 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedRedFlag: Investigating how LLMs Redirect Misconceptions in Real-World Health Communication
Jan 14, 2026Real-world health questions from patients often unintentionally embed false assumptions or premises. In such cases, safe medical communication typically involves redirection: addressing the implicit misconception and then responding to the underlying patient context, rather than the original question. While large language models (LLMs) are increasingly being used by lay users for medical advice, they have not yet been tested for this crucial competency. Therefore, in this work, we investigate how LLMs react to false premises embedded within real-world health questions. We develop a semi-automated pipeline to curate MedRedFlag, a dataset of 1100+ questions sourced from Reddit that require redirection. We then systematically compare responses from state-of-the-art LLMs to those from clinicians. Our analysis reveals that LLMs often fail to redirect problematic questions, even when the problematic premise is detected, and provide answers that could lead to suboptimal medical decision making. Our benchmark and results reveal a novel and substantial gap in how LLMs perform under the conditions of real-world health communication, highlighting critical safety concerns for patient-facing medical AI systems. Code and dataset are available at https://github.com/srsambara-1/MedRedFlag.
"What's Up, Doc?": Analyzing How Users Seek Health Information in Large-Scale Conversational AI Datasets
Jun 26, 2025People are increasingly seeking healthcare information from large language models (LLMs) via interactive chatbots, yet the nature and inherent risks of these conversations remain largely unexplored. In this paper, we filter large-scale conversational AI datasets to achieve HealthChat-11K, a curated dataset of 11K real-world conversations composed of 25K user messages. We use HealthChat-11K and a clinician-driven taxonomy for how users interact with LLMs when seeking healthcare information in order to systematically study user interactions across 21 distinct health specialties. Our analysis reveals insights into the nature of how and why users seek health information, such as common interactions, instances