 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalAgent: A Conversational Multi-Agent System for End-to-End Causal Inference
Feb 12, 2026Causal inference holds immense value in fields such as healthcare, economics, and social sciences. However, traditional causal analysis workflows impose significant technical barriers, requiring researchers to possess dual backgrounds in statistics and computer science, while manually selecting algorithms, handling data quality issues, and interpreting complex results. To address these challenges, we propose CausalAgent, a conversational multi-agent system for end-to-end causal inference. The system innovatively integrates Multi-Agent Systems (MAS), Retrieval-Augmented Generation (RAG), and the Model Context Protocol (MCP) to achieve automation from data cleaning and causal structure learning to bias correction and report generation through natural language interaction. Users need only upload a dataset and pose questions in natural language to receive a rigorous, interactive analysis report. As a novel user-centered human-AI collaboration paradigm, CausalAgent explicitly models the analysis workflow. By leveraging interactive visualizations, it significantly lowers the barrier to entry for causal analysis while ensuring the rigor and interpretability of the process.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
Causal invariant geographic network representations with feature and structural distribution shifts
Mar 25, 2025The existing methods learn geographic network representations through deep graph neural networks (GNNs) based on the i.i.d. assumption. However, the spatial heterogeneity and temporal dynamics of geographic data make the out-of-distribution (OOD) generalisation problem particularly salient. The latter are particularly sensitive to distribution shifts (feature and structural shifts) between testing and training data and are the main causes of the OOD generalisation problem. Spurious correlations are present between invariant and background representations due to selection biases and environmental effects, resulting in the model extremes being more likely to learn background representations. The existing approaches focus on background representation changes that are determined by shifts in the feature distributions of nodes in the training and test data while ignoring changes in the proportional distributions of heterogeneous and homogeneous neighbour nodes, which we refer to as structural distribution shifts. We propose a feature-structure mixed invariant representation learning (FSM-IRL) model that accounts for both feature distribution shifts and structural distribution shifts. To address structural distribution shifts, we introduce a sampling method based on causal attention, encouraging the model to identify nodes possessing strong causal relationships with labels or nodes that are more similar to the target node. Inspired by the Hilbert-Schmidt independence criterion, we implement a reweighting strategy to maximise the orthogonality of the node representations, thereby mitigating the spurious correlations among the node representations and suppressing the learning of background representations. Our experiments demonstrate that FSM-IRL exhibits strong learning capabilities on both geographic and social network datasets in OOD scenarios.
* 15 pages, 3 figures, 8 tables
Easing Seasickness through Attention Redirection with a Mindfulness-Based Brain--Computer Interface
Jan 15, 2025Seasickness is a prevalent issue that adversely impacts both passenger experiences and the operational efficiency of maritime crews. While techniques that redirect attention have proven effective in alleviating motion sickness symptoms in terrestrial environments, applying similar strategies to manage seasickness poses unique challenges due to the prolonged and intense motion environment associated with maritime travel. In this study, we propose a mindfulness brain-computer interface (BCI), specifically designed to redirect attention with the aim of mitigating seasickness symptoms in real-world settings. Our system utilizes a single-channel headband to capture prefrontal EEG signals, which are then wirelessly transmitted to computing devices for the assessment of mindfulness states. The results are transferred into real-time feedback as mindfulness scores and audiovisual stimuli, facilitating a shift in attentional focus from physiological discomfort to mindfulness practices. A total of 43 individuals participated in a real-world maritime experiment consisted of three sessions: a real-feedback mindfulness session, a resting session, and a pseudofeedback mindfulness session. Notably, 81.39% of participants reported that the mindfulness BCI intervention was effective, and there was a significant reduction in the severity of seasickness, as measured by the Misery Scale (MISC). Furthermore, EEG analysis revealed a decrease in the theta/beta ratio, corresponding with the alleviation of seasickness symptoms. A decrease in overall EEG band power during the real-feedback mindfulness session suggests that the mindfulness BCI fosters a more tranquil and downregulated state of brain activity. Together, this study presents a novel nonpharmacological, portable, and effective approach for seasickness intervention, with the potential to enhance the cruising experience for both passengers and crews.
OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
Dec 10, 2024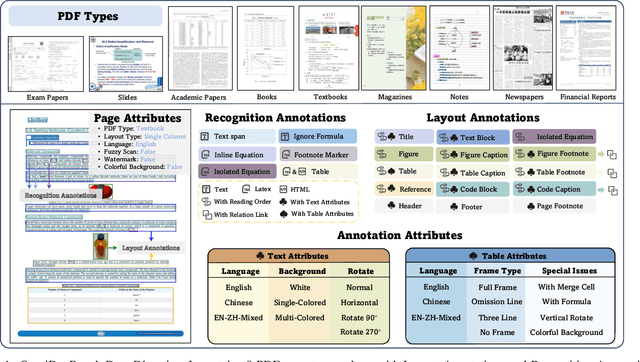
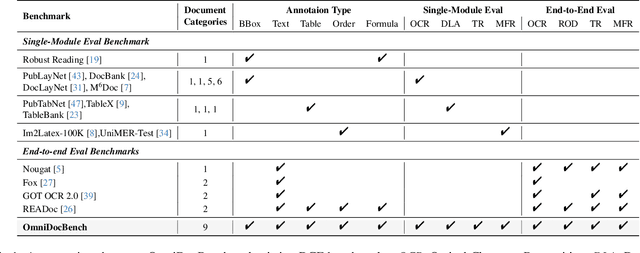
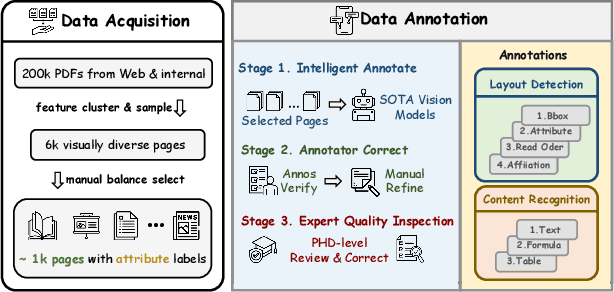
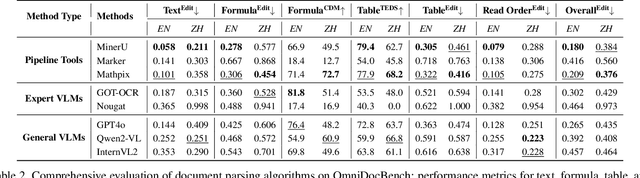
Document content extraction is crucial in computer vision, especially for meeting the high-quality data needs of large language models (LLMs) and retrieval-augmented generation (RAG) technologies. However, current document parsing methods suffer from significant limitations in terms of diversity and comprehensive evaluation. To address these challenges, we introduce OmniDocBench, a novel multi-source benchmark designed to advance automated document content extraction. OmniDocBench includes a meticulously curated and annotated high-quality evaluation dataset comprising nine diverse document types, such as academic papers, textbooks, slides, among others. Our benchmark provides a flexible and comprehensive evaluation framework with 19 layout category labels and 14 attribute labels, enabling multi-level assessments across entire datasets, individual modules, or specific data types. Using OmniDocBench, we perform an exhaustive comparative analysis of existing modular pipelines and multimodal end-to-end methods, highlighting their limitations in handling document diversity and ensuring fair evaluation. OmniDocBench establishes a robust, diverse, and fair evaluation standard for the document content extraction field, offering crucial insights for future advancements and fostering the development of document parsing technologies. The codes and dataset is available in https://github.com/opendatalab/OmniDocBench.
