 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Representation Learning-Based Dynamic Trajectory Phenotyping for Acute Respiratory Failure in Medical Intensive Care Units
May 04, 2024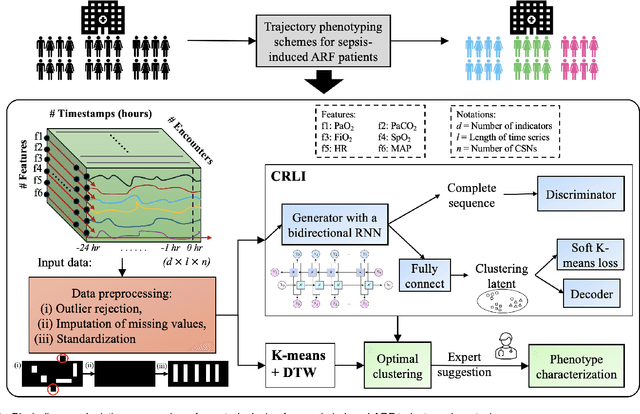
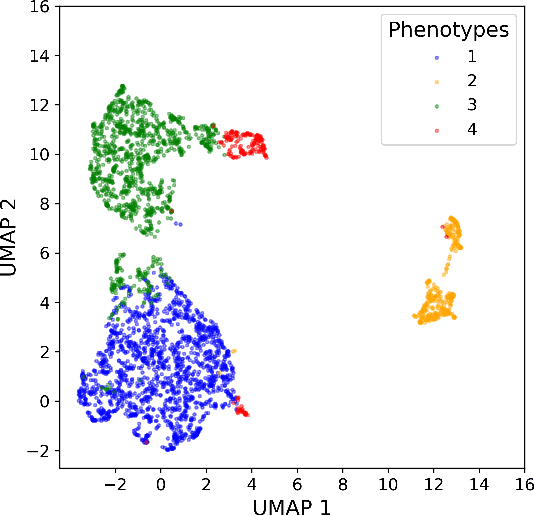
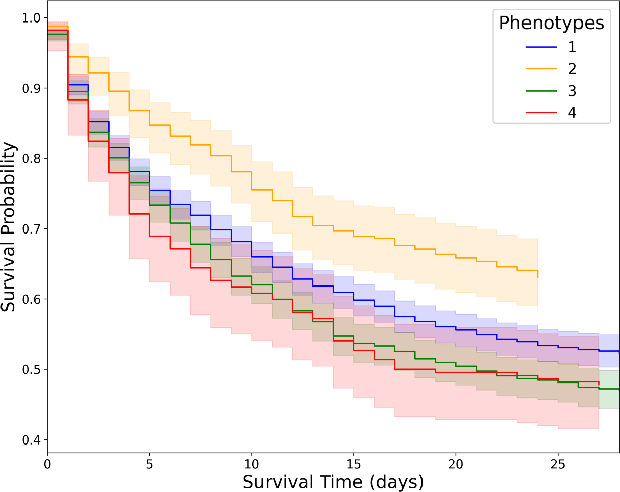
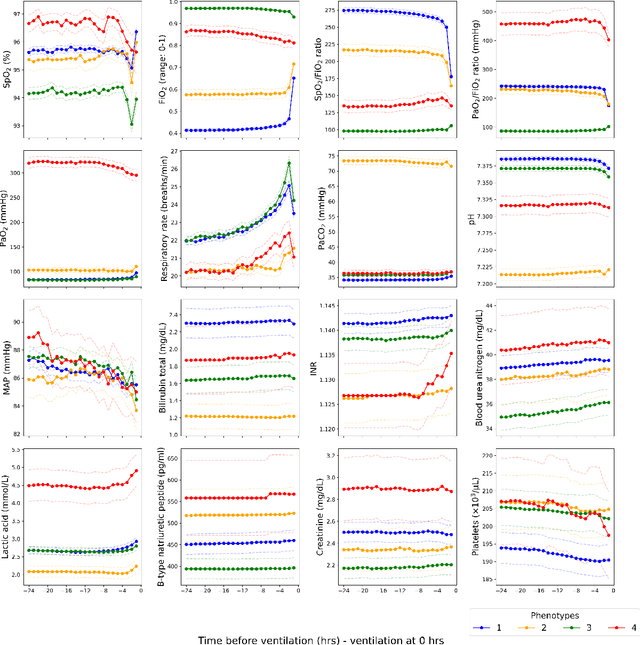
Sepsis-induced acute respiratory failure (ARF) is a serious complication with a poor prognosis. This paper presents a deep representation learningbased phenotyping method to identify distinct groups of clinical trajectories of septic patients with ARF. For this retrospective study, we created a dataset from electronic medical records (EMR) consisting of data from sepsis patients admitted to medical intensive care units who required at least 24 hours of invasive mechanical ventilation at a quarternary care academic hospital in southeast USA for the years 2016-2021. A total of N=3349 patient encounters were included in this study. Clustering Representation Learning on Incomplete Time Series Data (CRLI) algorithm was applied to a parsimonious set of EMR variables in this data set. To validate the optimal number of clusters, the K-means algorithm was used in conjunction with dynamic time warping. Our model yielded four distinct patient phenotypes that were characterized as liver dysfunction/heterogeneous, hypercapnia, hypoxemia, and