of incomplete context, affective behaviors, and interactions (e.g., leading questions) that can induce sycophancy, underscoring the need for improvements in the healthcare support capabilities of LLMs deployed as conversational AI. Code and artifacts to retrieve our analyses and combine them into a curated dataset can be found here: https://github.com/yahskapar/HealthChat
Deep Representation Learning-Based Dynamic Trajectory Phenotyping for Acute Respiratory Failure in Medical Intensive Care Units
May 04, 2024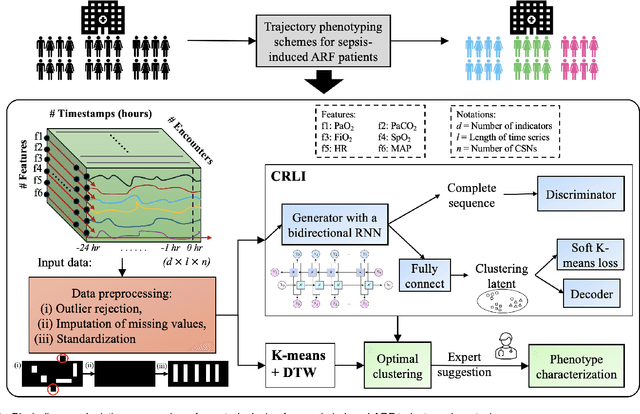
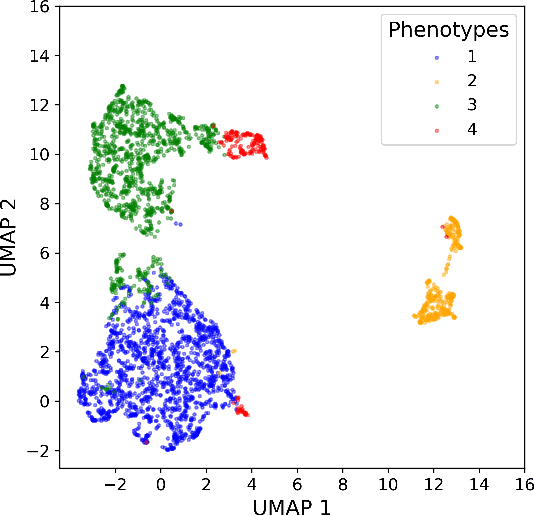
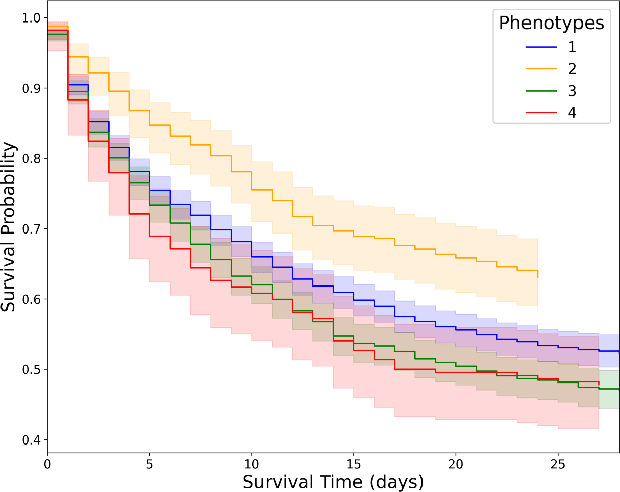
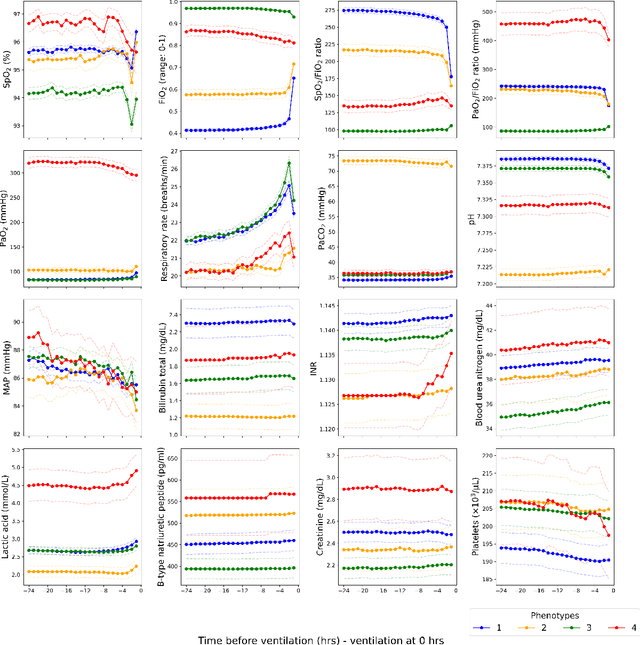
Sepsis-induced acute respiratory failure (ARF) is a serious complication with a poor prognosis. This paper presents a deep representation learningbased phenotyping method to identify distinct groups of clinical trajectories of septic patients with ARF. For this retrospective study, we created a dataset from electronic medical records (EMR) consisting of data from sepsis patients admitted to medical intensive care units who required at least 24 hours of invasive mechanical ventilation at a quarternary care academic hospital in southeast USA for the years 2016-2021. A total of N=3349 patient encounters were included in this study. Clustering Representation Learning on Incomplete Time Series Data (CRLI) algorithm was applied to a parsimonious set of EMR variables in this data set. To validate the optimal number of clusters, the K-means algorithm was used in conjunction with dynamic time warping. Our model yielded four distinct patient phenotypes that were characterized as liver dysfunction/heterogeneous, hypercapnia, hypoxemia, and multiple organ dysfunction syndrome by a critical care expert. A Kaplan-Meier analysis to compare the 28-day mortality trends exhibited significant differences (p < 0.005) between the four phenotypes. The study demonstrates the utility of our deep representation learning-based approach in unraveling phenotypes that reflect the heterogeneity in sepsis-induced ARF in terms of different mortality outcomes and severity. These phenotypes might reveal important clinical insights into an effective prognosis and tailored treatment strategies.
