 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Meta-Model for Predicting the Need for Blood Transfusion in Non-traumatic ICU Patients
Jan 01, 2024Objective: Blood transfusions, crucial in managing anemia and coagulopathy in ICU settings, require accurate prediction for effective resource allocation and patient risk assessment. However, existing clinical decision support systems have primarily targeted a particular patient demographic with unique medical conditions and focused on a single type of blood transfusion. This study aims to develop an advanced machine learning-based model to predict the probability of transfusion necessity over the next 24 hours for a diverse range of non-traumatic ICU patients. Methods: We conducted a retrospective cohort study on 72,072 adult non-traumatic ICU patients admitted to a high-volume US metropolitan academic hospital between 2016 and 2020. We developed a meta-learner and various machine learning models to serve as predictors, training them annually with four-year data and evaluating on the fifth, unseen year, iteratively over five years. Results: The experimental results revealed that the meta-model surpasses the other models in different development scenarios. It achieved notable performance metrics, including an Area Under the Receiver Operating Characteristic (AUROC) curve of 0.97, an accuracy rate of 0.93, and an F1-score of 0.89 in the best scenario. Conclusion: This study pioneers the use of machine learning models for predicting blood transfusion needs in a diverse cohort of critically ill patients. The findings of this evaluation confirm that our model not only predicts transfusion requirements effectively but also identifies key biomarkers for making transfusion decisions.
The EMory BrEast imaging Dataset : A Racially Diverse, Granular Dataset of 3.5M Screening and Diagnostic Mammograms
Feb 08, 2022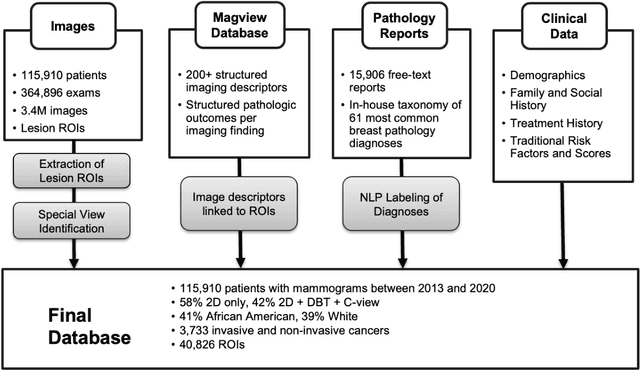
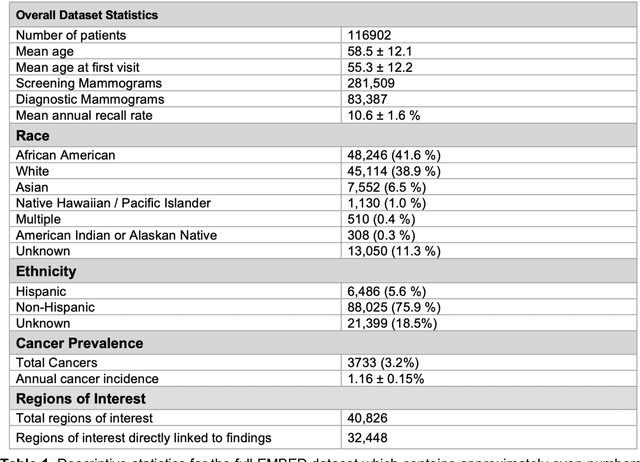
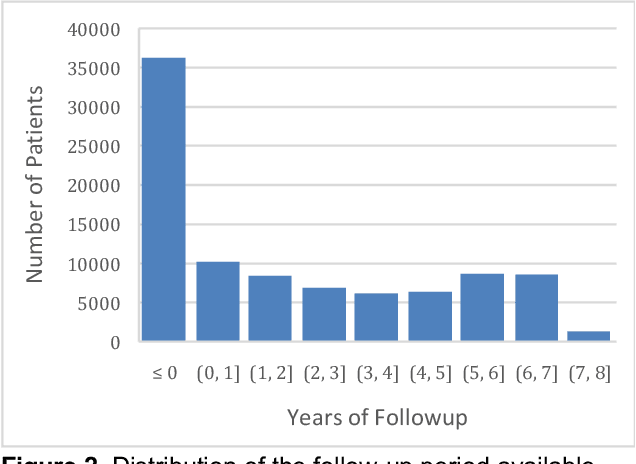

Developing and validating artificial intelligence models in medical imaging requires datasets that are large, granular, and diverse. To date, the majority of publicly available breast imaging datasets lack in one or more of these areas. Models trained on these data may therefore underperform on patient populations or pathologies that have not previously been encountered. The EMory BrEast imaging Dataset (EMBED) addresses these gaps by providing 3650,000 2D and DBT screening and diagnostic mammograms for 116,000 women divided equally between White and African American patients. The dataset also contains 40,000 annotated lesions linked to structured imaging descriptors and 61 ground truth pathologic outcomes grouped into six severity classes. Our goal is to share this dataset with research partners to aid in development and validation of breast AI models that will serve all patients fairly and help decrease bias in medical AI.
Resource Discovery in Trilogy
Feb 08, 1999
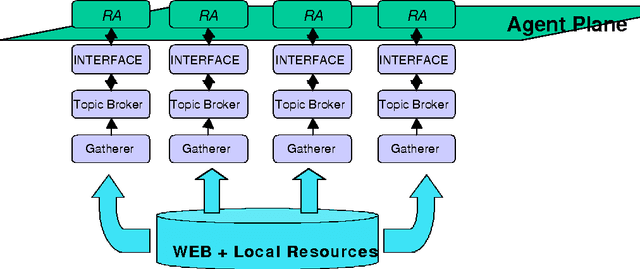
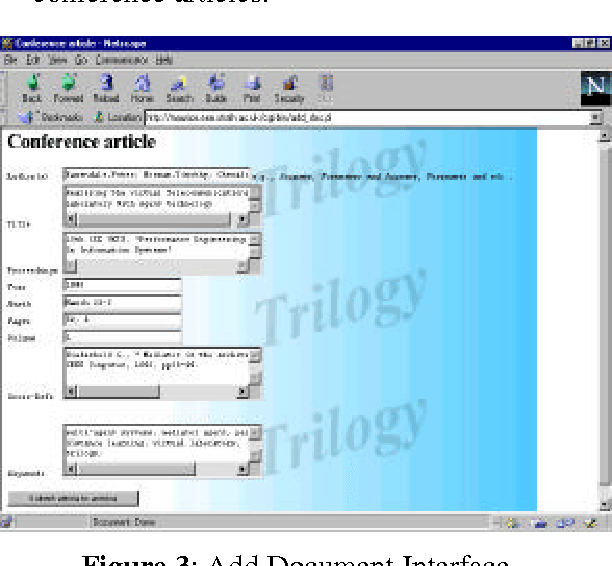

Trilogy is a collaborative project whose key aim is the development of an integrated virtual laboratory to support research training within each institution and collaborative projects between the partners. In this paper, the architecture and underpinning platform of the system is described with particular emphasis being placed on the structure and the integration of the distributed database. A key element is the ontology that provides the multi-agent system with a conceptualisation specification of the domain; this ontology is explained, accompanied by a discussion how such a system is integrated and used within the virtual laboratory. Although in this paper, Telecommunications and in particular Broadband networks are used as exemplars, the underlying system principles are applicable to any domain where a combination of experimental and literature-based resources are required.