 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanner-Auditor Twin: Agentic Discharge Planning with FHIR-Based LLM Planning, Guideline Recall, Optional Caching and Self-Improvement
Jan 28, 2026Objective: Large language models (LLMs) show promise for clinical discharge planning, but their use is constrained by hallucination, omissions, and miscalibrated confidence. We introduce a self-improving, cache-optional Planner-Auditor framework that improves safety and reliability by decoupling generation from deterministic validation and targeted replay. Materials and Methods: We implemented an agentic, retrospective, FHIR-native evaluation pipeline using MIMIC-IV-on-FHIR. For each patient, the Planner (LLM) generates a structured discharge action plan with an explicit confidence estimate. The Auditor is a deterministic module that evaluates multi-task coverage, tracks calibration (Brier score, ECE proxies), and monitors action-distribution drift. The framework supports two-tier self-improvement: (i) within-episode regeneration when enabled, and (ii) cross-episode discrepancy buffering with replay for high-confidence, low-coverage cases. Results: While context caching improved performance over baseline, the self-improvement loop was the primary driver of gains, increasing task coverage from 32% to 86%. Calibration improved substantially, with reduced Brier/ECE and fewer high-confidence misses. Discrepancy buffering further corrected persistent high-confidence omissions during replay. Discussion: Feedback-driven regeneration and targeted replay act as effective control mechanisms to reduce omissions and improve confidence reliability in structured clinical planning. Separating an LLM Planner from a rule-based, observational Auditor enables systematic reliability measurement and safer iteration without model retraining. Conclusion: The Planner-Auditor framework offers a practical pathway toward safer automated discharge planning using interoperable FHIR data access and deterministic auditing, supported by reproducible ablations and reliability-focused evaluation.
Contextual Phenotyping of Pediatric Sepsis Cohort Using Large Language Models
May 14, 2025Clustering patient subgroups is essential for personalized care and efficient resource use. Traditional clustering methods struggle with high-dimensional, heterogeneous healthcare data and lack contextual understanding. This study evaluates Large Language Model (LLM) based clustering against classical methods using a pediatric sepsis dataset from a low-income country (LIC), containing 2,686 records with 28 numerical and 119 categorical variables. Patient records were serialized into text with and without a clustering objective. Embeddings were generated using quantized LLAMA 3.1 8B, DeepSeek-R1-Distill-Llama-8B with low-rank adaptation(LoRA), and Stella-En-400M-V5 models. K-means clustering was applied to these embeddings. Classical comparisons included K-Medoids clustering on UMAP and FAMD-reduced mixed data. Silhouette scores and statistical tests evaluated cluster quality and distinctiveness. Stella-En-400M-V5 achieved the highest Silhouette Score (0.86). LLAMA 3.1 8B with the clustering objective performed better with higher number of clusters, identifying subgroups with distinct nutritional, clinical, and socioeconomic profiles. LLM-based methods outperformed classical techniques by capturing richer context and prioritizing key features. These results highlight potential of LLMs for contextual phenotyping and informed decision-making in resource-limited settings.
NeuroSep-CP-LCB: A Deep Learning-based Contextual Multi-armed Bandit Algorithm with Uncertainty Quantification for Early Sepsis Prediction
Mar 20, 2025



In critical care settings, timely and accurate predictions can significantly impact patient outcomes, especially for conditions like sepsis, where early intervention is crucial. We aim to model patient-specific reward functions in a contextual multi-armed bandit setting. The goal is to leverage patient-specific clinical features to optimize decision-making under uncertainty. This paper proposes NeuroSep-CP-LCB, a novel integration of neural networks with contextual bandits and conformal prediction tailored for early sepsis detection. Unlike the algorithm pool selection problem in the previous paper, where the primary focus was identifying the most suitable pre-trained model for prediction tasks, this work directly models the reward function using a neural network, allowing for personalized and adaptive decision-making. Combining the representational power of neural networks with the robustness of conformal prediction intervals, this framework explicitly accounts for uncertainty in offline data distributions and provides actionable confidence bounds on predictions.
