 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransducer-based language embedding for spoken language identification
Paper and Code
Apr 08, 2022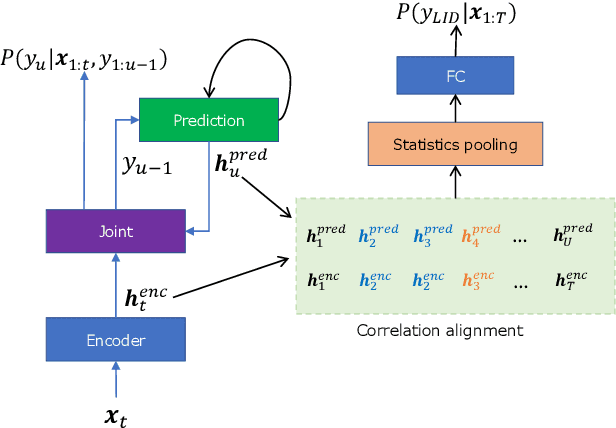


The acoustic and linguistic features are important cues for the spoken language identification (LID) task. Recent advanced LID systems mainly use acoustic features that lack the usage of explicit linguistic feature encoding. In this paper, we propose a novel transducer-based language embedding approach for LID tasks by integrating an RNN transducer model into a language embedding framework. Benefiting from the advantages of the RNN transducer's linguistic representation capability, the proposed method can exploit both phonetically-aware acoustic features and explicit linguistic features for LID tasks. Experiments were carried out on the large-scale multilingual LibriSpeech and VoxLingua107 datasets. Experimental results showed the proposed method significantly improves the performance on LID tasks with 12% to 59% and 16% to 24% relative improvement on in-domain and cross-domain datasets, respectively.