 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Defines "Best"? Towards Interactive, User-Defined Evaluation of LLM Leaderboards
Apr 23, 2026LLM leaderboards are widely used to compare models and guide deployment decisions. However, leaderboard rankings are shaped by evaluation priorities set by benchmark designers, rather than by the diverse goals and constraints of actual users and organizations. A single aggregate score often obscures how models behave across different prompt types and compositions. In this work, we conduct an in-depth analysis of the dataset used in the LMArena (formerly Chatbot Arena) benchmark and investigate this evaluation challenge by designing an interactive visualization interface as a design probe. Our analysis reveals that the dataset is heavily skewed toward certain topics, that model rankings vary across prompt slices, and that preference-based judgments are used in ways that blur their intended scope. Building on this analysis, we introduce a visualization interface that allows users to define their own evaluation priorities by selecting and weighting prompt slices and to explore how rankings change accordingly. A qualitative study suggests that this interactive approach improves transparency and supports more context-specific model evaluation, pointing toward alternative ways to design and use LLM leaderboards.
Towards Motion-aware Referring Image Segmentation
Mar 18, 2026Referring Image Segmentation (RIS) requires identifying objects from images based on textual descriptions. We observe that existing methods significantly underperform on motion-related queries compared to appearance-based ones. To address this, we first introduce an efficient data augmentation scheme that extracts motion-centric phrases from original captions, exposing models to more motion expressions without additional annotations. Second, since the same object can be described differently depending on the context, we propose Multimodal Radial Contrastive Learning (MRaCL), performed on fused image-text embeddings rather than unimodal representations. For comprehensive evaluation, we introduce a new test split focusing on motion-centric queries, and introduce a new benchmark called M-Bench, where objects are distinguished primarily by actions. Extensive experiments show our method substantially improves performance on motion-centric queries across multiple RIS models, maintaining competitive results on appearance-based descriptions. Codes are available at https://github.com/snuviplab/MRaCL
MolmoB0T: Large-Scale Simulation Enables Zero-Shot Manipulation
Mar 17, 2026A prevailing view in robot learning is that simulation alone is not enough; effective sim-to-real transfer is widely believed to require at least some real-world data collection or task-specific fine-tuning to bridge the gap between simulated and physical environments. We challenge that assumption. With sufficiently large-scale and diverse simulated synthetic training data, we show that zero-shot transfer to the real world is not only possible, but effective for both static and mobile manipulation. We introduce MolmoBot-Engine, a fully open-source pipeline for procedural data generation across robots, tasks, and diverse simulated environments in MolmoSpaces. With it, we release MolmoBot-Data, a dataset of 1.8 million expert trajectories for articulated object manipulation and pick-and-place tasks. We train three policy classes: MolmoBot, a Molmo2-based multi-frame vision-language model with a flow-matching action head; MolmoBot-Pi0, which replicates the $π_0$ architecture to enable direct comparison; and MolmoBot-SPOC, a lightweight policy suitable for edge deployment and amenable to RL fine-tuning. We evaluate on two robotic platforms: the Franka FR3 for tabletop manipulation tasks and the Rainbow Robotics RB-Y1 mobile manipulator for door opening, drawer manipulation, cabinet interaction, and mobile pick-and-place. Without any real-world fine-tuning, our policies achieve zero-shot transfer to unseen objects and environments. On tabletop pick-and-place, MolmoBot achieves a success rate of 79.2% in real world evaluations across 4 settings, outperforming $π_{0.5}$ at 39.2%. Our results demonstrate that procedural environment generation combined with diverse articulated assets can produce robust manipulation policies that generalize broadly to the real world. Technical Blog: https://allenai.org/blog/molmobot-robot-manipulation
TripleSumm: Adaptive Triple-Modality Fusion for Video Summarization
Mar 01, 2026The exponential growth of video content necessitates effective video summarization to efficiently extract key information from long videos. However, current approaches struggle to fully comprehend complex videos, primarily because they employ static or modality-agnostic fusion strategies. These methods fail to account for the dynamic, frame-dependent variations in modality saliency inherent in video data. To overcome these limitations, we propose TripleSumm, a novel architecture that adaptively weights and fuses the contributions of visual, text, and audio modalities at the frame level. Furthermore, a significant bottleneck for research into multimodal video summarization has been the lack of comprehensive benchmarks. Addressing this bottleneck, we introduce MoSu (Most Replayed Multimodal Video Summarization), the first large-scale benchmark that provides all three modalities. Extensive experiments demonstrate that TripleSumm achieves state-of-the-art performance, outperforming existing methods by a significant margin on four benchmarks, including MoSu. Our code and dataset are available at https://github.com/smkim37/TripleSumm.
