 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Knowledge Transfer Learning as Graph Matching Based on Optimal Transport for ASR
May 19, 2025Transferring linguistic knowledge from a pretrained language model (PLM) to acoustic feature learning has proven effective in enhancing end-to-end automatic speech recognition (E2E-ASR). However, aligning representations between linguistic and acoustic modalities remains a challenge due to inherent modality gaps. Optimal transport (OT) has shown promise in mitigating these gaps by minimizing the Wasserstein distance (WD) between linguistic and acoustic feature distributions. However, previous OT-based methods overlook structural relationships, treating feature vectors as unordered sets. To address this, we propose Graph Matching Optimal Transport (GM-OT), which models linguistic and acoustic sequences as structured graphs. Nodes represent feature embeddings, while edges capture temporal and sequential relationships. GM-OT minimizes both WD (between nodes) and Gromov-Wasserstein distance (GWD) (between edges), leading to a fused Gromov-Wasserstein distance (FGWD) formulation. This enables structured alignment and more efficient knowledge transfer compared to existing OT-based approaches. Theoretical analysis further shows that prior OT-based methods in linguistic knowledge transfer can be viewed as a special case within our GM-OT framework. We evaluate GM-OT on Mandarin ASR using a CTC-based E2E-ASR system with a PLM for knowledge transfer. Experimental results demonstrate significant performance gains over state-of-the-art models, validating the effectiveness of our approach.
Retrieval-Augmented Speech Recognition Approach for Domain Challenges
Feb 21, 2025
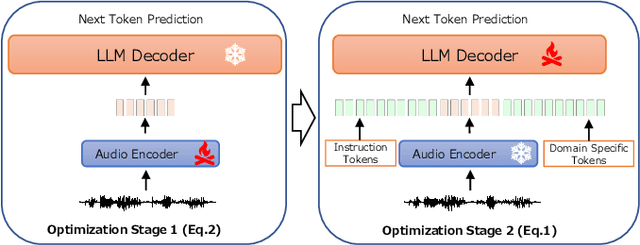


Speech recognition systems often face challenges due to domain mismatch, particularly in real-world applications where domain-specific data is unavailable because of data accessibility and confidentiality constraints. Inspired by Retrieval-Augmented Generation (RAG) techniques for large language models (LLMs), this paper introduces a LLM-based retrieval-augmented speech recognition method that incorporates domain-specific textual data at the inference stage to enhance recognition performance. Rather than relying on domain-specific textual data during the training phase, our model is trained to learn how to utilize textual information provided in prompts for LLM decoder to improve speech recognition performance. Benefiting from the advantages of the RAG retrieval mechanism, our approach efficiently accesses locally available domain-specific documents, ensuring a convenient and effective process for solving domain mismatch problems. Experiments conducted on the CSJ database demonstrate that the proposed method significantly improves speech recognition accuracy and achieves state-of-the-art results on the CSJ dataset, even without relying on the full training data.
STDCformer: A Transformer-Based Model with a Spatial-Temporal Causal De-Confounding Strategy for Crowd Flow Prediction
Dec 04, 2024



Existing works typically treat spatial-temporal prediction as the task of learning a function $F$ to transform historical observations to future observations. We further decompose this cross-time transformation into three processes: (1) Encoding ($E$): learning the intrinsic representation of observations, (2) Cross-Time Mapping ($M$): transforming past representations into future representations, and (3) Decoding ($D$): reconstructing future observations from the future representations. From this perspective, spatial-temporal prediction can be viewed as learning $F = E \cdot M \cdot D$, which includes learning the space transformations $\left\{{E},{D}\right\}$ between the observation space and the hidden representation space, as well as the spatial-temporal mapping $M$ from future states to past states within the representation space. This leads to two key questions: \textbf{Q1: What kind of representation space allows for mapping the past to the future? Q2: How to achieve map the past to the future within the representation space?} To address Q1, we propose a Spatial-Temporal Backdoor Adjustment strategy, which learns a Spatial-Temporal De-Confounded (STDC) representation space and estimates the de-confounding causal effect of historical data on future data. This causal relationship we captured serves as the foundation for subsequent spatial-temporal mapping. To address Q2, we design a Spatial-Temporal Embedding (STE) that fuses the information of temporal and spatial confounders, capturing the intrinsic spatial-temporal characteristics of the representations. Additionally, we introduce a Cross-Time Attention mechanism, which queries the attention between the future and the past to guide spatial-temporal mapping.
Temporal Order Preserved Optimal Transport-based Cross-modal Knowledge Transfer Learning for ASR
Sep 03, 2024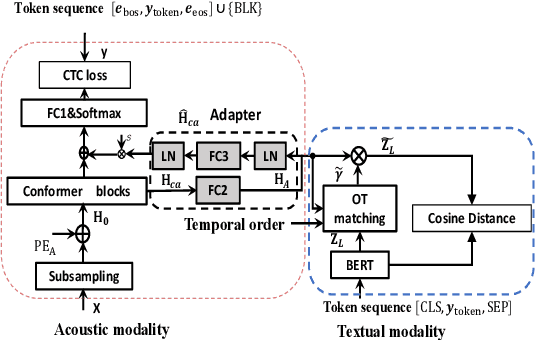