multiple organ dysfunction syndrome by a critical care expert. A Kaplan-Meier analysis to compare the 28-day mortality trends exhibited significant differences (p < 0.005) between the four phenotypes. The study demonstrates the utility of our deep representation learning-based approach in unraveling phenotypes that reflect the heterogeneity in sepsis-induced ARF in terms of different mortality outcomes and severity. These phenotypes might reveal important clinical insights into an effective prognosis and tailored treatment strategies.
Scalable Causal Structure Learning: New Opportunities in Biomedicine
Oct 15, 2021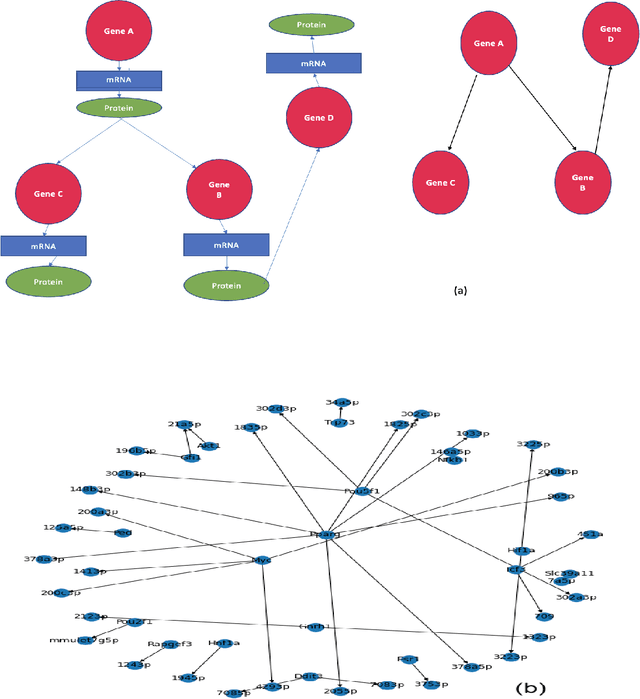

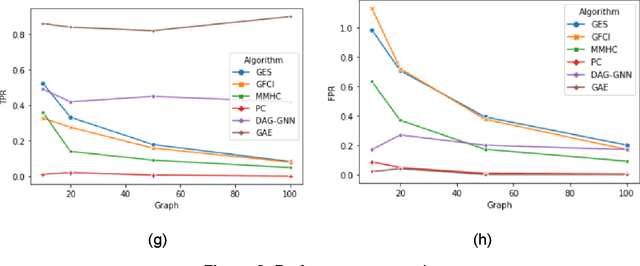
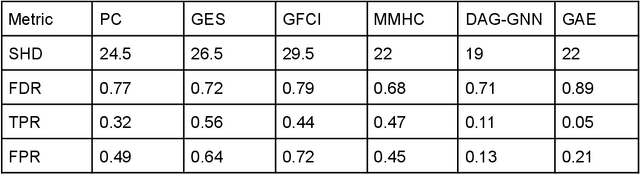
This paper gives a practical tutorial on popular causal structure learning models with examples of real-world data to help healthcare audiences understand and apply them. We review prominent traditional, score-based and machine-learning based schemes for causal structure discovery, study some of their performance over some benchmark datasets, and discuss some of the applications to biomedicine. In the case of sufficient data, machine learning-based approaches can be scalable, can include a greater number of variables than traditional approaches, and can potentially be applied in many biomedical applications.