Sepsyn-OLCP: An Online Learning-based Framework for Early Sepsis Prediction with Uncertainty Quantification using Conformal Prediction
Mar 18, 2025



Sepsis is a life-threatening syndrome with high morbidity and mortality in hospitals. Early prediction of sepsis plays a crucial role in facilitating early interventions for septic patients. However, early sepsis prediction systems with uncertainty quantification and adaptive learning are scarce. This paper proposes Sepsyn-OLCP, a novel online learning algorithm for early sepsis prediction by integrating conformal prediction for uncertainty quantification and Bayesian bandits for adaptive decision-making. By combining the robustness of Bayesian models with the statistical uncertainty guarantees of conformal prediction methodologies, this algorithm delivers accurate and trustworthy predictions, addressing the critical need for reliable and adaptive systems in high-stakes healthcare applications such as early sepsis prediction. We evaluate the performance of Sepsyn-OLCP in terms of regret in stochastic bandit setting, the area under the receiver operating characteristic curve (AUROC), and F-measure. Our results show that Sepsyn-OLCP outperforms existing individual models, increasing AUROC of a neural network from 0.64 to 0.73 without retraining and high computational costs. And the model selection policy converges to the optimal strategy in the long run. We propose a novel reinforcement learning-based framework integrated with conformal prediction techniques to provide uncertainty quantification for early sepsis prediction. The proposed methodology delivers accurate and trustworthy predictions, addressing a critical need in high-stakes healthcare applications like early sepsis prediction.
Deep Representation Learning-Based Dynamic Trajectory Phenotyping for Acute Respiratory Failure in Medical Intensive Care Units
May 04, 2024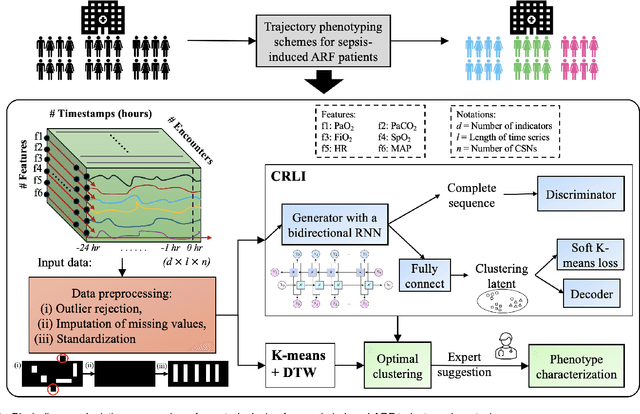
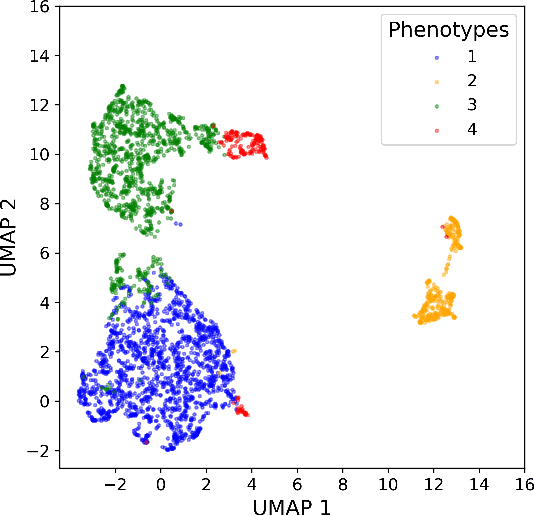
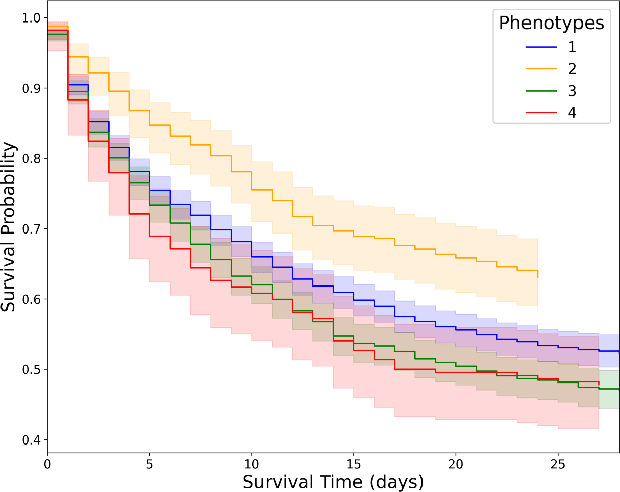
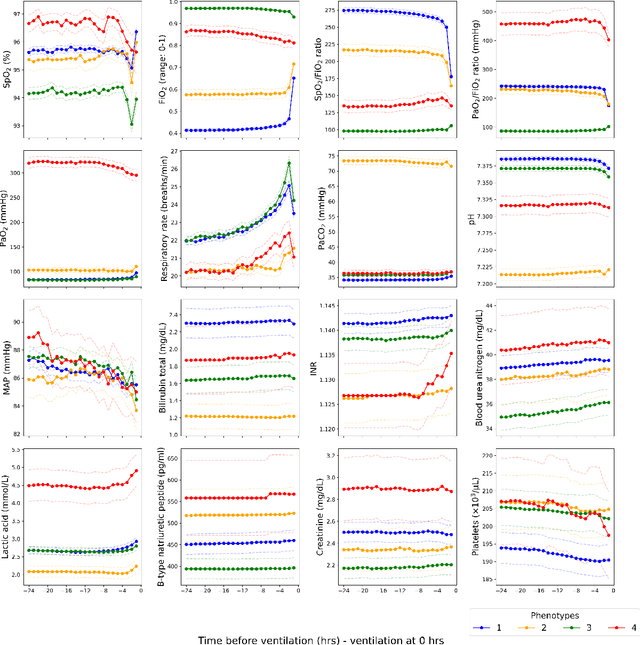
Sepsis-induced acute respiratory failure (ARF) is a serious complication with a poor prognosis. This paper presents a deep representation learningbased phenotyping method to identify distinct groups of clinical trajectories of septic patients with ARF. For this retrospective study, we created a dataset from electronic medical records (EMR) consisting of data from sepsis patients admitted to medical intensive care units who required at least 24 hours of invasive mechanical ventilation at a quarternary care academic hospital in southeast USA for the years 2016-2021. A total of N=3349 patient encounters were included in this study. Clustering Representation Learning on Incomplete Time Series Data (CRLI) algorithm was applied