 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUE-R: Beyond the Final Answer in Retrieval-Augmented Generation
Apr 07, 2026As language models shift from single-shot answer generation toward multi-step reasoning that retrieves and consumes evidence mid-inference, evaluating the role of individual retrieved items becomes more important. Existing RAG evaluation typically targets final-answer quality, citation faithfulness, or answer-level attribution, but none of these directly targets the intervention-based, per-evidence-item utility view we study here. We introduce CUE-R, a lightweight intervention-based framework for measuring per-evidence-item operational utility in single-shot RAG using shallow observable retrieval-use traces. CUE-R perturbs individual evidence items via REMOVE, REPLACE, and DUPLICATE operators, then measures changes along three utility axes (correctness, proxy-based grounding faithfulness, and confidence error) plus a trace-divergence signal. We also outline an operational evidence-role taxonomy for interpreting intervention outcomes. Experiments on HotpotQA and 2WikiMultihopQA with Qwen-3 8B and GPT-5.2 reveal a consistent pattern: REMOVE and REPLACE substantially harm correctness and grounding while producing large trace shifts, whereas DUPLICATE is often answer-redundant yet not fully behaviorally neutral. A zero-retrieval control confirms that these effects arise from degradation of meaningful retrieval. A two-support ablation further shows that multi-hop evidence items can interact non-additively: removing both supports harms performance far more than either single removal. Our results suggest that answer-only evaluation misses important evidence effects and that intervention-based utility analysis is a practical complement for RAG evaluation.
The Next 700 ML-Enabled Compiler Optimizations
Nov 17, 2023There is a growing interest in enhancing compiler optimizations with ML models, yet interactions between compilers and ML frameworks remain challenging. Some optimizations require tightly coupled models and compiler internals,raising issues with modularity, performance and framework independence. Practical deployment and transparency for the end-user are also important concerns. We propose ML-Compiler-Bridge to enable ML model development within a traditional Python framework while making end-to-end integration with an optimizing compiler possible and efficient. We evaluate it on both research and production use cases, for training and inference, over several optimization problems, multiple compilers and its versions, and gym infrastructures.
Distribution Re-weighting and Voting Paradoxes
Nov 12, 2023



We explore a specific type of distribution shift called domain expertise, in which training is limited to a subset of all possible labels. This setting is common among specialized human experts, or specific focused studies. We show how the standard approach to distribution shift, which involves re-weighting data, can result in paradoxical disagreements among differing domain expertise. We also demonstrate how standard adjustments for causal inference lead to the same paradox. We prove that the characteristics of these paradoxes exactly mimic another set of paradoxes which arise among sets of voter preferences.
RL4ReAl: Reinforcement Learning for Register Allocation
Apr 05, 2022

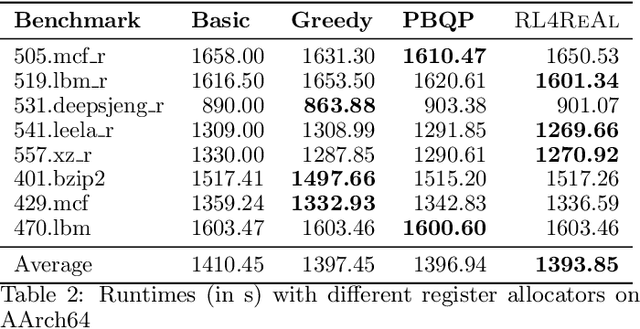
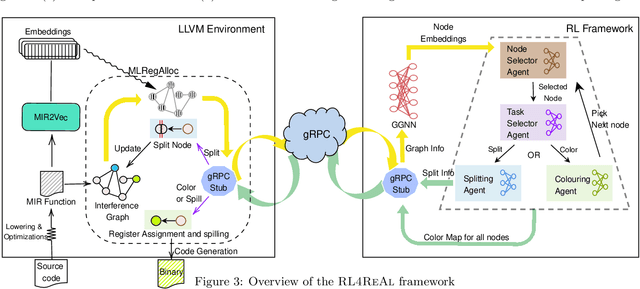
We propose a novel solution for the Register Allocation problem, leveraging multi-agent hierarchical Reinforcement Learning. We formalize the constraints that precisely define the problem for a given instruction-set architecture, while ensuring that the generated code preserves semantic correctness. We also develop a gRPC based framework providing a modular and efficient compiler interface for training and inference. Experimental results match or outperform the LLVM register allocators, targeting Intel x86 and ARM AArch64.
