 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWATCH: Adaptive Monitoring for AI Deployments via Weighted-Conformal Martingales
May 12, 2025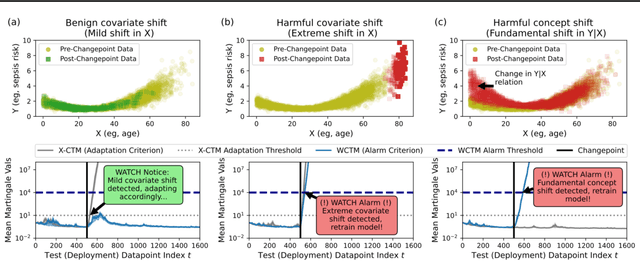
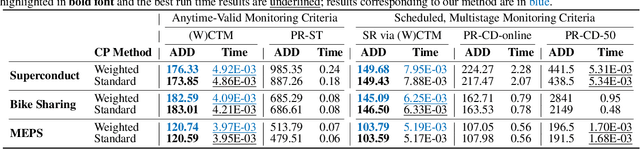
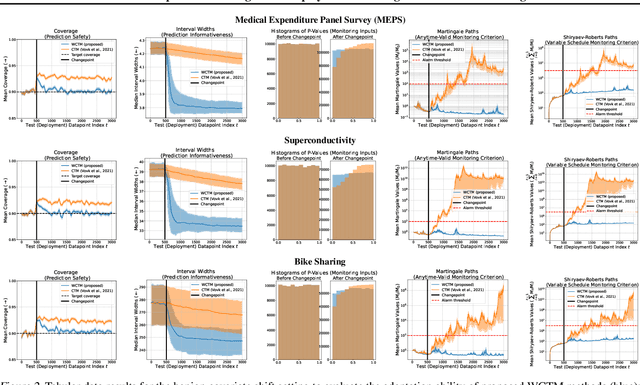
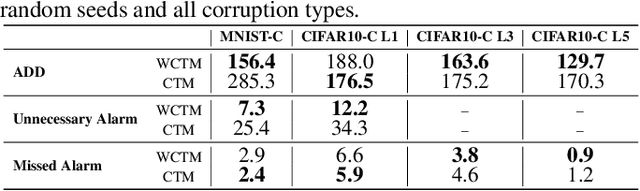
Responsibly deploying artificial intelligence (AI) / machine learning (ML) systems in high-stakes settings arguably requires not only proof of system reliability, but moreover continual, post-deployment monitoring to quickly detect and address any unsafe behavior. Statistical methods for nonparametric change-point detection -- especially the tools of conformal test martingales (CTMs) and anytime-valid inference -- offer promising approaches to this monitoring task. However, existing methods are restricted to monitoring limited hypothesis classes or ``alarm criteria'' (such as data shifts that violate certain exchangeability assumptions), do not allow for online adaptation in response to shifts, and/or do not enable root-cause analysis of any degradation. In this paper, we expand the scope of these monitoring methods by proposing a weighted generalization of conformal test martingales (WCTMs), which lay a theoretical foundation for online monitoring for any unexpected changepoints in the data distribution while controlling false-alarms. For practical applications, we propose specific WCTM algorithms that adapt online to mild covariate shifts (in the marginal input distribution) while quickly detecting and diagnosing more severe shifts, such as concept shifts (in the conditional label distribution) or extreme (out-of-support) covariate shifts that cannot be easily adapted to. On real-world datasets, we demonstrate improved performance relative to state-of-the-art baselines.
WATCH: Weighted Adaptive Testing for Changepoint Hypotheses via Weighted-Conformal Martingales
May 07, 2025Responsibly deploying artificial intelligence (AI) / machine learning (ML) systems in high-stakes settings arguably requires not only proof of system reliability, but moreover continual, post-deployment monitoring to quickly detect and address any unsafe behavior. Statistical methods for nonparametric change-point detection -- especially the tools of conformal test martingales (CTMs) and anytime-valid inference -- offer promising approaches to this monitoring task. However, existing methods are restricted to monitoring limited hypothesis classes or ``alarm criteria,'' such as data shifts that violate certain exchangeability assumptions, or do not allow for online adaptation in response to shifts. In this paper, we expand the scope of these monitoring methods by proposing a weighted generalization of conformal test martingales (WCTMs), which lay a theoretical foundation for online monitoring for any unexpected changepoints in the data distribution while controlling false-alarms. For practical applications, we propose specific WCTM algorithms that accommodate online adaptation to mild covariate shifts (in the marginal input distribution) while raising alarms in response to more severe shifts, such as concept shifts (in the conditional label distribution) or extreme (out-of-support) covariate shifts that cannot be easily adapted to. On real-world datasets, we demonstrate improved performance relative to state-of-the-art baselines.
Between Linear and Sinusoidal: Rethinking the Time Encoder in Dynamic Graph Learning
Apr 10, 2025
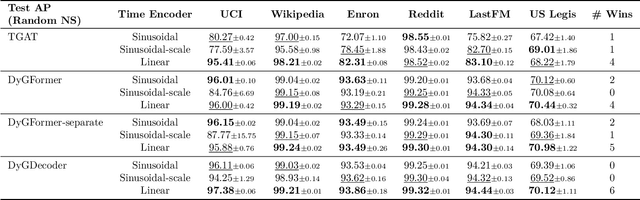


