 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Apr 06, 2026Current document parsing methods compete primarily on model architecture innovation, while systematic engineering of training data remains underexplored. Yet SOTA models of different architectures and parameter scales exhibit highly consistent failure patterns on the same set of hard samples, suggesting that the performance bottleneck stems from shared deficiencies in training data rather than architecture itself. Building on this finding, we present \minerupro, which advances the state of the art solely through data engineering and training strategy optimization while keeping the 1.2B-parameter architecture of \mineru completely fixed. At its core is a Data Engine co-designed around coverage, informativeness, and annotation accuracy: Diversity-and-Difficulty-Aware Sampling expands training data from under 10M to 65.5M samples while correcting distribution shift; Cross-Model Consistency Verification leverages output agreement among heterogeneous models to assess sample difficulty and generate reliable annotations; the Judge-and-Refine pipeline improves annotation quality for hard samples through render-then-verify iterative correction. A three-stage progressive training strategy -- large-scale pre-training, hard sample fine-tuning, and GRPO alignment -- sequentially exploits these data at different quality tiers. On the evaluation front, we fix element-matching biases in OmniDocBench~v1.5 and introduce a Hard subset, establishing the more discriminative OmniDocBench~v1.6 protocol. Without any architectural modification, \minerupro achieves 95.69 on OmniDocBench~v1.6, improving over the same-architecture baseline by 2.71 points and surpassing all existing methods including models with over 200$\times$ more parameters.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
Jun 12, 2025We present VRBench, the first long narrative video benchmark crafted for evaluating large models' multi-step reasoning capabilities, addressing limitations in existing evaluations that overlook temporal reasoning and procedural validity. It comprises 1,010 long videos (with an average duration of 1.6 hours), along with 9,468 human-labeled multi-step question-answering pairs and 30,292 reasoning steps with timestamps. These videos are curated via a multi-stage filtering process including expert inter-rater reviewing to prioritize plot coherence. We develop a human-AI collaborative framework that generates coherent reasoning chains, each requiring multiple temporally grounded steps, spanning seven types (e.g., event