GeoAI-Enhanced Community Detection on Spatial Networks with Graph Deep Learning
Nov 23, 2024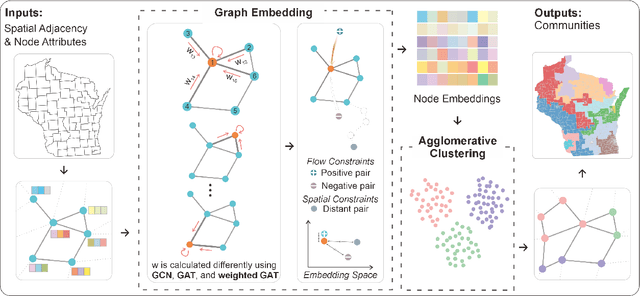
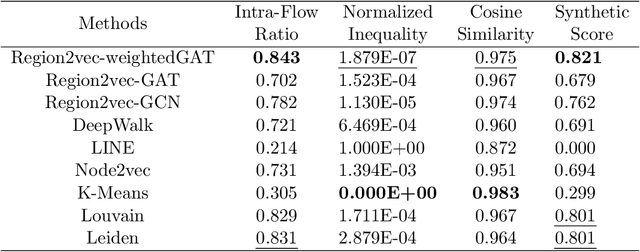
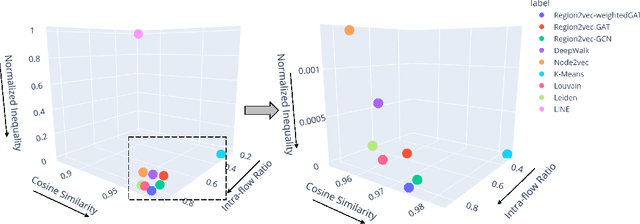
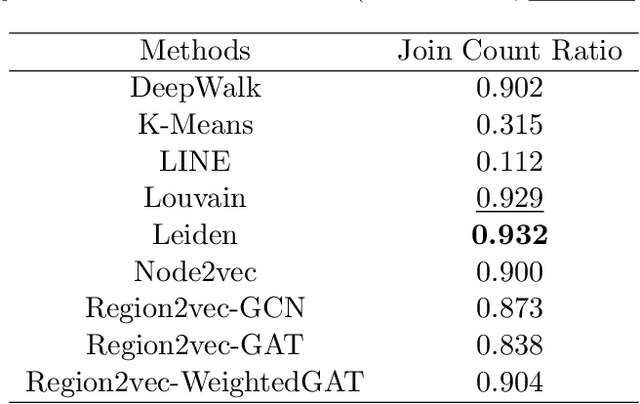
Spatial networks are useful for modeling geographic phenomena where spatial interaction plays an important role. To analyze the spatial networks and their internal structures, graph-based methods such as community detection have been widely used. Community detection aims to extract strongly connected components from the network and reveal the hidden relationships between nodes, but they usually do not involve the attribute information. To consider edge-based interactions and node attributes together, this study proposed a family of GeoAI-enhanced unsupervised community detection methods called region2vec based on Graph Attention Networks (GAT) and Graph Convolutional Networks (GCN). The region2vec methods generate node neural embeddings based on attribute similarity, geographic adjacency and spatial interactions, and then extract network communities based on node embeddings using agglomerative clustering. The proposed GeoAI-based methods are compared with multiple baselines and perform the best when one wants to maximize node attribute similarity and spatial interaction intensity simultaneously within the spatial network communities. It is further applied in the shortage area delineation problem in public health and demonstrates its promise in regionalization problems.