Transferring linguistic knowledge from a pretrained language model (PLM) to an acoustic model has been shown to greatly improve the performance of automatic speech recognition (ASR). However, due to the heterogeneous feature distributions in cross-modalities, designing an effective model for feature alignment and knowledge transfer between linguistic and acoustic sequences remains a challenging task. Optimal transport (OT), which efficiently measures probability distribution discrepancies, holds great potential for aligning and transferring knowledge between acoustic and linguistic modalities. Nonetheless, the original OT treats acoustic and linguistic feature sequences as two unordered sets in alignment and neglects temporal order information during OT coupling estimation. Consequently, a time-consuming pretraining stage is required to learn a good alignment between the acoustic and linguistic representations. In this paper, we propose a Temporal Order Preserved OT (TOT)-based Cross-modal Alignment and Knowledge Transfer (CAKT) (TOT-CAKT) for ASR. In the TOT-CAKT, local neighboring frames of acoustic sequences are smoothly mapped to neighboring regions of linguistic sequences, preserving their temporal order relationship in feature alignment and matching. With the TOT-CAKT model framework, we conduct Mandarin ASR experiments with a pretrained Chinese PLM for linguistic knowledge transfer. Our results demonstrate that the proposed TOT-CAKT significantly improves ASR performance compared to several state-of-the-art models employing linguistic knowledge transfer, and addresses the weaknesses of the original OT-based method in sequential feature alignment for ASR.
Generative linguistic representation for spoken language identification
Dec 18, 2023Effective extraction and application of linguistic features are central to the enhancement of spoken Language IDentification (LID) performance. With the success of recent large models, such as GPT and Whisper, the potential to leverage such pre-trained models for extracting linguistic features for LID tasks has become a promising area of research. In this paper, we explore the utilization of the decoder-based network from the Whisper model to extract linguistic features through its generative mechanism for improving the classification accuracy in LID tasks. We devised two strategies - one based on the language embedding method and the other focusing on direct optimization of LID outputs while simultaneously enhancing the speech recognition tasks. We conducted experiments on the large-scale multilingual datasets MLS, VoxLingua107, and CommonVoice to test our approach. The experimental results demonstrated the effectiveness of the proposed method on both in-domain and out-of-domain datasets for LID tasks.
Speaker Mask Transformer for Multi-talker Overlapped Speech Recognition
Dec 18, 2023Multi-talker overlapped speech recognition remains a significant challenge, requiring not only speech recognition but also speaker diarization tasks to be addressed. In this paper, to better address these tasks, we first introduce speaker labels into an autoregressive transformer-based speech recognition model to support multi-speaker overlapped speech recognition. Then, to improve speaker diarization, we propose a novel speaker mask branch to detection the speech segments of individual speakers. With the proposed model, we can perform both speech recognition and speaker diarization tasks simultaneously using a single model. Experimental results on the LibriSpeech-based overlapped dataset demonstrate the effectiveness of the proposed method in both speech recognition and speaker diarization tasks, particularly enhancing the accuracy of speaker diarization in relatively complex multi-talker scenarios.
Neural domain alignment for spoken language recognition based on optimal transport
Oct 20, 2023