Dynamic graph learning is essential for applications involving temporal networks and requires effective modeling of temporal relationships. Seminal attention-based models like TGAT and DyGFormer rely on sinusoidal time encoders to capture temporal relationships between edge events. In this paper, we study a simpler alternative: the linear time encoder, which avoids temporal information loss caused by sinusoidal functions and reduces the need for high dimensional time encoders. We show that the self-attention mechanism can effectively learn to compute time spans from linear time encodings and extract relevant temporal patterns. Through extensive experiments on six dynamic graph datasets, we demonstrate that the linear time encoder improves the performance of TGAT and DyGFormer in most cases. Moreover, the linear time encoder can lead to significant savings in model parameters with minimal performance loss. For example, compared to a 100-dimensional sinusoidal time encoder, TGAT with a 2-dimensional linear time encoder saves 43% of parameters and achieves higher average precision on five datasets. These results can be readily used to positively impact the design choices of a wide variety of dynamic graph learning architectures. The experimental code is available at: https://github.com/hsinghuan/dg-linear-time.git.
Quadratic Gating Functions in Mixture of Experts: A Statistical Insight
Oct 15, 2024



Mixture of Experts (MoE) models are highly effective in scaling model capacity while preserving computational efficiency, with the gating network, or router, playing a central role by directing inputs to the appropriate experts. In this paper, we establish a novel connection between MoE frameworks and attention mechanisms, demonstrating how quadratic gating can serve as a more expressive and efficient alternative. Motivated by this insight, we explore the implementation of quadratic gating within MoE models, identifying a connection between the self-attention mechanism and the quadratic gating. We conduct a comprehensive theoretical analysis of the quadratic softmax gating MoE framework, showing improved sample efficiency in expert and parameter estimation. Our analysis provides key insights into optimal designs for quadratic gating and expert functions, further elucidating the principles behind widely used attention mechanisms. Through extensive evaluations, we demonstrate that the quadratic gating MoE outperforms the traditional linear gating MoE. Moreover, our theoretical insights have guided the development of a novel attention mechanism, which we validated through extensive experiments. The results demonstrate its favorable performance over conventional models across various tasks.
On Expert Estimation in Hierarchical Mixture of Experts: Beyond Softmax Gating Functions
Oct 03, 2024



