 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCR-Inspector: Fine-Grained and Automated Evaluation of Document Parsing with VLM
Dec 11, 2025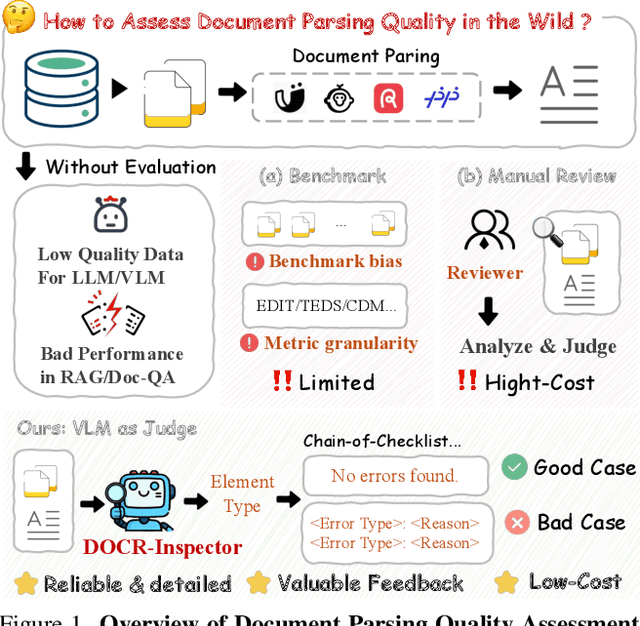
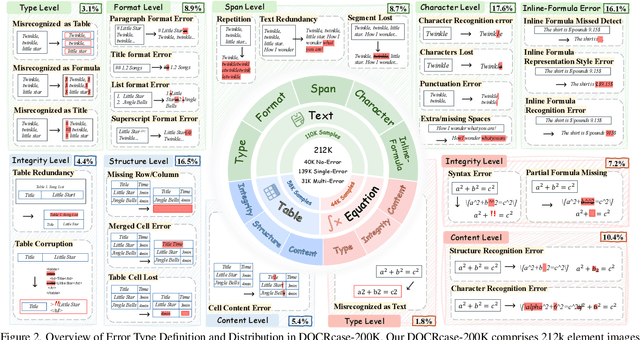

