 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagellan: Autonomous Discovery of Novel Compiler Optimization Heuristics with AlphaEvolve
Jan 28, 2026Modern compilers rely on hand-crafted heuristics to guide optimization passes. These human-designed rules often struggle to adapt to the complexity of modern software and hardware and lead to high maintenance burden. To address this challenge, we present Magellan, an agentic framework that evolves the compiler pass itself by synthesizing executable C++ decision logic. Magellan couples an LLM coding agent with evolutionary search and autotuning in a closed loop of generation, evaluation on user-provided macro-benchmarks, and refinement, producing compact heuristics that integrate directly into existing compilers. Across several production optimization tasks, Magellan discovers policies that match or surpass expert baselines. In LLVM function inlining, Magellan synthesizes new heuristics that outperform decades of manual engineering for both binary-size reduction and end-to-end performance. In register allocation, it learns a concise priority rule for live-range processing that matches intricate human-designed policies on a large-scale workload. We also report preliminary results on XLA problems, demonstrating portability beyond LLVM with reduced engineering effort.
Offline Imitation Learning from Multiple Baselines with Applications to Compiler Optimization
Mar 28, 2024



This work studies a Reinforcement Learning (RL) problem in which we are given a set of trajectories collected with K baseline policies. Each of these policies can be quite suboptimal in isolation, and have strong performance in complementary parts of the state space. The goal is to learn a policy which performs as well as the best combination of baselines on the entire state space. We propose a simple imitation learning based algorithm, show a sample complexity bound on its accuracy and prove that the the algorithm is minimax optimal by showing a matching lower bound. Further, we apply the algorithm in the setting of machine learning guided compiler optimization to learn policies for inlining programs with the objective of creating a small binary. We demonstrate that we can learn a policy that outperforms an initial policy learned via standard RL through a few iterations of our approach.
The Next 700 ML-Enabled Compiler Optimizations
Nov 17, 2023There is a growing interest in enhancing compiler optimizations with ML models, yet interactions between compilers and ML frameworks remain challenging. Some optimizations require tightly coupled models and compiler internals,raising issues with modularity, performance and framework independence. Practical deployment and transparency for the end-user are also important concerns. We propose ML-Compiler-Bridge to enable ML model development within a traditional Python framework while making end-to-end integration with an optimizing compiler possible and efficient. We evaluate it on both research and production use cases, for training and inference, over several optimization problems, multiple compilers and its versions, and gym infrastructures.
MLGO: a Machine Learning Guided Compiler Optimizations Framework
Jan 13, 2021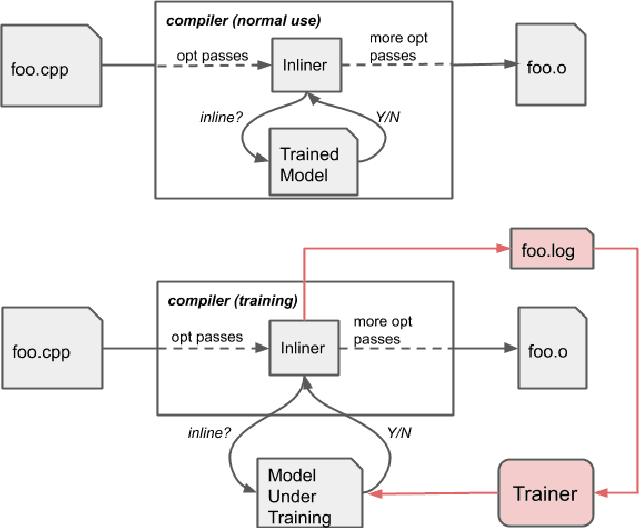
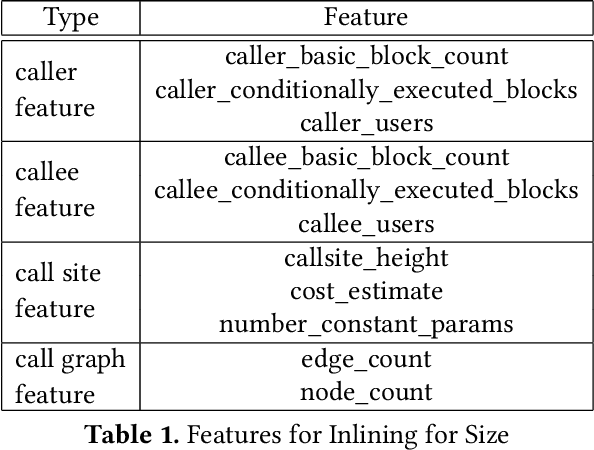
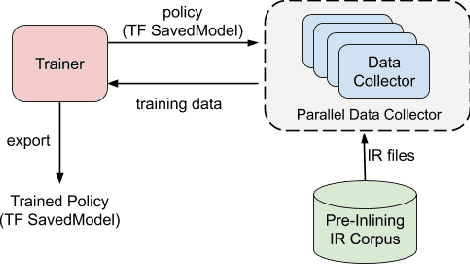
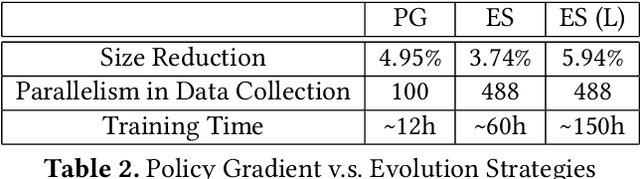
Leveraging machine-learning (ML) techniques for compiler optimizations has been widely studied and explored in academia. However, the adoption of ML in general-purpose, industry strength compilers has yet to happen. We propose MLGO, a framework for integrating ML techniques systematically in an industrial compiler -- LLVM. As a case study, we present the details and results of replacing the heuristics-based inlining-for-size optimization in LLVM with machine learned models. To the best of our knowledge, this work is the first full integration of ML in a complex compiler pass in a real-world setting. It is available in the main LLVM repository. We use two different ML algorithms: Policy Gradient and Evolution Strategies, to train the inlining-for-size model, and achieve up to 7\% size reduction, when compared to state of the art LLVM -Oz. The same model, trained on one corpus, generalizes well to a diversity of real-world targets, as well as to the same set of targets after months of active development. This property of the trained models is beneficial to deploy ML techniques in real-world settings.