 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Reasoning Models Ace the CFA Exams
Dec 09, 2025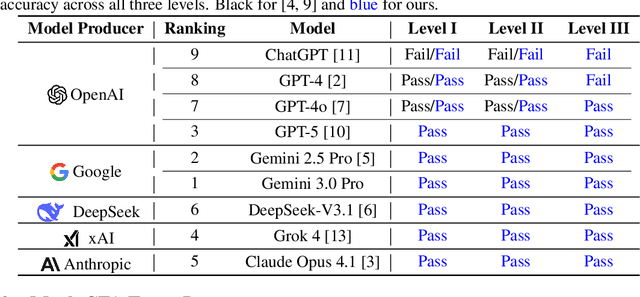
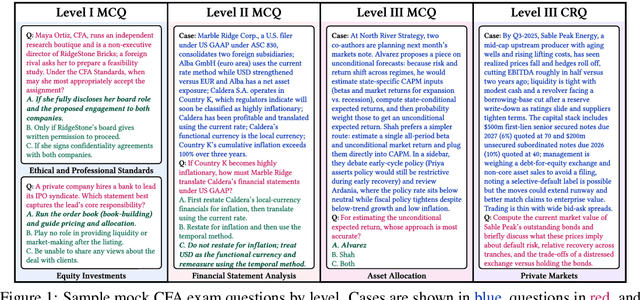
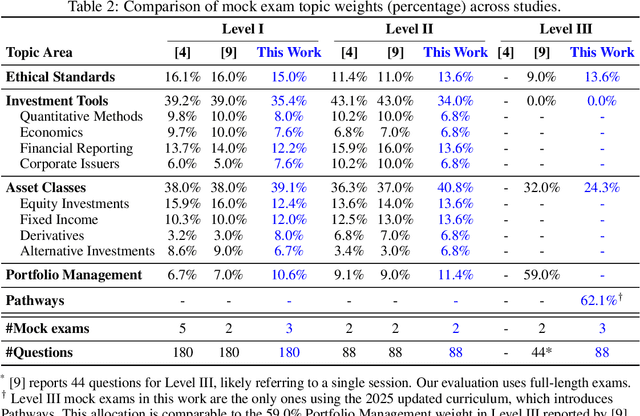
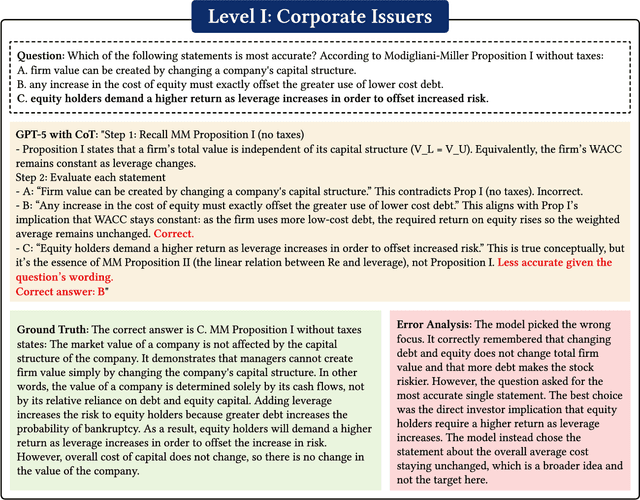
Previous research has reported that large language models (LLMs) demonstrate poor performance on the Chartered Financial Analyst (CFA) exams. However, recent reasoning models have achieved strong results on graduate-level academic and professional examinations across various disciplines. In this paper, we evaluate state-of-the-art reasoning models on a set of mock CFA exams consisting of 980 questions across three Level I exams, two Level II exams, and three Level III exams. Using the same pass/fail criteria from prior studies, we find that most models clear all three levels. The models that pass, ordered by overall performance, are Gemini 3.0 Pro, Gemini 2.5 Pro, GPT-5, Grok 4, Claude Opus 4.1, and DeepSeek-V3.1. Specifically, Gemini 3.0 Pro achieves a record score of 97.6% on Level I. Performance is also strong on Level II, led by GPT-5 at 94.3%. On Level III, Gemini 2.5 Pro attains the highest score with 86.4% on multiple-choice questions while Gemini 3.0 Pro achieves 92.0% on constructed-response questions.
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Oct 05, 2025



We introduce GDPval, a benchmark evaluating AI model capabilities on real-world economically valuable tasks. GDPval covers the majority of U.S. Bureau of Labor Statistics Work Activities for 44 occupations across the top 9 sectors contributing to U.S. GDP (Gross Domestic Product). Tasks are constructed from the representative work of industry professionals with an average of 14 years of experience. We find that frontier model performance on GDPval is improving roughly linearly over time, and that the current best frontier models are approaching industry experts in deliverable quality. We analyze the potential for frontier models, when paired with human oversight, to perform GDPval tasks cheaper and faster than unaided experts. We also demonstrate that increased reasoning effort, increased task context, and increased scaffolding improves model performance on GDPval. Finally, we open-source a gold subset of 220 tasks and provide a public automated grading service at evals.openai.com to facilitate future research in understanding real-world model capabilities.
