 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM
Dec 11, 2025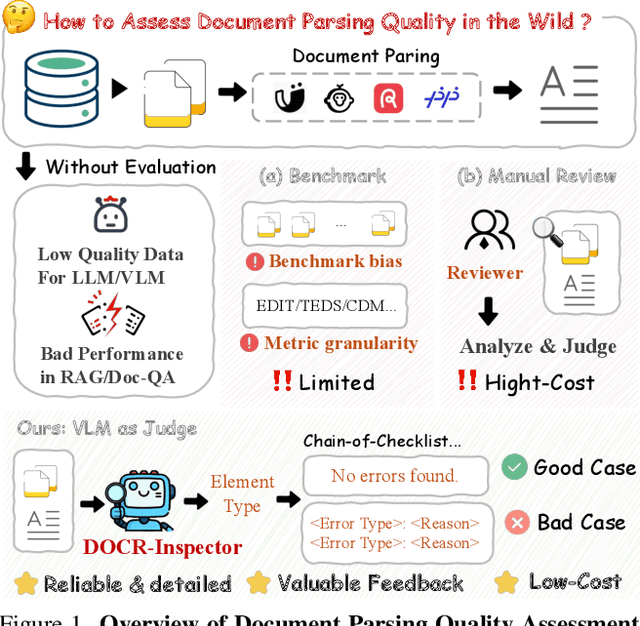
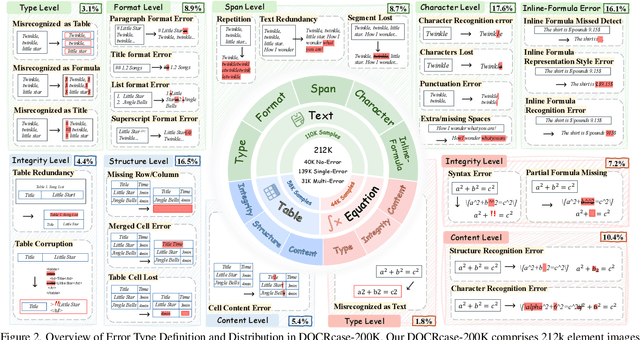

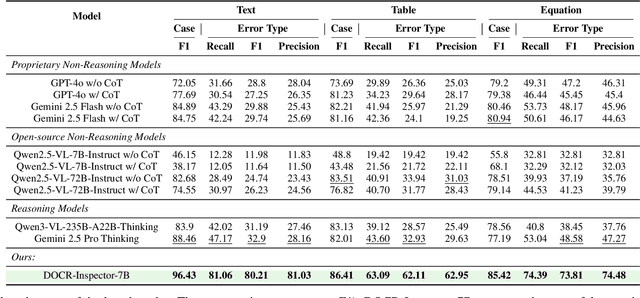
Document parsing aims to transform unstructured PDF images into semi-structured data, facilitating the digitization and utilization of information in diverse domains. While vision language models (VLMs) have significantly advanced this task, achieving reliable, high-quality parsing in real-world scenarios remains challenging. Common practice often selects the top-performing model on standard benchmarks. However, these benchmarks may carry dataset-specific biases, leading to inconsistent model rankings and limited correlation with real-world performance. Moreover, benchmark metrics typically provide only overall scores, which can obscure distinct error patterns in output. This raises a key challenge: how can we reliably and comprehensively assess document parsing quality in the wild? We address this problem with DOCR-Inspector, which formalizes document parsing assessment as fine-grained error detection and analysis. Leveraging VLM-as-a-Judge, DOCR-Inspector analyzes a document image and its parsed output, identifies all errors, assigns them to one of 28 predefined types, and produces a comprehensive quality assessment. To enable this capability, we construct DOCRcase-200K for training and propose the Chain-of-Checklist reasoning paradigm to enable the hierarchical structure of parsing quality assessment. For empirical validation, we introduce DOCRcaseBench, a set of 882 real-world document parsing cases with manual annotations. On this benchmark, DOCR-Inspector-7B outperforms commercial models like Gemini 2.5 Pro, as well as leading open-source models. Further experiments demonstrate that its quality assessments provide valuable guidance for parsing results refinement, making DOCR-Inspector both a practical evaluator and a driver for advancing document parsing systems at scale. Model and code are released at: https://github.com/ZZZZZQT/DOCR-Inspector.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
Jun 12, 2025We present VRBench, the first long narrative video benchmark crafted for evaluating large models' multi-step reasoning capabilities, addressing limitations in existing evaluations that overlook temporal reasoning and procedural validity. It comprises 1,010 long videos (with an average duration of 1.6 hours), along with 9,468 human-labeled multi-step question-answering pairs and 30,292 reasoning steps with timestamps. These videos are curated via a multi-stage filtering process including expert inter-rater reviewing to prioritize plot coherence. We develop a human-AI collaborative framework that generates coherent reasoning chains, each requiring multiple temporally grounded steps, spanning seven types (e.g., event attribution, implicit inference). VRBench designs a multi-phase evaluation pipeline that assesses models at both the outcome and process levels. Apart from the MCQs for the final results, we propose a progress-level LLM-guided scoring metric to evaluate the quality of the reasoning chain from multiple dimensions comprehensively. Through extensive evaluations of 12 LLMs and 16 VLMs on VRBench, we undertake a thorough analysis and provide valuable insights that advance the field of multi-step reasoning.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0