 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALLM-GAN: Multi-Agent Large Language Model as Generative Adversarial Network for Synthesizing Tabular Data
Jun 15, 2024
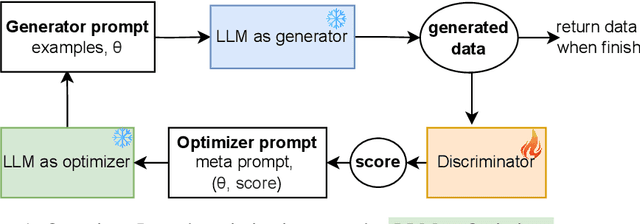


In the era of big data, access to abundant data is crucial for driving research forward. However, such data is often inaccessible due to privacy concerns or high costs, particularly in healthcare domain. Generating synthetic (tabular) data can address this, but existing models typically require substantial amounts of data to train effectively, contradicting our objective to solve data scarcity. To address this challenge, we propose a novel framework to generate synthetic tabular data, powered by large language models (LLMs) that emulates the architecture of a Generative Adversarial Network (GAN). By incorporating data generation process as contextual information and utilizing LLM as the optimizer, our approach significantly enhance the quality of synthetic data generation in common scenarios with small sample sizes. Our experimental results on public and private datasets demonstrate that our model outperforms several state-of-art models regarding generating higher quality synthetic data for downstream tasks while keeping privacy of the real data.
Heterogeneous Treatment Effect Estimation using machine learning for Healthcare application: tutorial and benchmark
Sep 27, 2021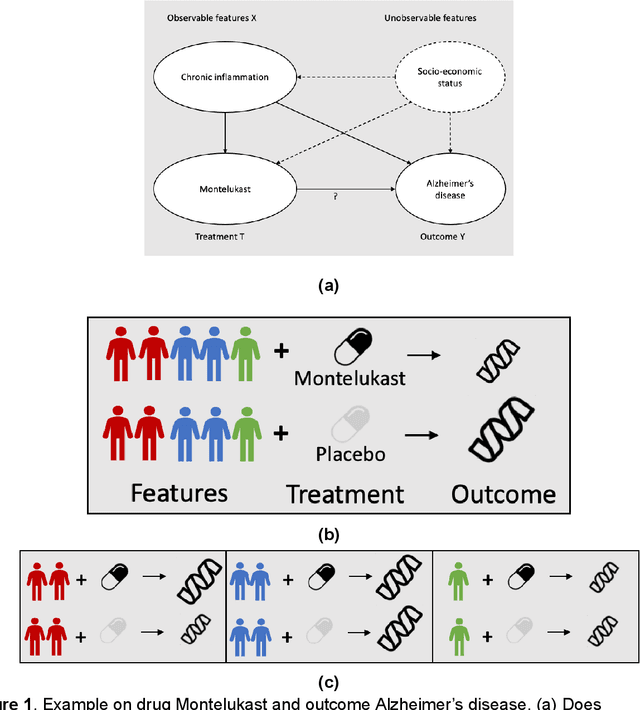
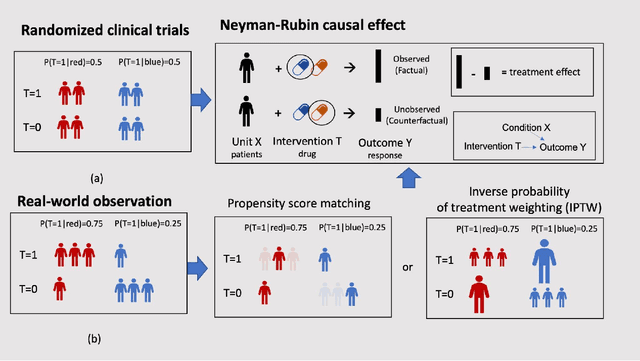
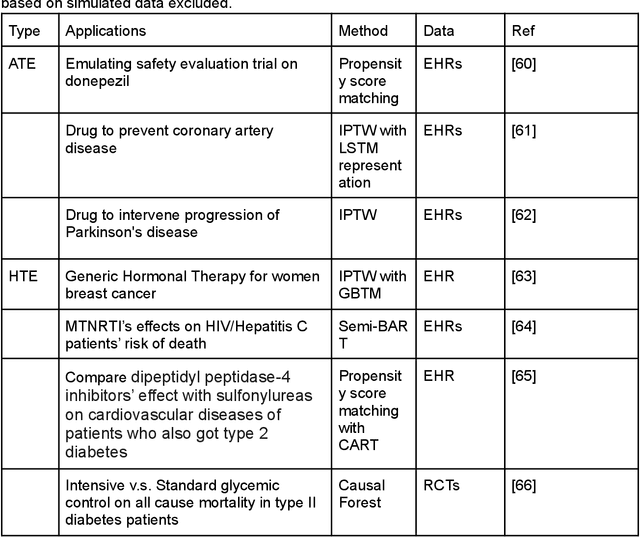
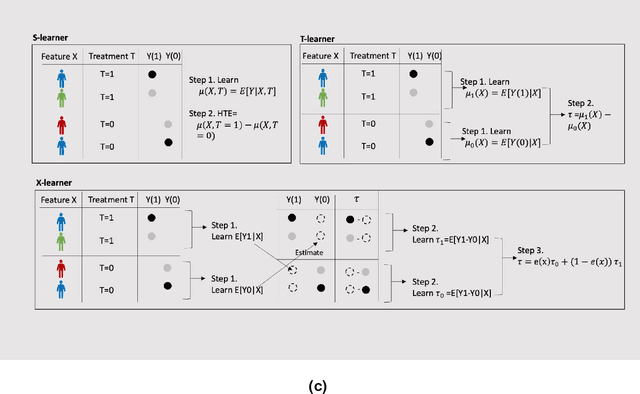
Developing new drugs for target diseases is a time-consuming and expensive task, drug repurposing has become a popular topic in the drug development field. As much health claim data become available, many studies have been conducted on the data. The real-world data is noisy, sparse, and has many confounding factors. In addition, many studies have shown that drugs effects are heterogeneous among the population. Lots of advanced machine learning models about estimating heterogeneous treatment effects (HTE) have emerged in recent years, and have been applied to in econometrics and machine learning communities. These studies acknowledge medicine and drug development as the main application area, but there has been limited translational research from the HTE methodology to drug development. We aim to introduce the HTE methodology to the healthcare area and provide feasibility consideration when translating the methodology with benchmark experiments on healthcare administrative claim data. Also, we want to use benchmark experiments to show how to interpret and evaluate the model when it is applied to healthcare research. By introducing the recent HTE techniques to a broad readership in biomedical informatics communities, we expect to promote the wide adoption of causal inference using machine learning. We also expect to provide the feasibility of HTE for personalized drug effectiveness.