* 25 pages, 5 figures
An Enhanced-State Reinforcement Learning Algorithm for Multi-Task Fusion in Large-Scale Recommender Systems
Sep 18, 2024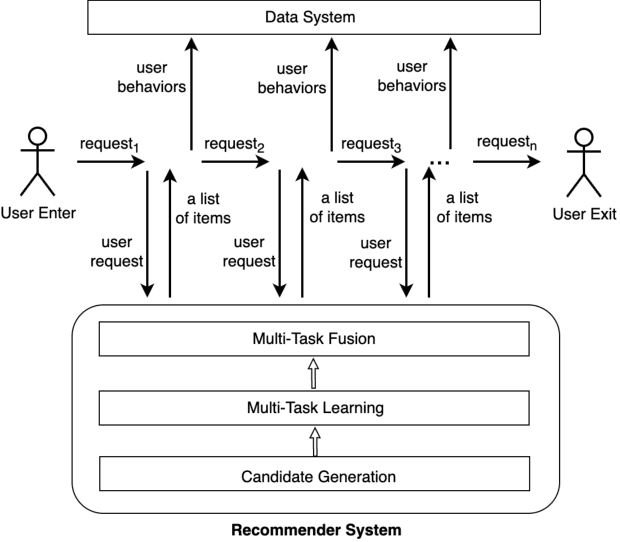
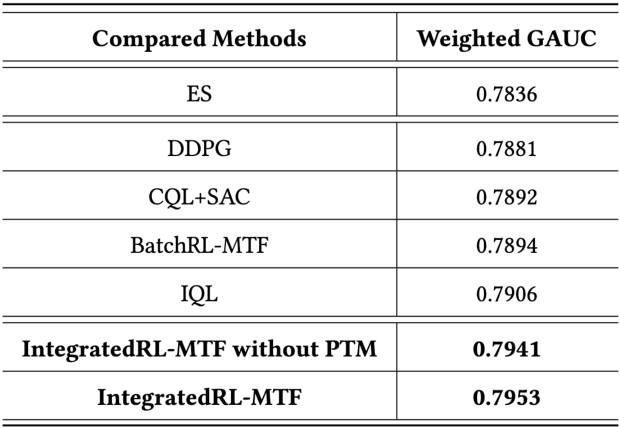
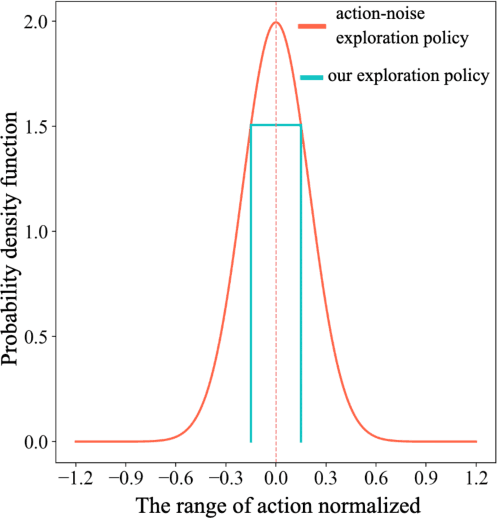
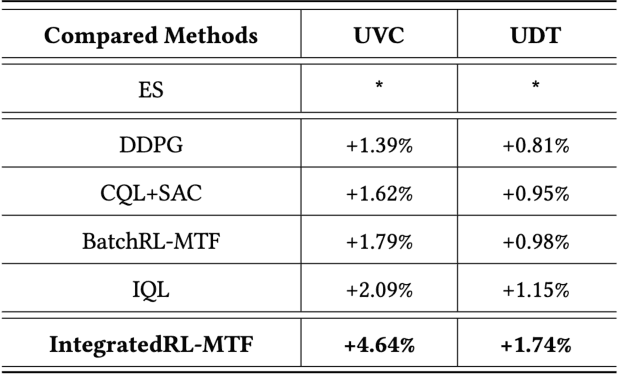
As the last key stage of Recommender Systems (RSs), Multi-Task Fusion (MTF) is in charge of combining multiple scores predicted by Multi-Task Learning (MTL) into a final score to maximize user satisfaction, which decides the ultimate recommendation results. In recent years, to maximize long-term user satisfaction within a recommendation session, Reinforcement Learning (RL) is widely used for MTF in large-scale RSs. However, limited by their modeling pattern, all the current RL-MTF methods can only utilize user features as the state to generate actions for each user, but unable to make use of item features and other valuable features, which leads to suboptimal results. Addressing this problem is a challenge that requires breaking through the current modeling pattern of RL-MTF. To solve this problem, we propose a novel method called Enhanced-State RL for MTF in RSs. Unlike the existing methods mentioned above, our method first defines user features, item features, and other valuable features collectively as the enhanced state; then proposes a novel actor and critic learning process to utilize the enhanced state to make much better action for each user-item pair. To the best of our knowledge, this novel modeling pattern is being proposed for the first time in the field of RL-MTF. We conduct extensive offline and online experiments in a large-scale RS. The results demonstrate that our model outperforms other models significantly. Enhanced-State RL has been fully deployed in our RS more than half a year, improving +3.84% user valid consumption and +0.58% user duration time compared to baseline.