Expert Graphs: Synthesizing New Expertise via Collaboration
Jul 15, 2021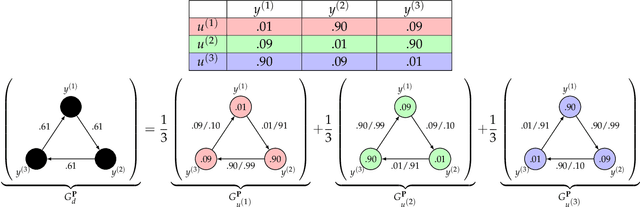

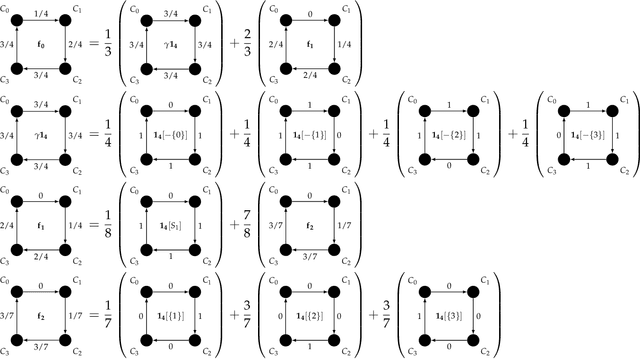
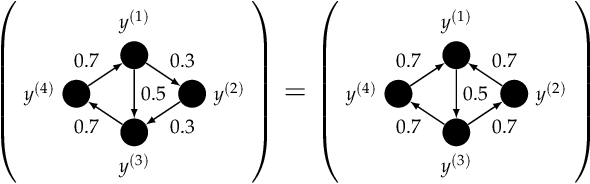
Consider multiple experts with overlapping expertise working on a classification problem under uncertain input. What constitutes a consistent set of opinions? How can we predict the opinions of experts on missing sub-domains? In this paper, we define a framework of to analyze this problem, termed "expert graphs." In an expert graph, vertices represent classes and edges represent binary opinions on the topics of their vertices. We derive necessary conditions for expert graph validity and use them to create "synthetic experts" which describe opinions consistent with the observed opinions of other experts. We show this framework to be equivalent to the well-studied linear ordering polytope. We show our conditions are not sufficient for describing all expert graphs on cliques, but are sufficient for cycles.
Robust Correction of Sampling Bias Using Cumulative Distribution Functions
Oct 23, 2020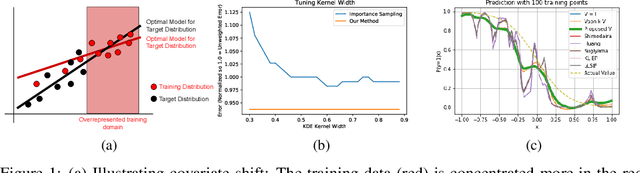
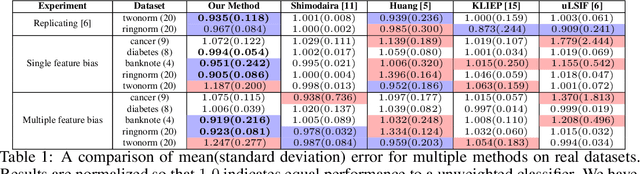
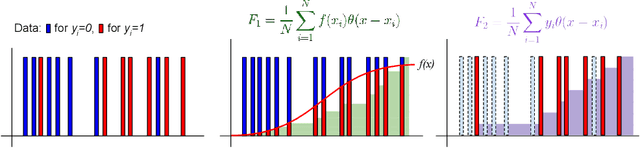

Varying domains and biased datasets can lead to differences between the training and the target distributions, known as covariate shift. Current approaches for alleviating this often rely on estimating the ratio of training and target probability density functions. These techniques require parameter tuning and can be unstable across different datasets. We present a new method for handling covariate shift using the empirical cumulative distribution function estimates of the target distribution by a rigorous generalization of a recent idea proposed by Vapnik and Izmailov. Further, we show experimentally that our method is more robust in its predictions, is not reliant on parameter tuning and shows similar classification performance compared to the current state-of-the-art techniques on synthetic and real datasets.