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Feb 11, 2026Deploying robots at scale demands robustness to the long tail of everyday situations. The countless variations in scene layout, object geometry, and task specifications that characterize real environments are vast and underrepresented in existing robot benchmarks. Measuring this level of generalization requires infrastructure at a scale and diversity that physical evaluation alone cannot provide. We introduce MolmoSpaces, a fully open ecosystem to support large-scale benchmarking of robot policies. MolmoSpaces consists of over 230k diverse indoor environments, ranging from handcrafted household scenes to procedurally generated multiroom houses, populated with 130k richly annotated object assets, including 48k manipulable objects with 42M stable grasps. Crucially, these environments are simulator-agnostic, supporting popular options such as MuJoCo, Isaac, and ManiSkill. The ecosystem supports the full spectrum of embodied tasks: static and mobile manipulation, navigation, and multiroom long-horizon tasks requiring coordinated perception, planning, and interaction across entire indoor environments. We also design MolmoSpaces-Bench, a benchmark suite of 8 tasks in which robots interact with our diverse scenes and richly annotated objects. Our experiments show MolmoSpaces-Bench exhibits strong sim-to-real correlation (R = 0.96, \r{ho} = 0.98), confirm newer and stronger zero-shot policies outperform earlier versions in our benchmarks, and identify key sensitivities to prompt phrasing, initial joint positions, and camera occlusion. Through MolmoSpaces and its open-source assets and tooling, we provide a foundation for scalable data generation, policy training, and benchmark creation for robot learning research.
Contact-Anchored Policies: Contact Conditioning Creates Strong Robot Utility Models
Feb 09, 2026The prevalent paradigm in robot learning attempts to generalize across environments, embodiments, and tasks with language prompts at runtime. A fundamental tension limits this approach: language is often too abstract to guide the concrete physical understanding required for robust manipulation. In this work, we introduce Contact-Anchored Policies (CAP), which replace language conditioning with points of physical contact in space. Simultaneously, we structure CAP as a library of modular utility models rather than a monolithic generalist policy. This factorization allows us to implement a real-to-sim iteration cycle: we build EgoGym, a lightweight simulation benchmark, to rapidly identify failure modes and refine our models and datasets prior to real-world deployment. We show that by conditioning on contact and iterating via simulation, CAP generalizes to novel environments and embodiments out of the box on three fundamental manipulation skills while using only 23 hours of demonstration data, and outperforms large, state-of-the-art VLAs in zero-shot evaluations by 56%. All model checkpoints, codebase, hardware, simulation, and datasets will be open-sourced. Project page: https://cap-policy.github.io/
Enhancing Multi-Image Understanding through Delimiter Token Scaling
Feb 02, 2026Large Vision-Language Models (LVLMs) achieve strong performance on single-image tasks, but their performance declines when multiple images are provided as input. One major reason is the cross-image information leakage, where the model struggles to distinguish information across different images. Existing LVLMs already employ delimiter tokens to mark the start and end of each image, yet our analysis reveals that these tokens fail to effectively block cross-image information leakage. To enhance their effectiveness, we propose a method that scales the hidden states of delimiter tokens. This enhances the model's ability to preserve image-specific information by reinforcing intra-image interaction and limiting undesired cross-image interactions. Consequently, the model is better able to distinguish between images and reason over them more accurately. Experiments show performance gains on multi-image benchmarks such as Mantis, MuirBench, MIRB, and QBench2. We further evaluate our method on text-only tasks that require clear distinction. The method improves performance on multi-document and multi-table understanding benchmarks, including TQABench, MultiNews, and WCEP-10. Notably, our method requires no additional training or inference cost.