P/D-Serve: Serving Disaggregated Large Language Model at Scale
Aug 15, 2024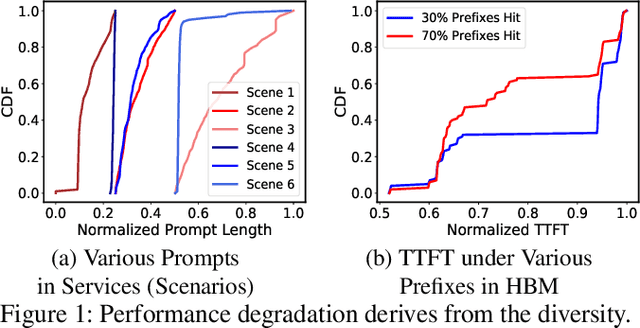
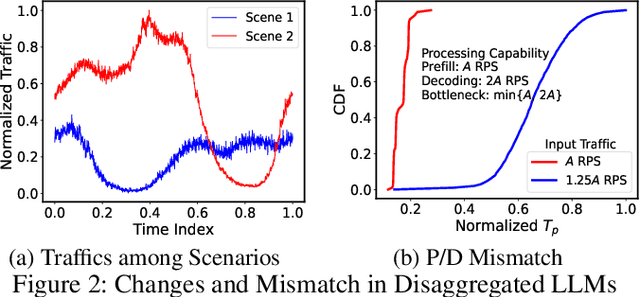
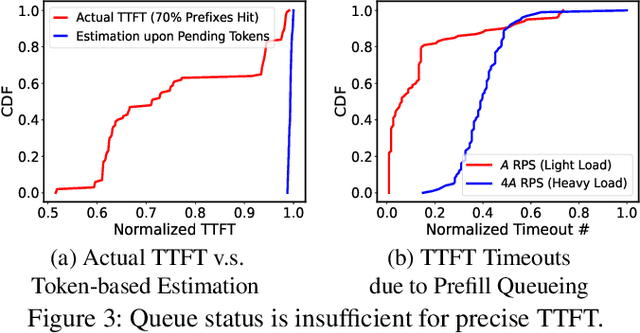
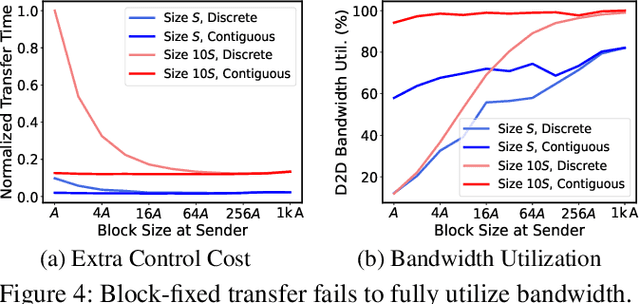
Serving disaggregated large language models (LLMs) over tens of thousands of xPU devices (GPUs or NPUs) with reliable performance faces multiple challenges. 1) Ignoring the diversity (various prefixes and tidal requests), treating all the prompts in a mixed pool is inadequate. To facilitate the similarity per scenario and minimize the inner mismatch on P/D (prefill and decoding) processing, fine-grained organization is required, dynamically adjusting P/D ratios for better performance. 2) Due to inaccurate estimation on workload (queue status or maintained connections), the global scheduler easily incurs unnecessary timeouts in prefill. 3) Block-fixed device-to-device (D2D) KVCache transfer over cluster-level RDMA (remote direct memory access) fails to achieve desired D2D utilization as expected. To overcome previous problems, this paper proposes an end-to-end system P/D-Serve, complying with the paradigm of MLOps (machine learning operations), which models end-to-end (E2E) P/D performance and enables: 1) fine-grained P/D organization, mapping the service with RoCE (RDMA over converged ethernet) as needed, to facilitate similar processing and dynamic adjustments on P/D ratios; 2) on-demand forwarding upon rejections for idle prefill, decoupling the scheduler from regular inaccurate reports and local queues, to avoid timeouts in prefill; and 3) efficient KVCache transfer via optimized D2D access. P/D-Serve is implemented upon Ascend and MindSpore, has been deployed over tens of thousands of NPUs for more than eight months in commercial use, and further achieves 60\%, 42\% and 46\% improvements on E2E throughput, time-to-first-token (TTFT) SLO (service level objective) and D2D transfer time. As the E2E system with optimizations, P/D-Serve achieves 6.7x increase on throughput, compared with aggregated LLMs.