Universal Inverse Distillation for Matching Models with Real-Data Supervision (No GANs)
Sep 26, 2025While achieving exceptional generative quality, modern diffusion, flow, and other matching models suffer from slow inference, as they require many steps of iterative generation. Recent distillation methods address this by training efficient one-step generators under the guidance of a pre-trained teacher model. However, these methods are often constrained to only one specific framework, e.g., only to diffusion or only to flow models. Furthermore, these methods are naturally data-free, and to benefit from the usage of real data, it is required to use an additional complex adversarial training with an extra discriminator model. In this paper, we present RealUID, a universal distillation framework for all matching models that seamlessly incorporates real data into the distillation procedure without GANs. Our RealUID approach offers a simple theoretical foundation that covers previous distillation methods for Flow Matching and Diffusion models, and is also extended to their modifications, such as Bridge Matching and Stochastic Interpolants.
Energy Consumption in Parallel Neural Network Training
Aug 11, 2025The increasing demand for computational resources of training neural networks leads to a concerning growth in energy consumption. While parallelization has enabled upscaling model and dataset sizes and accelerated training, its impact on energy consumption is often overlooked. To close this research gap, we conducted scaling experiments for data-parallel training of two models, ResNet50 and FourCastNet, and evaluated the impact of parallelization parameters, i.e., GPU count, global batch size, and local batch size, on predictive performance, training time, and energy consumption. We show that energy consumption scales approximately linearly with the consumed resources, i.e., GPU hours; however, the respective scaling factor differs substantially between distinct model trainings and hardware, and is systematically influenced by the number of samples and gradient updates per GPU hour. Our results shed light on the complex interplay of scaling up neural network training and can inform future developments towards more sustainable AI research.
PoseBench3D: A Cross-Dataset Analysis Framework for 3D Human Pose Estimation
May 16, 2025Reliable three-dimensional human pose estimation is becoming increasingly important for real-world applications, yet much of prior work has focused solely on the performance within a single dataset. In practice, however, systems must adapt to diverse viewpoints, environments, and camera setups -- conditions that differ significantly from those encountered during training, which is often the case in real-world scenarios. To address these challenges, we present a standardized testing environment in which each method is evaluated on a variety of datasets, ensuring consistent and fair cross-dataset comparisons -- allowing for the analysis of methods on previously unseen data. Therefore, we propose PoseBench3D, a unified framework designed to systematically re-evaluate prior and future models across four of the most widely used datasets for human pose estimation -- with the framework able to support novel and future datasets as the field progresses. Through a unified interface, our framework provides datasets in a pre-configured yet easily modifiable format, ensuring compatibility with diverse model architectures. We re-evaluated the work of 18 methods, either trained or gathered from existing literature, and reported results using both Mean Per Joint Position Error (MPJPE) and Procrustes Aligned Mean Per Joint Position Error (PA-MPJPE) metrics, yielding more than 100 novel cross-dataset evaluation results. Additionally, we analyze performance differences resulting from various pre-processing techniques and dataset preparation parameters -- offering further insight into model generalization capabilities.
Large Language Model Compression via the Nested Activation-Aware Decomposition
Mar 21, 2025In this paper, we tackle the critical challenge of compressing large language models (LLMs) to facilitate their practical deployment and broader adoption. We introduce a novel post-training compression paradigm that focuses on low-rank decomposition of LLM weights. Our analysis identifies two main challenges in this task: the variability in LLM activation distributions and handling unseen activations from different datasets and models. To address these challenges, we propose a nested activation-aware framework (NSVD) for LLMs, a training-free approach designed to enhance the accuracy of low-rank decompositions by managing activation outliers through transforming the weight matrix based on activation distribution and the original weight matrix. This method allows for the absorption of outliers into the transformed weight matrix, improving decomposition accuracy. Our comprehensive evaluation across eight datasets and six models from three distinct LLM families demonstrates the superiority of NSVD over current state-of-the-art methods, especially at medium to large compression ratios or in multilingual and multitask settings.