attribution, implicit inference). VRBench designs a multi-phase evaluation pipeline that assesses models at both the outcome and process levels. Apart from the MCQs for the final results, we propose a progress-level LLM-guided scoring metric to evaluate the quality of the reasoning chain from multiple dimensions comprehensively. Through extensive evaluations of 12 LLMs and 16 VLMs on VRBench, we undertake a thorough analysis and provide valuable insights that advance the field of multi-step reasoning.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
Dec 10, 2024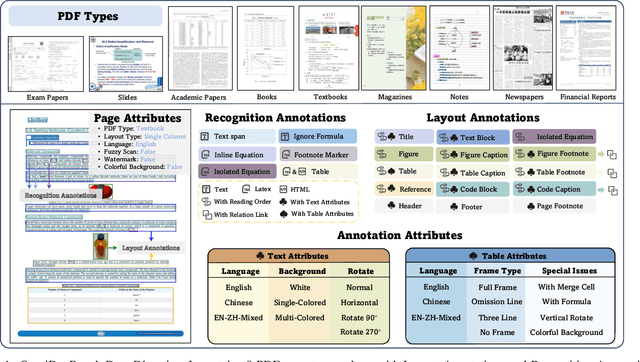
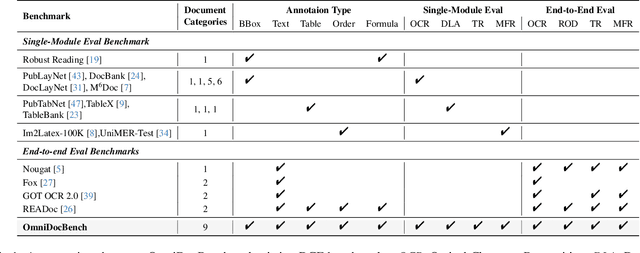
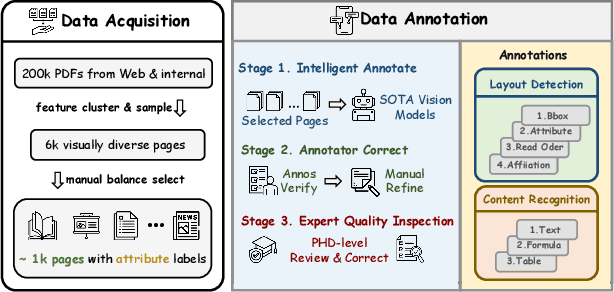
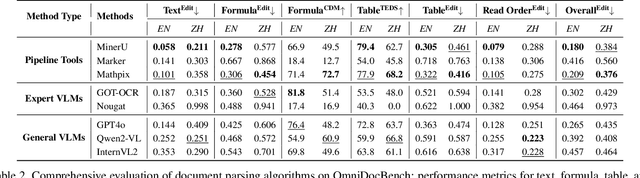
Document content extraction is crucial in computer vision, especially for meeting the high-quality data needs of large language models (LLMs) and retrieval-augmented generation (RAG) technologies. However, current document parsing methods suffer from significant limitations in terms of diversity and comprehensive evaluation. To address these challenges, we introduce OmniDocBench, a novel multi-source benchmark designed to advance automated document content extraction. OmniDocBench includes a meticulously curated and annotated high-quality evaluation dataset comprising nine diverse document types, such as academic papers, textbooks, slides, among others. Our benchmark provides a flexible and comprehensive evaluation framework with 19 layout category labels and 14 attribute labels, enabling multi-level assessments across entire datasets, individual modules, or specific data types. Using OmniDocBench, we perform an exhaustive comparative analysis of existing modular pipelines and multimodal end-to-end methods, highlighting their limitations in handling document diversity and ensuring fair evaluation. OmniDocBench establishes a robust, diverse, and fair evaluation standard for the document content extraction field, offering crucial insights for future advancements and fostering the development of document parsing technologies. The codes and dataset is available in https://github.com/opendatalab/OmniDocBench.
OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
Jun 13, 2024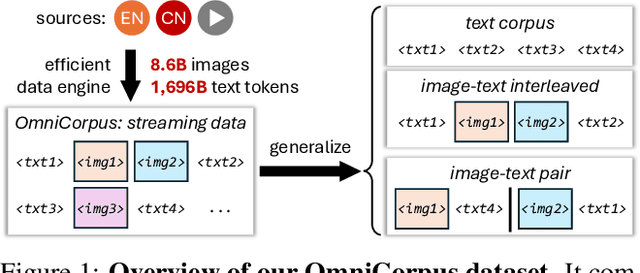
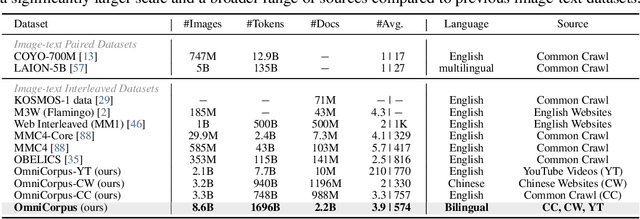

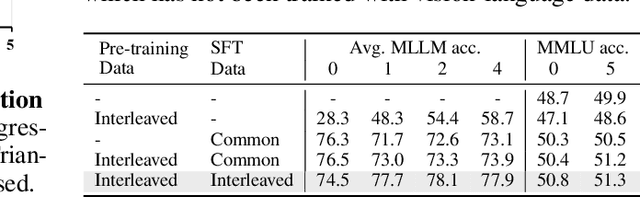
Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024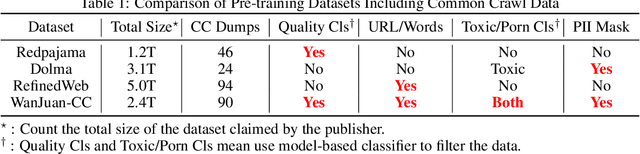
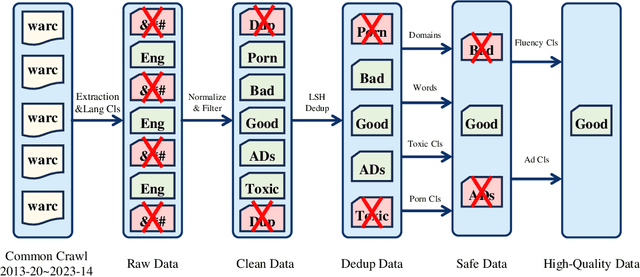
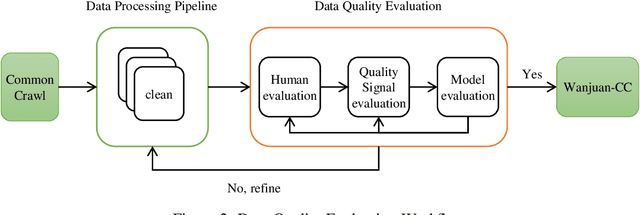

This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.