GaitSADA: Self-Aligned Domain Adaptation for mmWave Gait Recognition
Feb 01, 2023



mmWave radar-based gait recognition is a novel user identification method that captures human gait biometrics from mmWave radar return signals. This technology offers privacy protection and is resilient to weather and lighting conditions. However, its generalization performance is yet unknown and limits its practical deployment. To address this problem, in this paper, a non-synthetic dataset is collected and analyzed to reveal the presence of spatial and temporal domain shifts in mmWave gait biometric data, which significantly impacts identification accuracy. To address this issue, a novel self-aligned domain adaptation method called GaitSADA is proposed. GaitSADA improves system generalization performance by using a two-stage semi-supervised model training approach. The first stage uses semi-supervised contrastive learning and the second stage uses semi-supervised consistency training with centroid alignment. Extensive experiments show that GaitSADA outperforms representative domain adaptation methods by an average of 15.41% in low data regimes.
A Modular Multi-stage Lightweight Graph Transformer Network for Human Pose and Shape Estimation from 2D Human Pose
Jan 31, 2023In this research, we address the challenge faced by existing deep learning-based human mesh reconstruction methods in balancing accuracy and computational efficiency. These methods typically prioritize accuracy, resulting in large network sizes and excessive computational complexity, which may hinder their practical application in real-world scenarios, such as virtual reality systems. To address this issue, we introduce a modular multi-stage lightweight graph-based transformer network for human pose and shape estimation from 2D human pose, a pose-based human mesh reconstruction approach that prioritizes computational efficiency without sacrificing reconstruction accuracy. Our method consists of a 2D-to-3D lifter module that utilizes graph transformers to analyze structured and implicit joint correlations in 2D human poses, and a mesh regression module that combines the extracted pose features with a mesh template to produce the final human mesh parameters.
Skeleton-based Human Action Recognition via Convolutional Neural Networks (CNN)
Jan 31, 2023



Recently, there has been a remarkable increase in the interest towards skeleton-based action recognition within the research community, owing to its various advantageous features, including computational efficiency, representative features, and illumination invariance. Despite this, researchers continue to explore and investigate the most optimal way to represent human actions through skeleton representation and the extracted features. As a result, the growth and availability of human action recognition datasets have risen substantially. In addition, deep learning-based algorithms have gained widespread popularity due to the remarkable advancements in various computer vision tasks. Most state-of-the-art contributions in skeleton-based action recognition incorporate a Graph Neural Network (GCN) architecture for representing the human body and extracting features. Our research demonstrates that Convolutional Neural Networks (CNNs) can attain comparable results to GCN, provided that the proper training techniques, augmentations, and optimizers are applied. Our approach has been rigorously validated, and we have achieved a score of 95% on the NTU-60 dataset
GaitMixer: Skeleton-based Gait Representation Learning via Wide-spectrum Multi-axial Mixer
Oct 29, 2022Most existing gait recognition methods are appearance-based, which rely on the silhouettes extracted from the video data of human walking activities. The less-investigated skeleton-based gait recognition methods directly learn the gait dynamics from 2D/3D human skeleton sequences, which are theoretically more robust solutions in the presence of appearance changes caused by clothes, hairstyles, and carrying objects. However, the performance of skeleton-based solutions is still largely behind the appearance-based ones. This paper aims to close such performance gap by proposing a novel network model, GaitMixer, to learn more discriminative gait representation from skeleton sequence data. In particular, GaitMixer follows a heterogeneous multi-axial mixer architecture, which exploits the spatial self-attention mixer followed by the temporal large-kernel convolution mixer to learn rich multi-frequency signals in the gait feature maps. Experiments on the widely used gait database, CASIA-B, demonstrate that GaitMixer outperforms the previous SOTA skeleton-based methods by a large margin while achieving a competitive performance compared with the representative appearance-based solutions. Code will be available at https://github.com/exitudio/gaitmixer