Heterogeneous Treatment Effect Estimation using machine learning for Healthcare application: tutorial and benchmark
Sep 27, 2021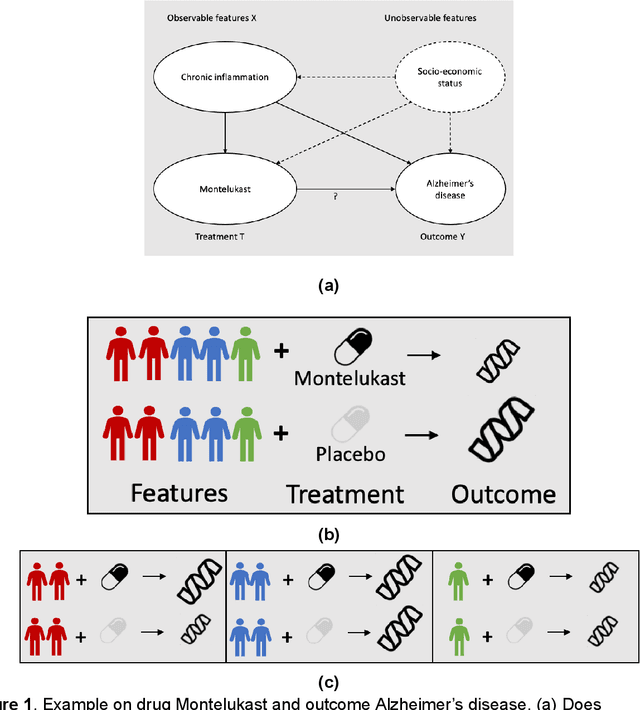
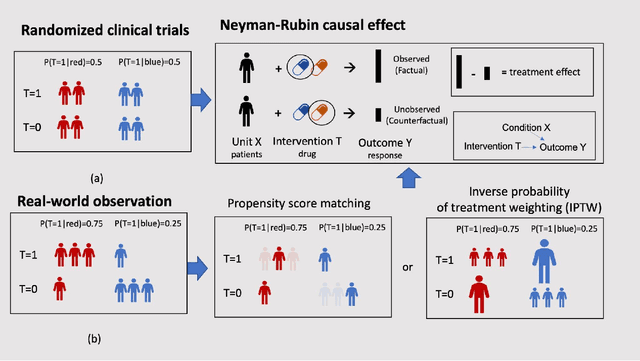
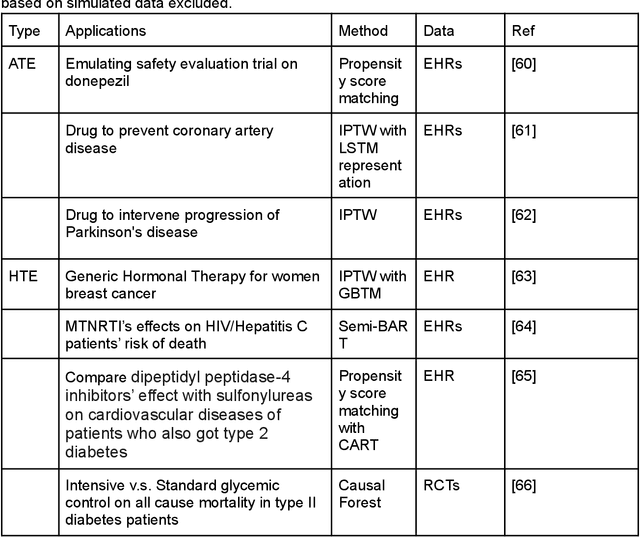
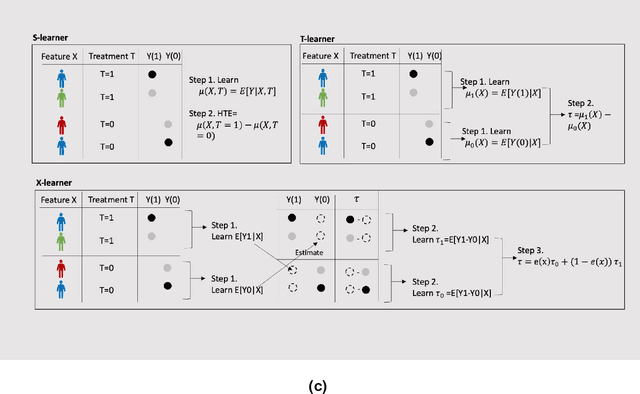
Developing new drugs for target diseases is a time-consuming and expensive task, drug repurposing has become a popular topic in the drug development field. As much health claim data become available, many studies have been conducted on the data. The real-world data is noisy, sparse, and has many confounding factors. In addition, many studies have shown that drugs effects are heterogeneous among the population. Lots of advanced machine learning models about estimating heterogeneous treatment effects (HTE) have emerged in recent years, and have been applied to in econometrics and machine learning communities. These studies acknowledge medicine and drug development as the main application area, but there has been limited translational research from the HTE methodology to drug development. We aim to introduce the HTE methodology to the healthcare area and provide feasibility consideration when translating the methodology with benchmark experiments on healthcare administrative claim data. Also, we want to use benchmark experiments to show how to interpret and evaluate the model when it is applied to healthcare research. By introducing the recent HTE techniques to a broad readership in biomedical informatics communities, we expect to promote the wide adoption of causal inference using machine learning. We also expect to provide the feasibility of HTE for personalized drug effectiveness.