to a parsimonious set of EMR variables in this data set. To validate the optimal number of clusters, the K-means algorithm was used in conjunction with dynamic time warping. Our model yielded four distinct patient phenotypes that were characterized as liver dysfunction/heterogeneous, hypercapnia, hypoxemia, and multiple organ dysfunction syndrome by a critical care expert. A Kaplan-Meier analysis to compare the 28-day mortality trends exhibited significant differences (p < 0.005) between the four phenotypes. The study demonstrates the utility of our deep representation learning-based approach in unraveling phenotypes that reflect the heterogeneity in sepsis-induced ARF in terms of different mortality outcomes and severity. These phenotypes might reveal important clinical insights into an effective prognosis and tailored treatment strategies.
Social Media as a Sensor: Analyzing Twitter Data for Breast Cancer Medication Effects Using Natural Language Processing
Feb 26, 2024Breast cancer is a significant public health concern and is the leading cause of cancer-related deaths among women. Despite advances in breast cancer treatments, medication non-adherence remains a major problem. As electronic health records do not typically capture patient-reported outcomes that may reveal information about medication-related experiences, social media presents an attractive resource for enhancing our understanding of the patients' treatment experiences. In this paper, we developed natural language processing (NLP) based methodologies to study information posted by an automatically curated breast cancer cohort from social media. We employed a transformer-based classifier to identify breast cancer patients/survivors on X (Twitter) based on their self-reported information, and we collected longitudinal data from their profiles. We then designed a multi-layer rule-based model to develop a breast cancer therapy-associated side effect lexicon and detect patterns of medication usage and associated side effects among breast cancer patients. 1,454,637 posts were available from 583,962 unique users, of which 62,042 were detected as breast cancer members using our transformer-based model. 198 cohort members mentioned breast cancer medications with tamoxifen as the most common. Our side effect lexicon identified well-known side effects of hormone and chemotherapy. Furthermore, it discovered a subject feeling towards cancer and medications, which may suggest a pre-clinical phase of side effects or emotional distress. This analysis highlighted not only the utility of NLP techniques in unstructured social media data to identify self-reported breast cancer posts, medication usage patterns, and treatment side effects but also the richness of social data on such clinical questions.