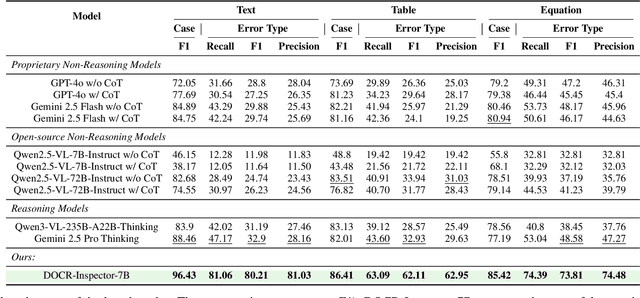
Document parsing aims to transform unstructured PDF images into semi-structured data, facilitating the digitization and utilization of information in diverse domains. While vision language models (VLMs) have significantly advanced this task, achieving reliable, high-quality parsing in real-world scenarios remains challenging. Common practice often selects the top-performing model on standard benchmarks. However, these benchmarks may carry dataset-specific biases, leading to inconsistent model rankings and limited correlation with real-world performance. Moreover, benchmark metrics typically provide only overall scores, which can obscure distinct error patterns in output. This raises a key challenge: how can we reliably and comprehensively assess document parsing quality in the wild? We address this problem with DOCR-Inspector, which formalizes document parsing assessment as fine-grained error detection and analysis. Leveraging VLM-as-a-Judge, DOCR-Inspector analyzes a document image and its parsed output, identifies all errors, assigns them to one of 28 predefined types, and produces a comprehensive quality assessment. To enable this capability, we construct DOCRcase-200K for training and propose the Chain-of-Checklist reasoning paradigm to enable the hierarchical structure of parsing quality assessment. For empirical validation, we introduce DOCRcaseBench, a set of 882 real-world document parsing cases with manual annotations. On this benchmark, DOCR-Inspector-7B outperforms commercial models like Gemini 2.5 Pro, as well as leading open-source models. Further experiments demonstrate that its quality assessments provide valuable guidance for parsing results refinement, making DOCR-Inspector both a practical evaluator and a driver for advancing document parsing systems at scale. Model and code are released at: https://github.com/ZZZZZQT/DOCR-Inspector.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
Dec 10, 2024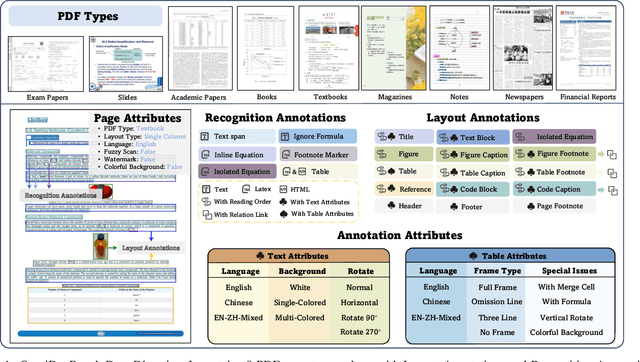
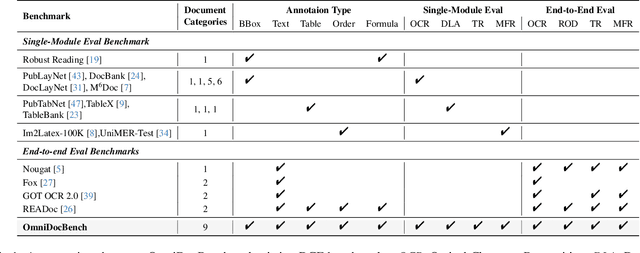
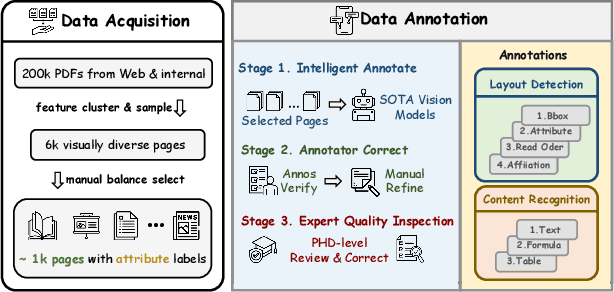
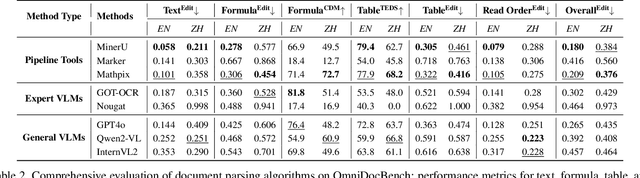
Document content extraction is crucial in computer vision, especially for meeting the high-quality data needs of large language models (LLMs) and retrieval-augmented generation (RAG) technologies. However, current document parsing methods suffer from significant limitations in terms of diversity and comprehensive evaluation. To address these challenges, we introduce OmniDocBench, a novel multi-source benchmark designed to advance automated document content extraction. OmniDocBench includes a meticulously curated and annotated high-quality evaluation dataset comprising nine diverse document types, such as academic papers, textbooks, slides, among others. Our benchmark provides a flexible and comprehensive evaluation framework with 19 layout category labels and 14 attribute labels, enabling multi-level assessments across entire datasets, individual modules, or specific data types. Using OmniDocBench, we perform an exhaustive comparative analysis of existing modular pipelines and multimodal end-to-end methods, highlighting their limitations in handling document diversity and ensuring fair evaluation. OmniDocBench establishes a robust, diverse, and fair evaluation standard for the document content extraction field, offering crucial insights for future advancements and fostering the development of document parsing technologies. The codes and dataset is available in https://github.com/opendatalab/OmniDocBench.
OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation
Dec 03, 2024Retrieval-augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external knowledge to reduce hallucinations and incorporate up-to-date information without retraining. As an essential part of RAG, external knowledge bases are commonly built by extracting structured data from unstructured PDF documents using Optical Character Recognition (OCR). However, given the imperfect prediction of OCR and the inherent non-uniform representation of structured data, knowledge bases inevitably contain various OCR noises. In this paper, we introduce OHRBench, the first benchmark for understanding the cascading impact of OCR on RAG systems. OHRBench includes 350 carefully selected unstructured PDF documents from six real-world RAG application domains, along with Q&As derived from multimodal elements in documents, challenging existing OCR solutions used for RAG To better understand OCR's impact on RAG systems, we identify two primary types of OCR noise: Semantic Noise and Formatting Noise and apply perturbation to generate a set of structured data with varying degrees of each OCR noise. Using OHRBench, we first conduct a comprehensive evaluation of current OCR solutions and reveal that none is competent for constructing high-quality knowledge bases for RAG systems. We then systematically evaluate the impact of these two noise types and demonstrate the vulnerability of RAG systems. Furthermore, we discuss the potential of employing Vision-Language Models (VLMs) without OCR in RAG systems. Code: https://github.com/opendatalab/OHR-Bench
MinerU: An Open-Source Solution for Precise Document Content Extraction
Sep 27, 2024



