 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Compression via the Nested Activation-Aware Decomposition
Mar 21, 2025In this paper, we tackle the critical challenge of compressing large language models (LLMs) to facilitate their practical deployment and broader adoption. We introduce a novel post-training compression paradigm that focuses on low-rank decomposition of LLM weights. Our analysis identifies two main challenges in this task: the variability in LLM activation distributions and handling unseen activations from different datasets and models. To address these challenges, we propose a nested activation-aware framework (NSVD) for LLMs, a training-free approach designed to enhance the accuracy of low-rank decompositions by managing activation outliers through transforming the weight matrix based on activation distribution and the original weight matrix. This method allows for the absorption of outliers into the transformed weight matrix, improving decomposition accuracy. Our comprehensive evaluation across eight datasets and six models from three distinct LLM families demonstrates the superiority of NSVD over current state-of-the-art methods, especially at medium to large compression ratios or in multilingual and multitask settings.
Improving embedding with contrastive fine-tuning on small datasets with expert-augmented scores
Aug 19, 2024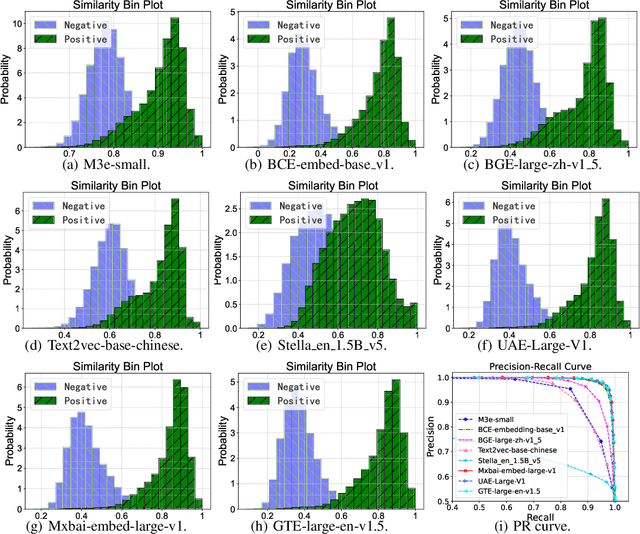
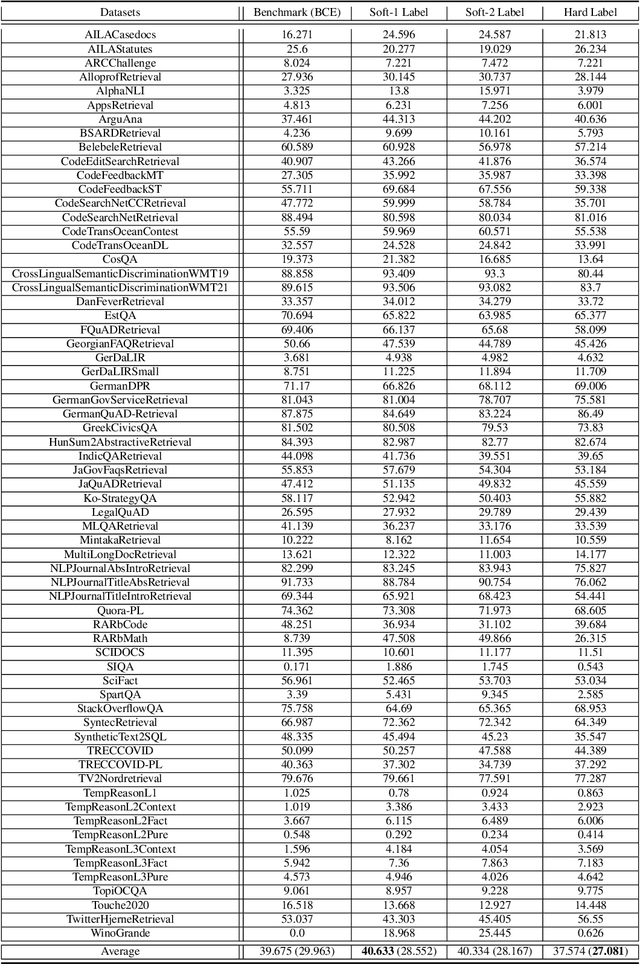
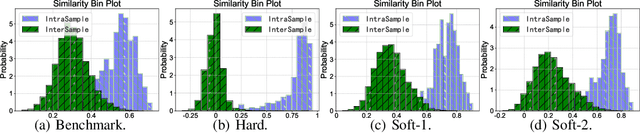

This paper presents an approach to improve text embedding models through contrastive fine-tuning on small datasets augmented with expert scores. It focuses on enhancing semantic textual similarity tasks and addressing text retrieval problems. The proposed method uses soft labels derived from expert-augmented scores to fine-tune embedding models, preserving their versatility and ensuring retrieval capability is improved. The paper evaluates the method using a Q\&A dataset from an online shopping website and eight expert models. Results show improved performance over a benchmark model across multiple metrics on various retrieval tasks from the massive text embedding benchmark (MTEB). The method is cost-effective and practical for real-world applications, especially when labeled data is scarce.