With the growing prominence of the Mixture of Experts (MoE) architecture in developing large-scale foundation models, we investigate the Hierarchical Mixture of Experts (HMoE), a specialized variant of MoE that excels in handling complex inputs and improving performance on targeted tasks. Our investigation highlights the advantages of using varied gating functions, moving beyond softmax gating within HMoE frameworks. We theoretically demonstrate that applying tailored gating functions to each expert group allows HMoE to achieve robust results, even when optimal gating functions are applied only at select hierarchical levels. Empirical validation across diverse scenarios supports these theoretical claims. This includes large-scale multimodal tasks, image classification, and latent domain discovery and prediction tasks, where our modified HMoE models show great performance improvements.
Optimizing RAG Techniques for Automotive Industry PDF Chatbots: A Case Study with Locally Deployed Ollama Models
Aug 12, 2024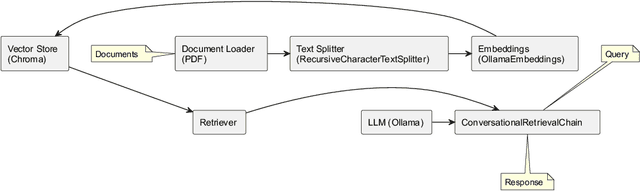
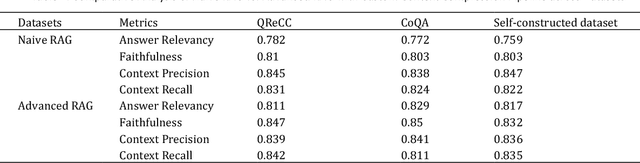
With the growing demand for offline PDF chatbots in automotive industrial production environments, optimizing the deployment of large language models (LLMs) in local, low-performance settings has become increasingly important. This study focuses on enhancing Retrieval-Augmented Generation (RAG) techniques for processing complex automotive industry documents using locally deployed Ollama models. Based on the Langchain framework, we propose a multi-dimensional optimization approach for Ollama's local RAG implementation. Our method addresses key challenges in automotive document processing, including multi-column layouts and technical specifications. We introduce improvements in PDF processing, retrieval mechanisms, and context compression, tailored to the unique characteristics of automotive industry documents. Additionally, we design custom classes supporting embedding pipelines and an agent supporting self-RAG based on LangGraph best practices. To evaluate our approach, we constructed a proprietary dataset comprising typical automotive industry documents, including technical reports and corporate regulations. We compared our optimized RAG model and self-RAG agent against a naive RAG baseline across three datasets: our automotive industry dataset, QReCC, and CoQA. Results demonstrate significant improvements in context precision, context recall, answer relevancy, and faithfulness, with particularly notable performance on the automotive industry dataset. Our optimization scheme provides an effective solution for deploying local RAG systems in the automotive sector, addressing the specific needs of PDF chatbots in industrial production environments. This research has important implications for advancing information processing and intelligent production in the automotive industry.
Achieving Fairness Across Local and Global Models in Federated Learning
Jun 24, 2024Achieving fairness across diverse clients in Federated Learning (FL) remains a significant challenge due to the heterogeneity of the data and the inaccessibility of sensitive attributes from clients' private datasets. This study addresses this issue by introducing \texttt{EquiFL}, a novel approach designed to enhance both local and global fairness in federated learning environments. \texttt{EquiFL} incorporates a fairness term into the local optimization objective, effectively balancing local performance and fairness. The proposed coordination mechanism also prevents bias from propagating across clients during the collaboration phase. Through extensive experiments across multiple benchmarks, we demonstrate that \texttt{EquiFL} not only strikes a better balance between accuracy and fairness locally at each client but also achieves global fairness. The results also indicate that \texttt{EquiFL} ensures uniform performance distribution among clients, thus contributing to performance fairness. Furthermore, we showcase the benefits of \texttt{EquiFL} in a real-world distributed dataset from a healthcare application, specifically in predicting the effects of treatments on patients across various hospital locations.
Novel Node Category Detection Under Subpopulation Shift
Apr 01, 2024



In real-world graph data, distribution shifts can manifest in various ways, such as the emergence of new categories and changes in the relative proportions of existing categories. It is often important to detect nodes of novel categories under such distribution shifts for safety or insight discovery purposes. We introduce a new approach, Recall-Constrained Optimization with Selective Link Prediction (RECO-SLIP), to detect nodes belonging to novel categories in attributed graphs under subpopulation shifts. By integrating a recall-constrained learning framework with a sample-efficient link prediction mechanism, RECO-SLIP addresses the dual challenges of resilience against subpopulation shifts and the effective exploitation of graph structure. Our extensive empirical evaluation across multiple graph datasets demonstrates the superior performance of RECO-SLIP over existing methods.
LSTTN: A Long-Short Term Transformer-based Spatio-temporal Neural Network for Traffic Flow Forecasting
Mar 25, 2024



Accurate traffic forecasting is a fundamental problem in intelligent transportation systems and learning long-range traffic representations with key information through spatiotemporal graph neural networks (STGNNs) is a basic assumption of current traffic flow prediction models. However, due to structural limitations, existing STGNNs can only utilize short-range traffic flow data; therefore, the models cannot adequately learn the complex trends and periodic features in traffic flow. Besides, it is challenging to extract the key temporal information from the long historical traffic series and obtain a compact representation. To solve the above problems, we propose a novel LSTTN (Long-Short Term Transformer-based Network) framework comprehensively considering the long- and short-term features in historical traffic flow. First, we employ a masked subseries Transformer to infer the content of masked subseries from a small portion of unmasked subseries and their temporal context in a pretraining manner, forcing the model to efficiently learn compressed and contextual subseries temporal representations from long historical series. Then, based on the learned representations, long-term trend is extracted by using stacked 1D dilated convolution layers, and periodic features are extracted by dynamic graph convolution layers. For the difficulties in making time-step level prediction, LSTTN adopts a short-term trend extractor to learn fine-grained short-term temporal features. Finally, LSTTN fuses the long-term trend, periodic features and short-term features to obtain the prediction results. Experiments on four real-world datasets show that in 60-minute-ahead long-term forecasting, the LSTTN model achieves a minimum improvement of 5.63\% and a maximum improvement of 16.78\% over baseline models. The source code is available at https://github.com/GeoX-Lab/LSTTN.
* 15 pages, 10 figures, 6 tables
FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion
Feb 05, 2024



As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in real world is validated by a challenging set of clinical risk prediction tasks.