Robust Meta-Model for Predicting the Need for Blood Transfusion in Non-traumatic ICU Patients
Jan 01, 2024Objective: Blood transfusions, crucial in managing anemia and coagulopathy in ICU settings, require accurate prediction for effective resource allocation and patient risk assessment. However, existing clinical decision support systems have primarily targeted a particular patient demographic with unique medical conditions and focused on a single type of blood transfusion. This study aims to develop an advanced machine learning-based model to predict the probability of transfusion necessity over the next 24 hours for a diverse range of non-traumatic ICU patients. Methods: We conducted a retrospective cohort study on 72,072 adult non-traumatic ICU patients admitted to a high-volume US metropolitan academic hospital between 2016 and 2020. We developed a meta-learner and various machine learning models to serve as predictors, training them annually with four-year data and evaluating on the fifth, unseen year, iteratively over five years. Results: The experimental results revealed that the meta-model surpasses the other models in different development scenarios. It achieved notable performance metrics, including an Area Under the Receiver Operating Characteristic (AUROC) curve of 0.97, an accuracy rate of 0.93, and an F1-score of 0.89 in the best scenario. Conclusion: This study pioneers the use of machine learning models for predicting blood transfusion needs in a diverse cohort of critically ill patients. The findings of this evaluation confirm that our model not only predicts transfusion requirements effectively but also identifies key biomarkers for making transfusion decisions.
Detecting algorithmic bias in medical AI-models
Dec 06, 2023With the growing prevalence of machine learning and artificial intelligence-based medical decision support systems, it is equally important to ensure that these systems provide patient outcomes in a fair and equitable fashion. This paper presents an innovative framework for detecting areas of algorithmic bias in medical-AI decision support systems. Our approach efficiently identifies potential biases in medical-AI models, specifically in the context of sepsis prediction, by employing the Classification and Regression Trees (CART) algorithm. We verify our methodology by conducting a series of synthetic data experiments, showcasing its ability to estimate areas of bias in controlled settings precisely. The effectiveness of the concept is further validated by experiments using electronic medical records from Grady Memorial Hospital in Atlanta, Georgia. These tests demonstrate the practical implementation of our strategy in a clinical environment, where it can function as a vital instrument for guaranteeing fairness and equity in AI-based medical decisions.
Mixed-Integer Projections for Automated Data Correction of EMRs Improve Predictions of Sepsis among Hospitalized Patients
Aug 21, 2023Machine learning (ML) models are increasingly pivotal in automating clinical decisions. Yet, a glaring oversight in prior research has been the lack of proper processing of Electronic Medical Record (EMR) data in the clinical context for errors and outliers. Addressing this oversight, we introduce an innovative projections-based method that seamlessly integrates clinical expertise as domain constraints, generating important meta-data that can be used in ML workflows. In particular, by using high-dimensional mixed-integer programs that capture physiological and biological constraints on patient vitals and lab values, we can harness the power of mathematical "projections" for the EMR data to correct patient data. Consequently, we measure the distance of corrected data from the constraints defining a healthy range of patient data, resulting in a unique predictive metric we term as "trust-scores". These scores provide insight into the patient's health status and significantly boost the performance of ML classifiers in real-life clinical settings. We validate the impact of our framework in the context of early detection of sepsis using ML. We show an AUROC of 0.865 and a precision of 0.922, that surpasses conventional ML models without such projections.
Meta-learning in healthcare: A survey
Aug 05, 2023As a subset of machine learning, meta-learning, or learning to learn, aims at improving the model's capabilities by employing prior knowledge and experience. A meta-learning paradigm can appropriately tackle the conventional challenges of traditional learning approaches, such as insufficient number of samples, domain shifts, and generalization. These unique characteristics position meta-learning as a suitable choice for developing influential solutions in various healthcare contexts, where the available data is often insufficient, and the data collection methodologies are different. This survey discusses meta-learning broad applications in the healthcare domain to provide insight into how and where it can address critical healthcare challenges. We first describe the theoretical foundations and pivotal methods of meta-learning. We then divide the employed meta-learning approaches in the healthcare domain into two main categories of multi/single-task learning and many/few-shot learning and survey the studies. Finally, we highlight the current challenges in meta-learning research, discuss the potential solutions and provide future perspectives on meta-learning in healthcare.