structured goals from long instructions, (ii) dynamically decides between one-shot generation and staged edits, (iii) runs micro-grid sampling with semantic verification and rollback after every edit, and (iv) logs goal-level rewards. We further fine-tune the planner with Group Relative Policy Optimization, yielding shorter edit trajectories (3.1 versus 4.2 steps) and stronger alignment. VisionDirector achieves new state of the art on GenEval (plus 7 percent overall) and ImgEdit (plus 0.07 absolute) while producing consistent qualitative improvements on typography, multi-object scenes, and pose editing.
VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
Jun 12, 2025We present VRBench, the first long narrative video benchmark crafted for evaluating large models' multi-step reasoning capabilities, addressing limitations in existing evaluations that overlook temporal reasoning and procedural validity. It comprises 1,010 long videos (with an average duration of 1.6 hours), along with 9,468 human-labeled multi-step question-answering pairs and 30,292 reasoning steps with timestamps. These videos are curated via a multi-stage filtering process including expert inter-rater reviewing to prioritize plot coherence. We develop a human-AI collaborative framework that generates coherent reasoning chains, each requiring multiple temporally grounded steps, spanning seven types (e.g., event attribution, implicit inference). VRBench designs a multi-phase evaluation pipeline that assesses models at both the outcome and process levels. Apart from the MCQs for the final results, we propose a progress-level LLM-guided scoring metric to evaluate the quality of the reasoning chain from multiple dimensions comprehensively. Through extensive evaluations of 12 LLMs and 16 VLMs on VRBench, we undertake a thorough analysis and provide valuable insights that advance the field of multi-step reasoning.
TraveLLaMA: Facilitating Multi-modal Large Language Models to Understand Urban Scenes and Provide Travel Assistance
Apr 23, 2025Tourism and travel planning increasingly rely on digital assistance, yet existing multimodal AI systems often lack specialized knowledge and contextual understanding of urban environments. We present TraveLLaMA, a specialized multimodal language model designed for urban scene understanding and travel assistance. Our work addresses the fundamental challenge of developing practical AI travel assistants through a novel large-scale dataset of 220k question-answer pairs. This comprehensive dataset uniquely combines 130k text QA pairs meticulously curated from authentic travel forums with GPT-enhanced responses, alongside 90k vision-language QA pairs specifically focused on map understanding and scene comprehension. Through extensive fine-tuning experiments on state-of-the-art vision-language models (LLaVA, Qwen-VL, Shikra), we demonstrate significant performance improvements ranging from 6.5\%-9.4\% in both pure text travel understanding and visual question answering tasks. Our model exhibits exceptional capabilities in providing contextual travel recommendations, interpreting map locations, and understanding place-specific imagery while offering practical information such as operating hours and visitor reviews. Comparative evaluations show TraveLLaMA significantly outperforms general-purpose models in travel-specific tasks, establishing a new benchmark for multi-modal travel assistance systems.
Understanding Long Videos via LLM-Powered Entity Relation Graphs
Jan 27, 2025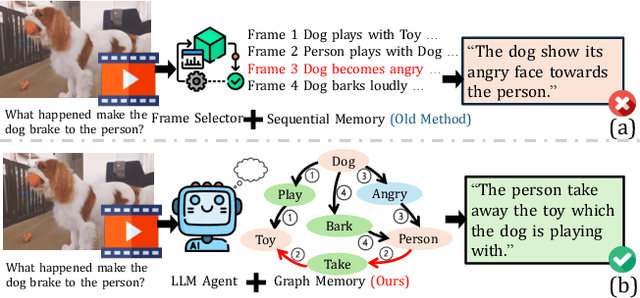
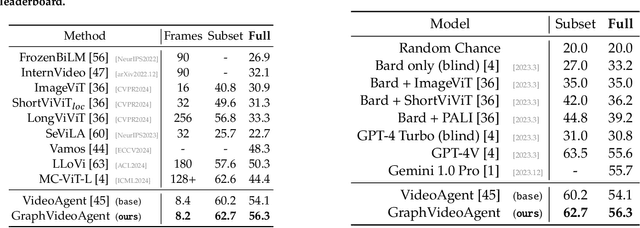
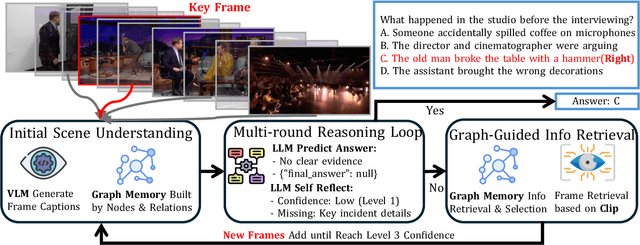
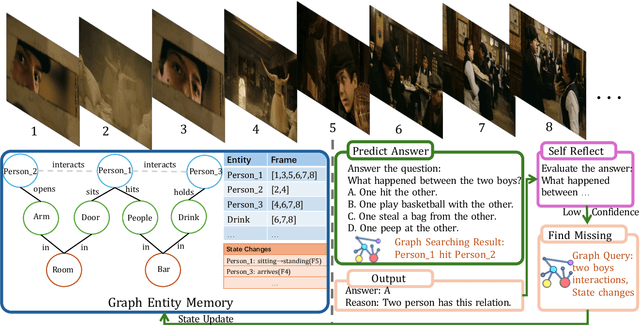