CodNN -- Robust Neural Networks From Coded Classification
Apr 29, 2020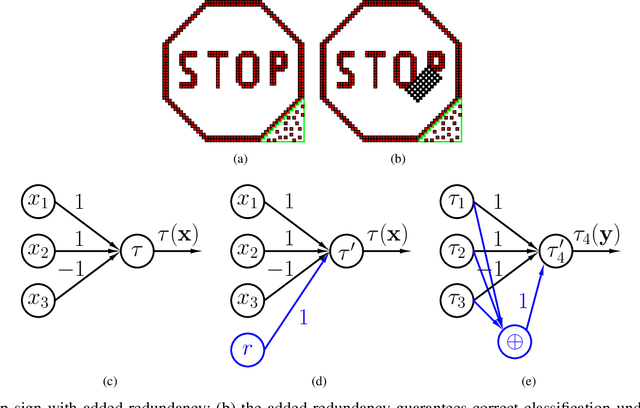
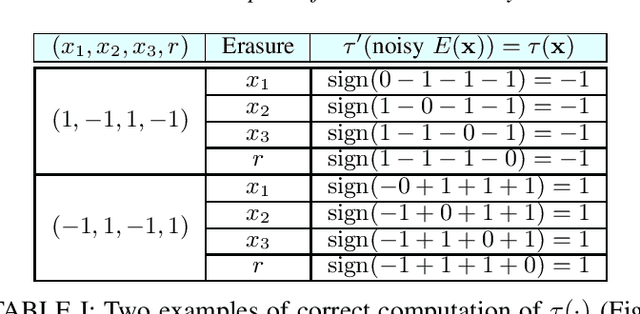
Deep Neural Networks (DNNs) are a revolutionary force in the ongoing information revolution, and yet their intrinsic properties remain a mystery. In particular, it is widely known that DNNs are highly sensitive to noise, whether adversarial or random. This poses a fundamental challenge for hardware implementations of DNNs, and for their deployment in critical applications such as autonomous driving. In this paper we construct robust DNNs via error correcting codes. By our approach, either the data or internal layers of the DNN are coded with error correcting codes, and successful computation under noise is guaranteed. Since DNNs can be seen as a layered concatenation of classification tasks, our research begins with the core task of classifying noisy coded inputs, and progresses towards robust DNNs. We focus on binary data and linear codes. Our main result is that the prevalent parity code can guarantee robustness for a large family of DNNs, which includes the recently popularized binarized neural networks. Further, we show that the coded classification problem has a deep connection to Fourier analysis of Boolean functions. In contrast to existing solutions in the literature, our results do not rely on altering the training process of the DNN, and provide mathematically rigorous guarantees rather than experimental evidence.
What is the Value of Data? On Mathematical Methods for Data Quality Estimation
Jan 09, 2020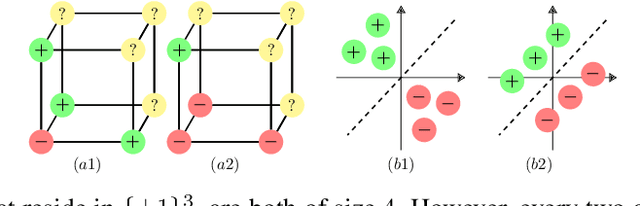
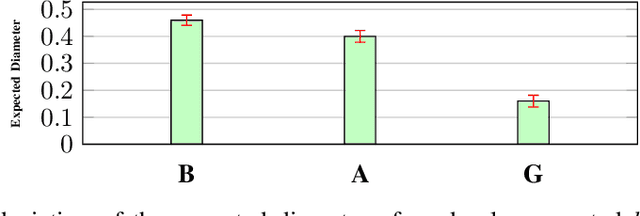
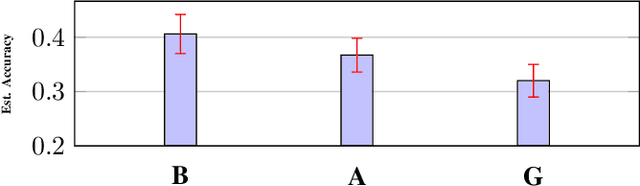
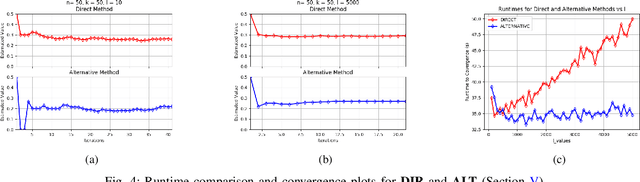
Data is one of the most important assets of the information age, and its societal impact is undisputed. Yet, rigorous methods of assessing the quality of data are lacking. In this paper, we propose a formal definition for the quality of a given dataset. We assess a dataset's quality by a quantity we call the expected diameter, which measures the expected disagreement between two randomly chosen hypotheses that explain it, and has recently found applications in active learning. We focus on Boolean hyperplanes, and utilize a collection of Fourier analytic, algebraic, and probabilistic methods to come up with theoretical guarantees and practical solutions for the computation of the expected diameter. We also study the behaviour of the expected diameter on algebraically structured datasets, conduct experiments that validate this notion of quality, and demonstrate the feasibility of our techniques.