An Off-Policy Reinforcement Learning Algorithm Customized for Multi-Task Fusion in Large-Scale Recommender Systems
Apr 19, 2024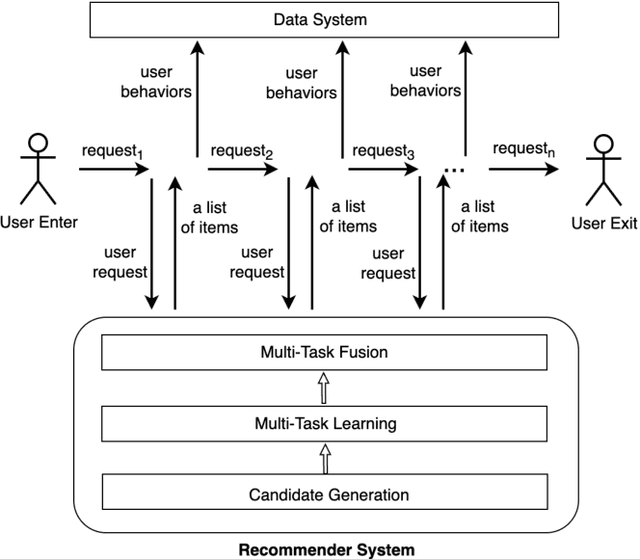
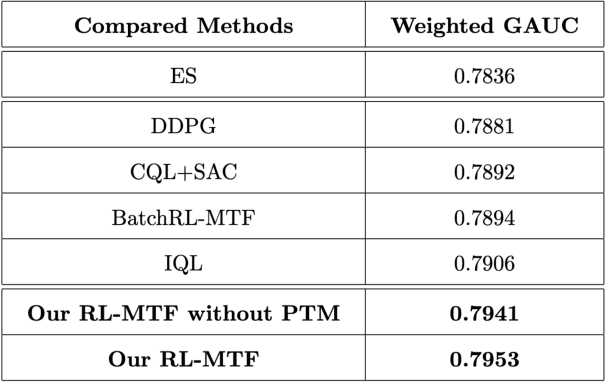
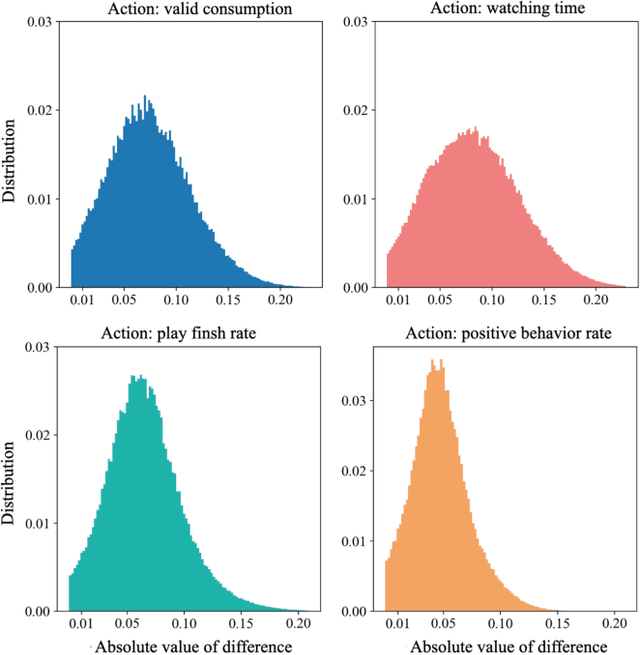
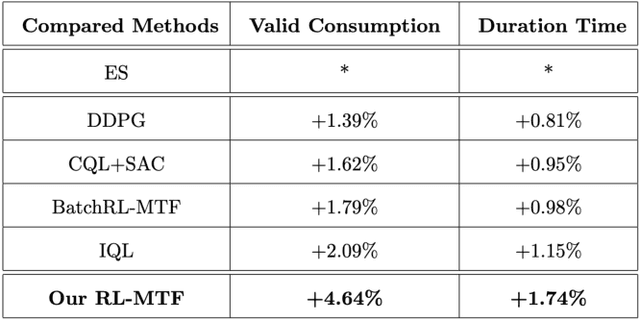
Recommender Systems (RSs) are widely used to provide personalized recommendation service. As the last critical stage of RSs, Multi-Task Fusion (MTF) is responsible for combining multiple scores outputted by Multi-Task Learning (MTL) into a final score to maximize user satisfaction, which determines the ultimate recommendation results. Recently, to optimize long-term user satisfaction within a recommendation session, Reinforcement Learning (RL) is used for MTF in the industry. However, the off-policy RL algorithms used for MTF so far have the following severe problems: 1) to avoid out-of-distribution (OOD) problem, their constraints are overly strict, which seriously damage their performance; 2) they are unaware of the exploration policy used for producing training data and never interact with real environment, so only suboptimal policy can be learned; 3) the traditional exploration policies are inefficient and hurt user experience. To solve the above problems, we propose a novel off-policy RL algorithm customized for MTF in large-scale RSs. Our RL-MTF algorithm integrates off-policy RL model with our online exploration policy to relax overstrict and complicated constraints, which significantly improves the performance of our RL model. We also design an extremely efficient exploration policy, which eliminates low-value exploration space and focuses on exploring potential high-value state-action pairs. Moreover, we adopt progressive training mode to further enhance our RL model's performance with the help of our exploration policy. We conduct extensive offline and online experiments in the short video channel of Tencent News. The results demonstrate that our RL-MTF model outperforms other models remarkably. Our RL-MTF model has been fully deployed in the short video channel of Tencent News for about one year. In addition, our solution has been used in other large-scale RSs in Tencent.
