 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Treatment Effect Estimation using machine learning for Healthcare application: tutorial and benchmark
Paper and Code
Sep 27, 2021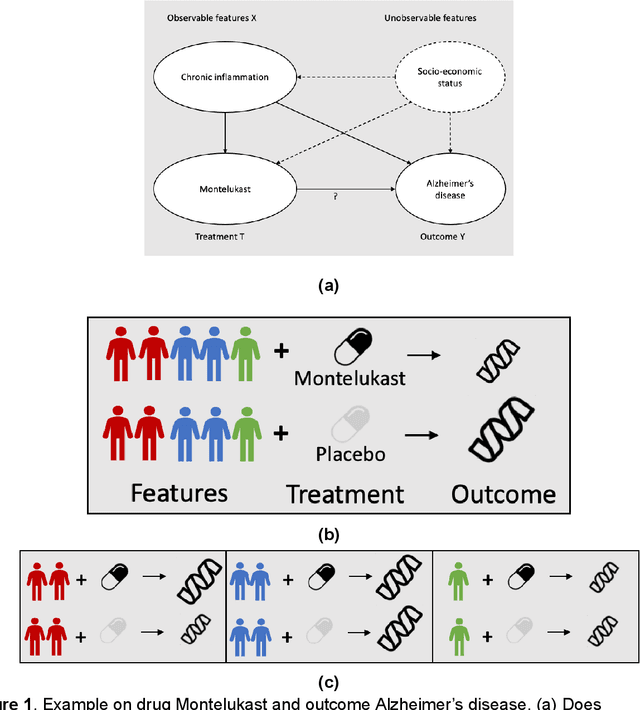
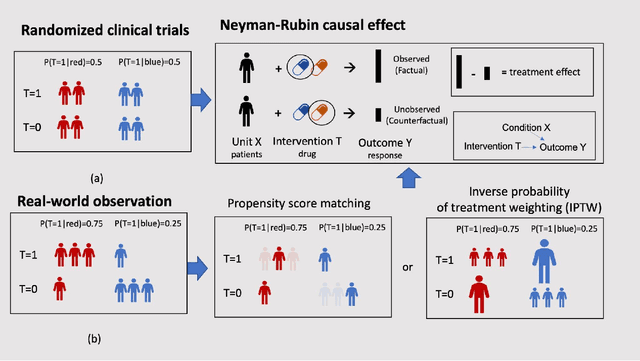
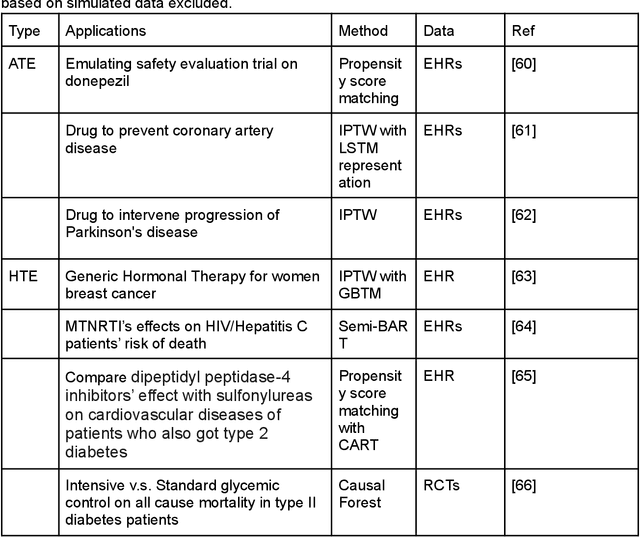
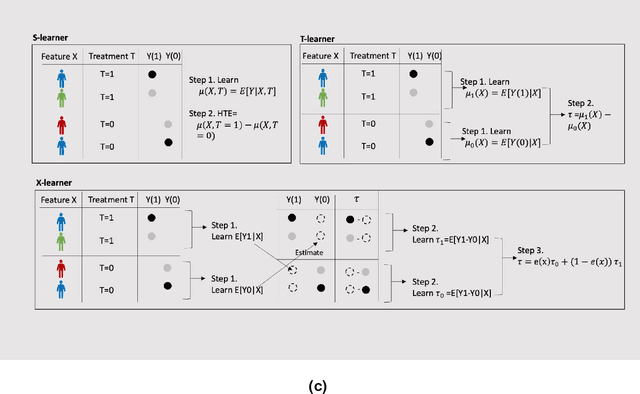
Developing new drugs for target diseases is a time-consuming and expensive task, drug repurposing has become a popular topic in the drug development field. As much health claim data become available, many studies have been conducted on the data. The real-world data is noisy, sparse, and has many confounding factors. In addition, many studies have shown that drugs effects are heterogeneous among the population. Lots of advanced machine learning models about estimating heterogeneous treatment effects (HTE) have emerged in recent years, and have been applied to in econometrics and machine learning communities. These studies acknowledge medicine and drug development as the main application area, but there has been limited translational research from the HTE methodology to drug development. We aim to introduce the HTE methodology to the healthcare area and provide feasibility consideration when translating the methodology with benchmark experiments on healthcare administrative claim data. Also, we want to use benchmark experiments to show how to interpret and evaluate the model when it is applied to healthcare research. By introducing the recent HTE techniques to a broad readership in biomedical informatics communities, we expect to promote the wide adoption of causal inference using machine learning. We also expect to provide the feasibility of HTE for personalized drug effectiveness.