One-Step Residual Shifting Diffusion for Image Super-Resolution via Distillation
Mar 17, 2025Diffusion models for super-resolution (SR) produce high-quality visual results but require expensive computational costs. Despite the development of several methods to accelerate diffusion-based SR models, some (e.g., SinSR) fail to produce realistic perceptual details, while others (e.g., OSEDiff) may hallucinate non-existent structures. To overcome these issues, we present RSD, a new distillation method for ResShift, one of the top diffusion-based SR models. Our method is based on training the student network to produce such images that a new fake ResShift model trained on them will coincide with the teacher model. RSD achieves single-step restoration and outperforms the teacher by a large margin. We show that our distillation method can surpass the other distillation-based method for ResShift - SinSR - making it on par with state-of-the-art diffusion-based SR distillation methods. Compared to SR methods based on pre-trained text-to-image models, RSD produces competitive perceptual quality, provides images with better alignment to degraded input images, and requires fewer parameters and GPU memory. We provide experimental results on various real-world and synthetic datasets, including RealSR, RealSet65, DRealSR, ImageNet, and DIV2K.
Inverse Bridge Matching Distillation
Feb 03, 2025Learning diffusion bridge models is easy; making them fast and practical is an art. Diffusion bridge models (DBMs) are a promising extension of diffusion models for applications in image-to-image translation. However, like many modern diffusion and flow models, DBMs suffer from the problem of slow inference. To address it, we propose a novel distillation technique based on the inverse bridge matching formulation and derive the tractable objective to solve it in practice. Unlike previously developed DBM distillation techniques, the proposed method can distill both conditional and unconditional types of DBMs, distill models in a one-step generator, and use only the corrupted images for training. We evaluate our approach for both conditional and unconditional types of bridge matching on a wide set of setups, including super-resolution, JPEG restoration, sketch-to-image, and other tasks, and show that our distillation technique allows us to accelerate the inference of DBMs from 4x to 100x and even provide better generation quality than used teacher model depending on particular setup.
Medical Semantic Segmentation with Diffusion Pretrain
Jan 31, 2025
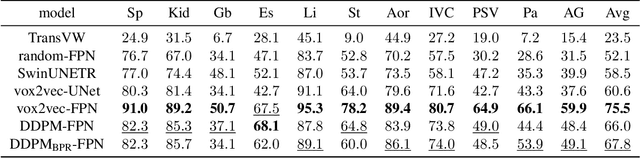
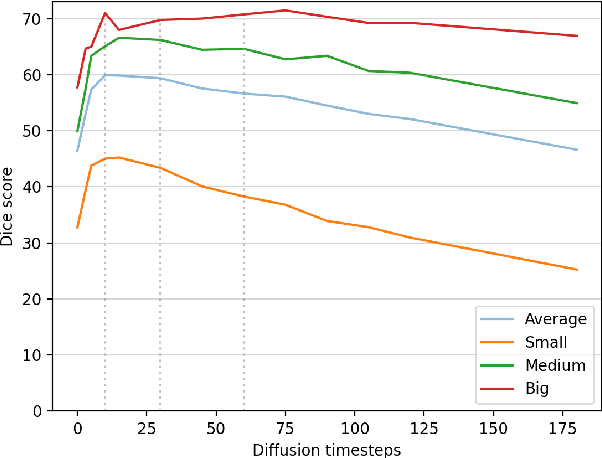
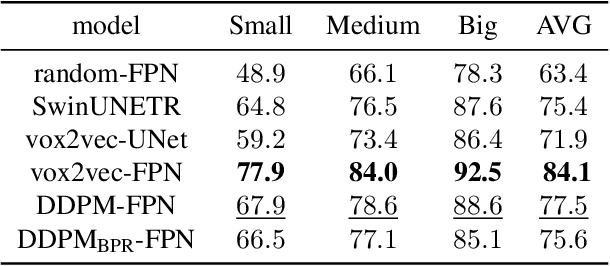
Recent advances in deep learning have shown that learning robust feature representations is critical for the success of many computer vision tasks, including medical image segmentation. In particular, both transformer and convolutional-based architectures have benefit from leveraging pretext tasks for pretraining. However, the adoption of pretext tasks in 3D medical imaging has been less explored and remains a challenge, especially in the context of learning generalizable feature representations. We propose a novel pretraining strategy using diffusion models with anatomical guidance, tailored to the intricacies of 3D medical image data. We introduce an auxiliary diffusion process to pretrain a model that produce generalizable feature representations, useful for a variety of downstream segmentation tasks. We employ an additional model that predicts 3D universal body-part coordinates, providing guidance during the diffusion process and improving spatial awareness in generated representations. This approach not only aids in resolving localization inaccuracies but also enriches the model's ability to understand complex anatomical structures. Empirical validation on a 13-class organ segmentation task demonstrate the effectiveness of our pretraining technique. It surpasses existing restorative pretraining methods in 3D medical image segmentation by $7.5\%$, and is competitive with the state-of-the-art contrastive pretraining approach, achieving an average Dice coefficient of 67.8 in a non-linear evaluation scenario.