 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Cross-Modality Knowledge Transfer with Sinkhorn Attention for CTC-based ASR
Paper and Code
Sep 28, 2023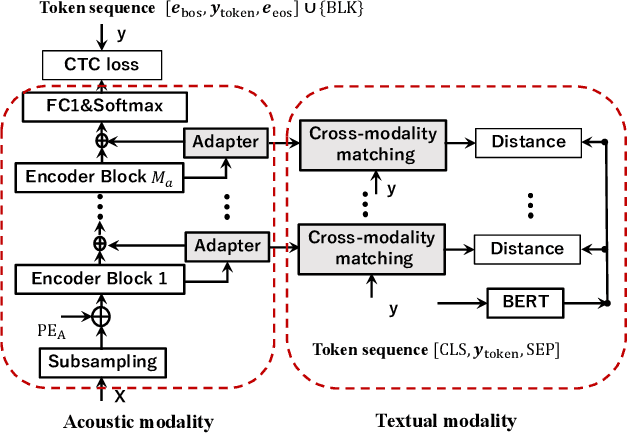

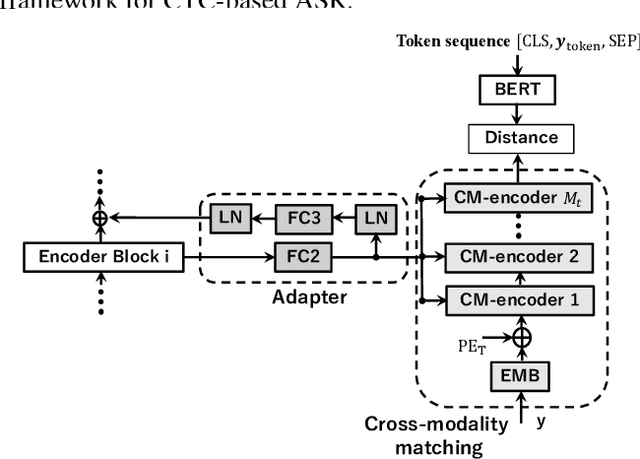

Due to the modality discrepancy between textual and acoustic modeling, efficiently transferring linguistic knowledge from a pretrained language model (PLM) to acoustic encoding for automatic speech recognition (ASR) still remains a challenging task. In this study, we propose a cross-modality knowledge transfer (CMKT) learning framework in a temporal connectionist temporal classification (CTC) based ASR system where hierarchical acoustic alignments with the linguistic representation are applied. Additionally, we propose the use of Sinkhorn attention in cross-modality alignment process, where the transformer attention is a special case of this Sinkhorn attention process. The CMKT learning is supposed to compel the acoustic encoder to encode rich linguistic knowledge for ASR. On the AISHELL-1 dataset, with CTC greedy decoding for inference (without using any language model), we achieved state-of-the-art performance with 3.64% and 3.94% character error rates (CERs) for the development and test sets, which corresponding to relative improvements of 34.18% and 34.88% compared to the baseline CTC-ASR system, respectively.