Knowledge Vector Weakening: Efficient Training-free Unlearning for Large Vision-Language Models
Jan 29, 2026Large Vision-Language Models (LVLMs) are widely adopted for their strong multimodal capabilities, yet they raise serious concerns such as privacy leakage and harmful content generation. Machine unlearning has emerged as a promising solution for removing the influence of specific data from trained models. However, existing approaches largely rely on gradient-based optimization, incurring substantial computational costs for large-scale LVLMs. To address this limitation, we propose Knowledge Vector Weakening (KVW), a training-free unlearning method that directly intervenes in the full model without gradient computation. KVW identifies knowledge vectors that are activated during the model's output generation on the forget set and progressively weakens their contributions, thereby preventing the model from exploiting undesirable knowledge. Experiments on the MLLMU and CLEAR benchmarks demonstrate that KVW achieves a stable forget-retain trade-off while significantly improving computational efficiency over gradient-based and LoRA-based unlearning methods.
FinAI Data Assistant: LLM-based Financial Database Query Processing with the OpenAI Function Calling API
Oct 15, 2025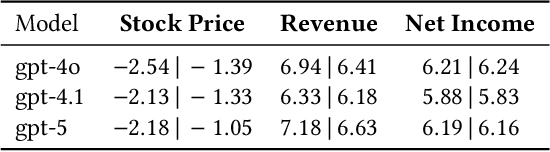

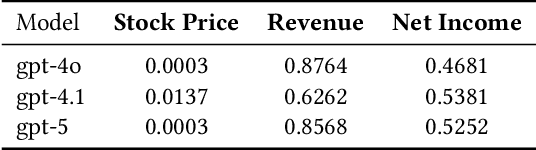
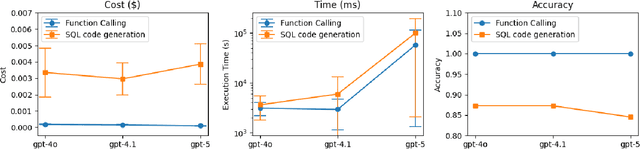
We present FinAI Data Assistant, a practical approach for natural-language querying over financial databases that combines large language models (LLMs) with the OpenAI Function Calling API. Rather than synthesizing complete SQL via text-to-SQL, our system routes user requests to a small library of vetted, parameterized queries, trading generative flexibility for reliability, low latency, and cost efficiency. We empirically study three questions: (RQ1) whether LLMs alone can reliably recall or extrapolate time-dependent financial data without external retrieval; (RQ2) how well LLMs map company names to stock ticker symbols; and (RQ3) whether function calling outperforms text-to-SQL for end-to-end database query processing. Across controlled experiments on prices and fundamentals, LLM-only predictions exhibit non-negligible error and show look-ahead bias primarily for stock prices relative to model knowledge cutoffs. Ticker-mapping accuracy is near-perfect for NASDAQ-100 constituents and high for S\&P~500 firms. Finally, FinAI Data Assistant achieves lower latency and cost and higher reliability than a text-to-SQL baseline on our task suite. We discuss design trade-offs, limitations, and avenues for deployment.
GuruAgents: Emulating Wise Investors with Prompt-Guided LLM Agents
Oct 02, 2025This study demonstrates that GuruAgents, prompt-guided AI agents, can systematically operationalize the strategies of legendary investment gurus. We develop five distinct GuruAgents, each designed to emulate an iconic investor, by encoding their distinct philosophies into LLM prompts that integrate financial tools and a deterministic reasoning pipeline. In a backtest on NASDAQ-100 constituents from Q4 2023 to Q2 2025, the GuruAgents exhibit unique behaviors driven by their prompted personas. The Buffett GuruAgent achieves the highest performance, delivering a 42.2\% CAGR that significantly outperforms benchmarks, while other agents show varied results. These findings confirm that prompt engineering can successfully translate the qualitative philosophies of investment gurus into reproducible, quantitative strategies, highlighting a novel direction for automated systematic investing. The source code and data are available at https://github.com/yejining99/GuruAgents.
* 7 Pages, 2 figures