Alleviating neighbor bias: augmenting graph self-supervise learning with structural equivalent positive samples
Dec 08, 2022In recent years, using a self-supervised learning framework to learn the general characteristics of graphs has been considered a promising paradigm for graph representation learning. The core of self-supervised learning strategies for graph neural networks lies in constructing suitable positive sample selection strategies. However, existing GNNs typically aggregate information from neighboring nodes to update node representations, leading to an over-reliance on neighboring positive samples, i.e., homophilous samples; while ignoring long-range positive samples, i.e., positive samples that are far apart on the graph but structurally equivalent samples, a problem we call "neighbor bias." This neighbor bias can reduce the generalization performance of GNNs. In this paper, we argue that the generalization properties of GNNs should be determined by combining homogeneous samples and structurally equivalent samples, which we call the "GC combination hypothesis." Therefore, we propose a topological signal-driven self-supervised method. It uses a topological information-guided structural equivalence sampling strategy. First, we extract multiscale topological features using persistent homology. Then we compute the structural equivalence of node pairs based on their topological features. In particular, we design a topological loss function to pull in non-neighboring node pairs with high structural equivalence in the representation space to alleviate neighbor bias. Finally, we use the joint training mechanism to adjust the effect of structural equivalence on the model to fit datasets with different characteristics. We conducted experiments on the node classification task across seven graph datasets. The results show that the model performance can be effectively improved using a strategy of topological signal enhancement.