 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal invariant geographic network representations with feature and structural distribution shifts
Mar 25, 2025The existing methods learn geographic network representations through deep graph neural networks (GNNs) based on the i.i.d. assumption. However, the spatial heterogeneity and temporal dynamics of geographic data make the out-of-distribution (OOD) generalisation problem particularly salient. The latter are particularly sensitive to distribution shifts (feature and structural shifts) between testing and training data and are the main causes of the OOD generalisation problem. Spurious correlations are present between invariant and background representations due to selection biases and environmental effects, resulting in the model extremes being more likely to learn background representations. The existing approaches focus on background representation changes that are determined by shifts in the feature distributions of nodes in the training and test data while ignoring changes in the proportional distributions of heterogeneous and homogeneous neighbour nodes, which we refer to as structural distribution shifts. We propose a feature-structure mixed invariant representation learning (FSM-IRL) model that accounts for both feature distribution shifts and structural distribution shifts. To address structural distribution shifts, we introduce a sampling method based on causal attention, encouraging the model to identify nodes possessing strong causal relationships with labels or nodes that are more similar to the target node. Inspired by the Hilbert-Schmidt independence criterion, we implement a reweighting strategy to maximise the orthogonality of the node representations, thereby mitigating the spurious correlations among the node representations and suppressing the learning of background representations. Our experiments demonstrate that FSM-IRL exhibits strong learning capabilities on both geographic and social network datasets in OOD scenarios.
* 15 pages, 3 figures, 8 tables
STDCformer: A Transformer-Based Model with a Spatial-Temporal Causal De-Confounding Strategy for Crowd Flow Prediction
Dec 04, 2024



Existing works typically treat spatial-temporal prediction as the task of learning a function $F$ to transform historical observations to future observations. We further decompose this cross-time transformation into three processes: (1) Encoding ($E$): learning the intrinsic representation of observations, (2) Cross-Time Mapping ($M$): transforming past representations into future representations, and (3) Decoding ($D$): reconstructing future observations from the future representations. From this perspective, spatial-temporal prediction can be viewed as learning $F = E \cdot M \cdot D$, which includes learning the space transformations $\left\{{E},{D}\right\}$ between the observation space and the hidden representation space, as well as the spatial-temporal mapping $M$ from future states to past states within the representation space. This leads to two key questions: \textbf{Q1: What kind of representation space allows for mapping the past to the future? Q2: How to achieve map the past to the future within the representation space?} To address Q1, we propose a Spatial-Temporal Backdoor Adjustment strategy, which learns a Spatial-Temporal De-Confounded (STDC) representation space and estimates the de-confounding causal effect of historical data on future data. This causal relationship we captured serves as the foundation for subsequent spatial-temporal mapping. To address Q2, we design a Spatial-Temporal Embedding (STE) that fuses the information of temporal and spatial confounders, capturing the intrinsic spatial-temporal characteristics of the representations. Additionally, we introduce a Cross-Time Attention mechanism, which queries the attention between the future and the past to guide spatial-temporal mapping.
LSTTN: A Long-Short Term Transformer-based Spatio-temporal Neural Network for Traffic Flow Forecasting
Mar 25, 2024