Domain shift poses a significant challenge in cross-domain spoken language recognition (SLR) by reducing its effectiveness. Unsupervised domain adaptation (UDA) algorithms have been explored to address domain shifts in SLR without relying on class labels in the target domain. One successful UDA approach focuses on learning domain-invariant representations to align feature distributions between domains. However, disregarding the class structure during the learning process of domain-invariant representations can result in over-alignment, negatively impacting the classification task. To overcome this limitation, we propose an optimal transport (OT)-based UDA algorithm for a cross-domain SLR, leveraging the distribution geometry structure-aware property of OT. An OT-based discrepancy measure on a joint distribution over feature and label information is considered during domain alignment in OT-based UDA. Our previous study discovered that completely aligning the distributions between the source and target domains can introduce a negative transfer, where classes or irrelevant classes from the source domain map to a different class in the target domain during distribution alignment. This negative transfer degrades the performance of the adaptive model. To mitigate this issue, we introduce coupling-weighted partial optimal transport (POT) within our UDA framework for SLR, where soft weighting on the OT coupling based on transport cost is adaptively set during domain alignment. A cross-domain SLR task was used in the experiments to evaluate the proposed UDA. The results demonstrated that our proposed UDA algorithm significantly improved the performance over existing UDA algorithms in a cross-channel SLR task.
Hierarchical Cross-Modality Knowledge Transfer with Sinkhorn Attention for CTC-based ASR
Sep 28, 2023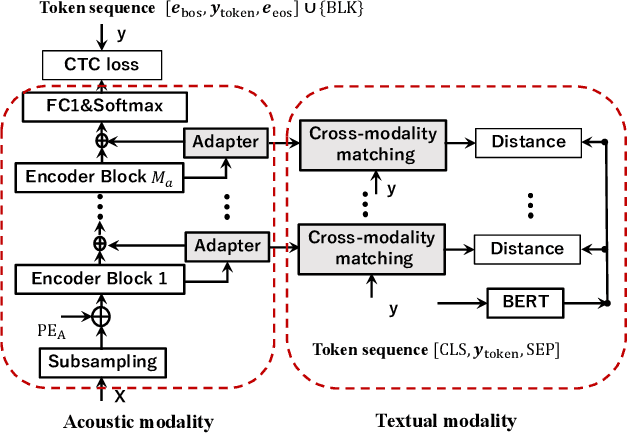

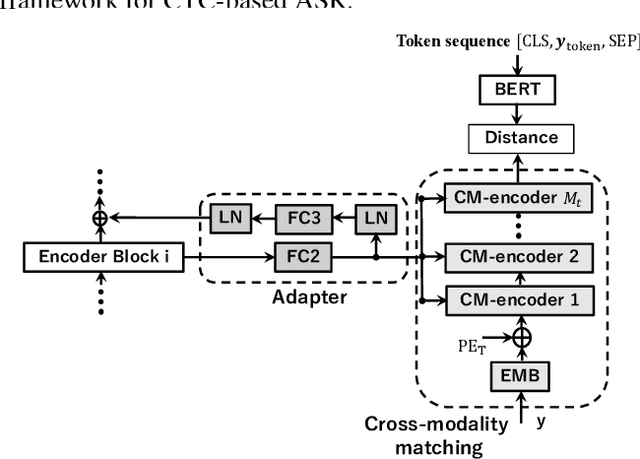

Due to the modality discrepancy between textual and acoustic modeling, efficiently transferring linguistic knowledge from a pretrained language model (PLM) to acoustic encoding for automatic speech recognition (ASR) still remains a challenging task. In this study, we propose a cross-modality knowledge transfer (CMKT) learning framework in a temporal connectionist temporal classification (CTC) based ASR system where hierarchical acoustic alignments with the linguistic representation are applied. Additionally, we propose the use of Sinkhorn attention in cross-modality alignment process, where the transformer attention is a special case of this Sinkhorn attention process. The CMKT learning is supposed to compel the acoustic encoder to encode rich linguistic knowledge for ASR. On the AISHELL-1 dataset, with CTC greedy decoding for inference (without using any language model), we achieved state-of-the-art performance with 3.64% and 3.94% character error rates (CERs) for the development and test sets, which corresponding to relative improvements of 34.18% and 34.88% compared to the baseline CTC-ASR system, respectively.
Cross-modal Alignment with Optimal Transport for CTC-based ASR
Sep 24, 2023