Document content analysis has been a crucial research area in computer vision. Despite significant advancements in methods such as OCR, layout detection, and formula recognition, existing open-source solutions struggle to consistently deliver high-quality content extraction due to the diversity in document types and content. To address these challenges, we present MinerU, an open-source solution for high-precision document content extraction. MinerU leverages the sophisticated PDF-Extract-Kit models to extract content from diverse documents effectively and employs finely-tuned preprocessing and postprocessing rules to ensure the accuracy of the final results. Experimental results demonstrate that MinerU consistently achieves high performance across various document types, significantly enhancing the quality and consistency of content extraction. The MinerU open-source project is available at https://github.com/opendatalab/MinerU.
CDM: A Reliable Metric for Fair and Accurate Formula Recognition Evaluation
Sep 05, 2024
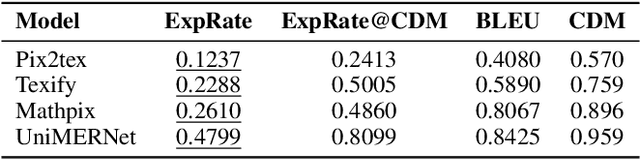


Formula recognition presents significant challenges due to the complicated structure and varied notation of mathematical expressions. Despite continuous advancements in formula recognition models, the evaluation metrics employed by these models, such as BLEU and Edit Distance, still exhibit notable limitations. They overlook the fact that the same formula has diverse representations and is highly sensitive to the distribution of training data, thereby causing the unfairness in formula recognition evaluation. To this end, we propose a Character Detection Matching (CDM) metric, ensuring the evaluation objectivity by designing a image-level rather than LaTex-level metric score. Specifically, CDM renders both the model-predicted LaTeX and the ground-truth LaTeX formulas into image-formatted formulas, then employs visual feature extraction and localization techniques for precise character-level matching, incorporating spatial position information. Such a spatially-aware and character-matching method offers a more accurate and equitable evaluation compared with previous BLEU and Edit Distance metrics that rely solely on text-based character matching. Experimentally, we evaluated various formula recognition models using CDM, BLEU, and ExpRate metrics. Their results demonstrate that the CDM aligns more closely with human evaluation standards and provides a fairer comparison across different models by eliminating discrepancies caused by diverse formula representations.
InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output
Jul 03, 2024



We present InternLM-XComposer-2.5 (IXC-2.5), a versatile large-vision language model that supports long-contextual input and output. IXC-2.5 excels in various text-image comprehension and composition applications, achieving GPT-4V level capabilities with merely 7B LLM backend. Trained with 24K interleaved image-text contexts, it can seamlessly extend to 96K long contexts via RoPE extrapolation. This long-context capability allows IXC-2.5 to excel in tasks requiring extensive input and output contexts. Compared to its previous 2.0 version, InternLM-XComposer-2.5 features three major upgrades in vision-language comprehension: (1) Ultra-High Resolution Understanding, (2) Fine-Grained Video Understanding, and (3) Multi-Turn Multi-Image Dialogue. In addition to comprehension, IXC-2.5 extends to two compelling applications using extra LoRA parameters for text-image composition: (1) Crafting Webpages and (2) Composing High-Quality Text-Image Articles. IXC-2.5 has been evaluated on 28 benchmarks, outperforming existing open-source state-of-the-art models on 16 benchmarks. It also surpasses or competes closely with GPT-4V and Gemini Pro on 16 key tasks. The InternLM-XComposer-2.5 is publicly available at https://github.com/InternLM/InternLM-XComposer.
DSDL: Data Set Description Language for Bridging Modalities and Tasks in AI Data
May 28, 2024In the era of artificial intelligence, the diversity of data modalities and annotation formats often renders data unusable directly, requiring understanding and format conversion before it can be used by researchers or developers with different needs. To tackle this problem, this article introduces a framework called Dataset Description Language (DSDL) that aims to simplify dataset processing by providing a unified standard for AI datasets. DSDL adheres to the three basic practical principles of generic, portable, and extensible, using a unified standard to express data of different modalities and structures, facilitating the dissemination of AI data, and easily extending to new modalities and tasks. The standardized specifications of DSDL reduce the workload for users in data dissemination, processing, and usage. To further improve user convenience, we provide predefined DSDL templates for various tasks, convert mainstream datasets to comply with DSDL specifications, and provide comprehensive documentation and DSDL tools. These efforts aim to simplify the use of AI data, thereby improving the efficiency of AI development.
InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
Apr 09, 2024



The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.