CodNN -- Robust Neural Networks From Coded Classification
Apr 29, 2020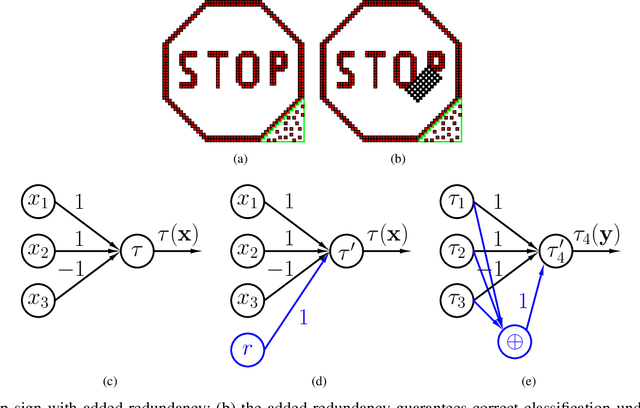
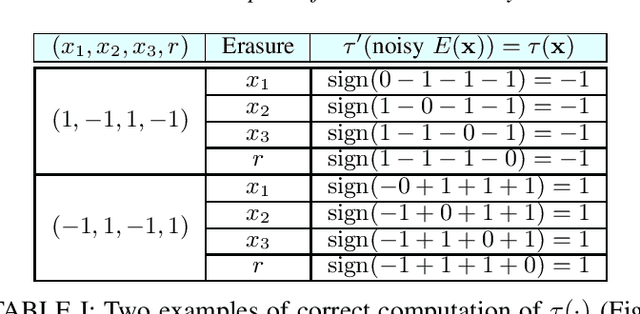
Deep Neural Networks (DNNs) are a revolutionary force in the ongoing information revolution, and yet their intrinsic properties remain a mystery. In particular, it is widely known that DNNs are highly sensitive to noise, whether adversarial or random. This poses a fundamental challenge for hardware implementations of DNNs, and for their deployment in critical applications such as autonomous driving. In this paper we construct robust DNNs via error correcting codes. By our approach, either the data or internal layers of the DNN are coded with error correcting codes, and successful computation under noise is guaranteed. Since DNNs can be seen as a layered concatenation of classification tasks, our research begins with the core task of classifying noisy coded inputs, and progresses towards robust DNNs. We focus on binary data and linear codes. Our main result is that the prevalent parity code can guarantee robustness for a large family of DNNs, which includes the recently popularized binarized neural networks. Further, we show that the coded classification problem has a deep connection to Fourier analysis of Boolean functions. In contrast to existing solutions in the literature, our results do not rely on altering the training process of the DNN, and provide mathematically rigorous guarantees rather than experimental evidence.