The analysis of extended video content poses unique challenges in artificial intelligence, particularly when dealing with the complexity of tracking and understanding visual elements across time. Current methodologies that process video frames sequentially struggle to maintain coherent tracking of objects, especially when these objects temporarily vanish and later reappear in the footage. A critical limitation of these approaches is their inability to effectively identify crucial moments in the video, largely due to their limited grasp of temporal relationships. To overcome these obstacles, we present GraphVideoAgent, a cutting-edge system that leverages the power of graph-based object tracking in conjunction with large language model capabilities. At its core, our framework employs a dynamic graph structure that maps and monitors the evolving relationships between visual entities throughout the video sequence. This innovative approach enables more nuanced understanding of how objects interact and transform over time, facilitating improved frame selection through comprehensive contextual awareness. Our approach demonstrates remarkable effectiveness when tested against industry benchmarks. In evaluations on the EgoSchema dataset, GraphVideoAgent achieved a 2.2 improvement over existing methods while requiring analysis of only 8.2 frames on average. Similarly, testing on the NExT-QA benchmark yielded a 2.0 performance increase with an average frame requirement of 8.1. These results underscore the efficiency of our graph-guided methodology in enhancing both accuracy and computational performance in long-form video understanding tasks.
IRIS: Interactive Responsive Intelligent Segmentation for 3D Affordance Analysis
Sep 17, 2024Recent advancements in large language and vision-language models have significantly enhanced multimodal understanding, yet translating high-level linguistic instructions into precise robotic actions in 3D space remains challenging. This paper introduces IRIS (Interactive Responsive Intelligent Segmentation), a novel training-free multimodal system for 3D affordance segmentation, alongside a benchmark for evaluating interactive language-guided affordance in everyday environments. IRIS integrates a large multimodal model with a specialized 3D vision network, enabling seamless fusion of 2D and 3D visual understanding with language comprehension. To facilitate evaluation, we present a dataset of 10 typical indoor environments, each with 50 images annotated for object actions and 3D affordance segmentation. Extensive experiments demonstrate IRIS's capability in handling interactive 3D affordance segmentation tasks across diverse settings, showcasing competitive performance across various metrics. Our results highlight IRIS's potential for enhancing human-robot interaction based on affordance understanding in complex indoor environments, advancing the development of more intuitive and efficient robotic systems for real-world applications.
Towards Natural Language-Guided Drones: GeoText-1652 Benchmark with Spatially Relation Matching
Nov 21, 2023



Drone navigation through natural language commands remains a significant challenge due to the lack of publicly available multi-modal datasets and the intricate demands of fine-grained visual-text alignment. In response to this pressing need, we present a new human-computer interaction annotation benchmark called GeoText-1652, meticulously curated through a robust Large Language Model (LLM)-based data generation framework and the expertise of pre-trained vision models. This new dataset seamlessly extends the existing image dataset, \ie, University-1652, with spatial-aware text annotations, encompassing intricate image-text-bounding box associations. Besides, we introduce a new optimization objective to leverage fine-grained spatial associations, called blending spatial matching, for region-level spatial relation matching. Extensive experiments reveal that our approach maintains an exceptional recall rate under varying description complexities. This underscores the promising potential of our approach in elevating drone control and navigation through the seamless integration of natural language commands in real-world scenarios.