Accurate traffic forecasting is a fundamental problem in intelligent transportation systems and learning long-range traffic representations with key information through spatiotemporal graph neural networks (STGNNs) is a basic assumption of current traffic flow prediction models. However, due to structural limitations, existing STGNNs can only utilize short-range traffic flow data; therefore, the models cannot adequately learn the complex trends and periodic features in traffic flow. Besides, it is challenging to extract the key temporal information from the long historical traffic series and obtain a compact representation. To solve the above problems, we propose a novel LSTTN (Long-Short Term Transformer-based Network) framework comprehensively considering the long- and short-term features in historical traffic flow. First, we employ a masked subseries Transformer to infer the content of masked subseries from a small portion of unmasked subseries and their temporal context in a pretraining manner, forcing the model to efficiently learn compressed and contextual subseries temporal representations from long historical series. Then, based on the learned representations, long-term trend is extracted by using stacked 1D dilated convolution layers, and periodic features are extracted by dynamic graph convolution layers. For the difficulties in making time-step level prediction, LSTTN adopts a short-term trend extractor to learn fine-grained short-term temporal features. Finally, LSTTN fuses the long-term trend, periodic features and short-term features to obtain the prediction results. Experiments on four real-world datasets show that in 60-minute-ahead long-term forecasting, the LSTTN model achieves a minimum improvement of 5.63\% and a maximum improvement of 16.78\% over baseline models. The source code is available at https://github.com/GeoX-Lab/LSTTN.
* 15 pages, 10 figures, 6 tables
CAT: A Causally Graph Attention Network for Trimming Heterophilic Graph
Dec 15, 2023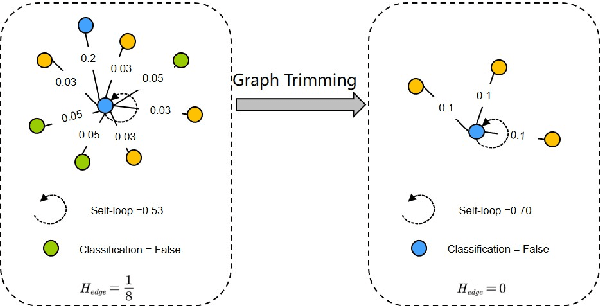
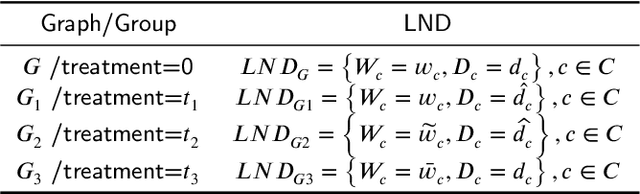

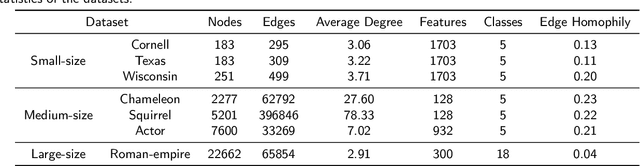
Local Attention-guided Message Passing Mechanism (LAMP) adopted in Graph Attention Networks (GATs) is designed to adaptively learn the importance of neighboring nodes for better local aggregation on the graph, which can bring the representations of similar neighbors closer effectively, thus showing stronger discrimination ability. However, existing GATs suffer from a significant discrimination ability decline in heterophilic graphs because the high proportion of dissimilar neighbors can weaken the self-attention of the central node, jointly resulting in the deviation of the central node from similar nodes in the representation space. This kind of effect generated by neighboring nodes is called the Distraction Effect (DE) in this paper. To estimate and weaken the DE of neighboring nodes, we propose a Causally graph Attention network for Trimming heterophilic graph (CAT). To estimate the DE, since the DE are generated through two paths (grab the attention assigned to neighbors and reduce the self-attention of the central node), we use Total Effect to model DE, which is a kind of causal estimand and can be estimated from intervened data; To weaken the DE, we identify the neighbors with the highest DE (we call them Distraction Neighbors) and remove them. We adopt three representative GATs as the base model within the proposed CAT framework and conduct experiments on seven heterophilic datasets in three different sizes. Comparative experiments show that CAT can improve the node classification accuracy of all base GAT models. Ablation experiments and visualization further validate the enhancement of discrimination ability brought by CAT. The source code is available at https://github.com/GeoX-Lab/CAT.
* 24 pages, 17 figures, 4 tables
STGC-GNNs: A GNN-based traffic prediction framework with a spatial-temporal Granger causality graph
Oct 30, 2022