Temporal connectionist temporal classification (CTC)-based automatic speech recognition (ASR) is one of the most successful end to end (E2E) ASR frameworks. However, due to the token independence assumption in decoding, an external language model (LM) is required which destroys its fast parallel decoding property. Several studies have been proposed to transfer linguistic knowledge from a pretrained LM (PLM) to the CTC based ASR. Since the PLM is built from text while the acoustic model is trained with speech, a cross-modal alignment is required in order to transfer the context dependent linguistic knowledge from the PLM to acoustic encoding. In this study, we propose a novel cross-modal alignment algorithm based on optimal transport (OT). In the alignment process, a transport coupling matrix is obtained using OT, which is then utilized to transform a latent acoustic representation for matching the context-dependent linguistic features encoded by the PLM. Based on the alignment, the latent acoustic feature is forced to encode context dependent linguistic information. We integrate this latent acoustic feature to build conformer encoder-based CTC ASR system. On the AISHELL-1 data corpus, our system achieved 3.96% and 4.27% character error rate (CER) for dev and test sets, respectively, which corresponds to relative improvements of 28.39% and 29.42% compared to the baseline conformer CTC ASR system without cross-modal knowledge transfer.
Pronunciation-aware unique character encoding for RNN Transducer-based Mandarin speech recognition
Jul 29, 2022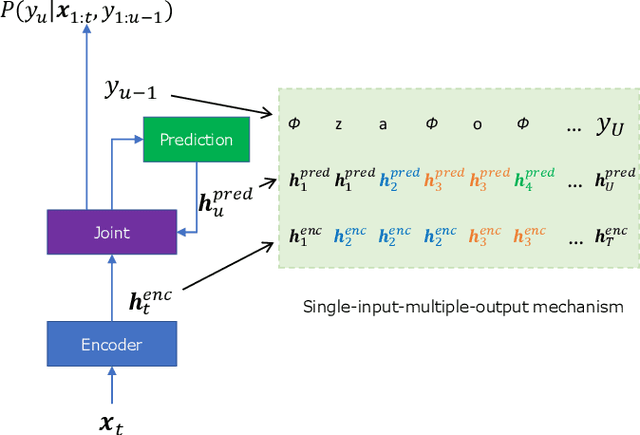
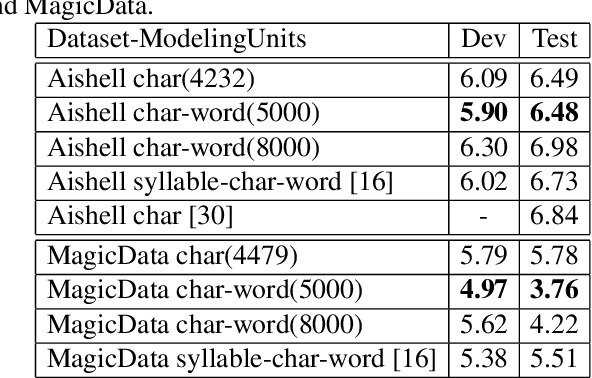

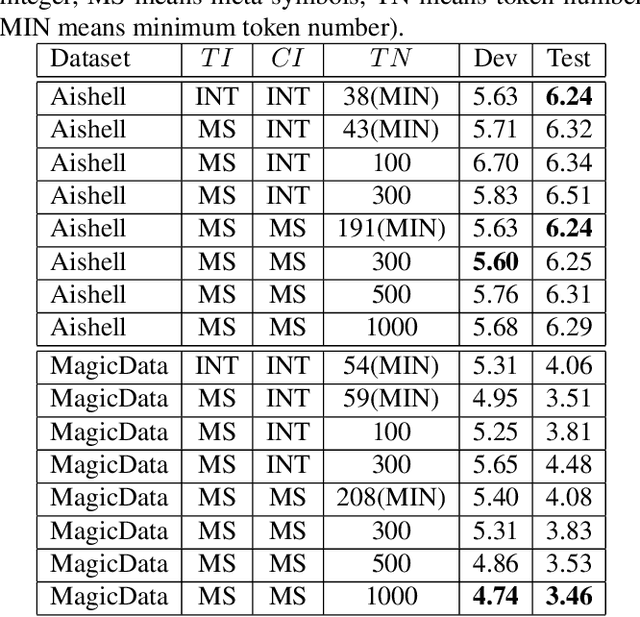
For Mandarin end-to-end (E2E) automatic speech recognition (ASR) tasks, compared to character-based modeling units, pronunciation-based modeling units could improve the sharing of modeling units in model training but meet homophone problems. In this study, we propose to use a novel pronunciation-aware unique character encoding for building E2E RNN-T-based Mandarin ASR systems. The proposed encoding is a combination of pronunciation-base syllable and character index (CI). By introducing the CI, the RNN-T model can overcome the homophone problem while utilizing the pronunciation information for extracting modeling units. With the proposed encoding, the model outputs can be converted into the final recognition result through a one-to-one mapping. We conducted experiments on Aishell and MagicData datasets, and the experimental results showed the effectiveness of the proposed method.