The key to traffic prediction is to accurately depict the temporal dynamics of traffic flow traveling in a road network, so it is important to model the spatial dependence of the road network. The essence of spatial dependence is to accurately describe how traffic information transmission is affected by other nodes in the road network, and the GNN-based traffic prediction model, as a benchmark for traffic prediction, has become the most common method for the ability to model spatial dependence by transmitting traffic information with the message passing mechanism. However, existing methods model a local and static spatial dependence, which cannot transmit the global-dynamic traffic information (GDTi) required for long-term prediction. The challenge is the difficulty of detecting the precise transmission of GDTi due to the uncertainty of individual transport, especially for long-term transmission. In this paper, we propose a new hypothesis\: GDTi behaves macroscopically as a transmitting causal relationship (TCR) underlying traffic flow, which remains stable under dynamic changing traffic flow. We further propose spatial-temporal Granger causality (STGC) to express TCR, which models global and dynamic spatial dependence. To model global transmission, we model the causal order and causal lag of TCRs global transmission by a spatial-temporal alignment algorithm. To capture dynamic spatial dependence, we approximate the stable TCR underlying dynamic traffic flow by a Granger causality test. The experimental results on three backbone models show that using STGC to model the spatial dependence has better results than the original model for 45 min and 1 h long-term prediction.
Augmentation-Free Graph Contrastive Learning of Invariant-Discriminative Representations
Oct 15, 2022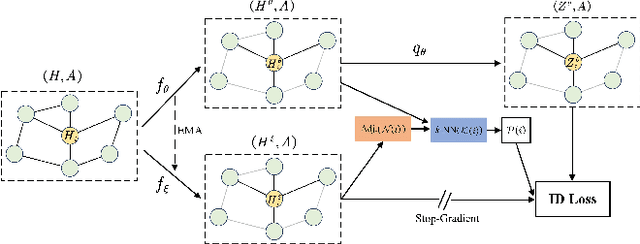
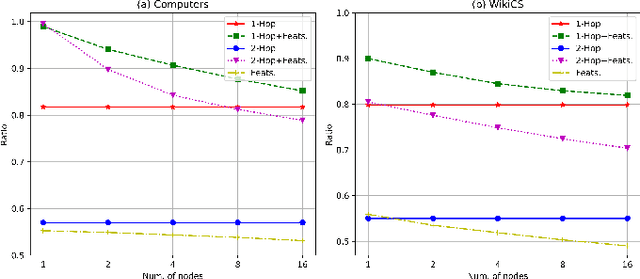
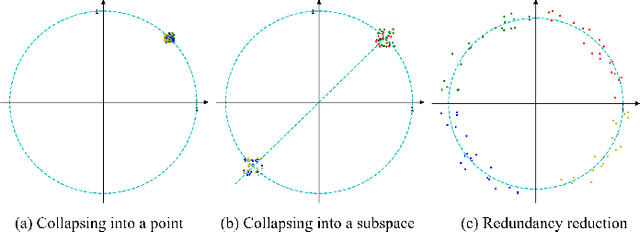

The pretasks are mainly built on mutual information estimation, which requires data augmentation to construct positive samples with similar semantics to learn invariant signals and negative samples with dissimilar semantics in order to empower representation discriminability. However, an appropriate data augmentation configuration depends heavily on lots of empirical trials such as choosing the compositions of data augmentation techniques and the corresponding hyperparameter settings. We propose an augmentation-free graph contrastive learning method, invariant-discriminative graph contrastive learning (iGCL), that does not intrinsically require negative samples. iGCL designs the invariant-discriminative loss (ID loss) to learn invariant and discriminative representations. On the one hand, ID loss learns invariant signals by directly minimizing the mean square error between the target samples and positive samples in the representation space. On the other hand, ID loss ensures that the representations are discriminative by an orthonormal constraint forcing the different dimensions of representations to be independent of each other. This prevents representations from collapsing to a point or subspace. Our theoretical analysis explains the effectiveness of ID loss from the perspectives of the redundancy reduction criterion, canonical correlation analysis, and information bottleneck principle. The experimental results demonstrate that iGCL outperforms all baselines on 5 node classification benchmark datasets. iGCL also shows superior performance for different label ratios and is capable of resisting graph attacks, which indicates that iGCL has excellent generalization and robustness.