 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAMS:Dual-Branch Adaptive Multiscale Spatiotemporal Framework for Video Anomaly Detection
Jul 28, 2025



The goal of video anomaly detection is tantamount to performing spatio-temporal localization of abnormal events in the video. The multiscale temporal dependencies, visual-semantic heterogeneity, and the scarcity of labeled data exhibited by video anomalies collectively present a challenging research problem in computer vision. This study offers a dual-path architecture called the Dual-Branch Adaptive Multiscale Spatiotemporal Framework (DAMS), which is based on multilevel feature decoupling and fusion, enabling efficient anomaly detection modeling by integrating hierarchical feature learning and complementary information. The main processing path of this framework integrates the Adaptive Multiscale Time Pyramid Network (AMTPN) with the Convolutional Block Attention Mechanism (CBAM). AMTPN enables multigrained representation and dynamically weighted reconstruction of temporal features through a three-level cascade structure (time pyramid pooling, adaptive feature fusion, and temporal context enhancement). CBAM maximizes the entropy distribution of feature channels and spatial dimensions through dual attention mapping. Simultaneously, the parallel path driven by CLIP introduces a contrastive language-visual pre-training paradigm. Cross-modal semantic alignment and a multiscale instance selection mechanism provide high-order semantic guidance for spatio-temporal features. This creates a complete inference chain from the underlying spatio-temporal features to high-level semantic concepts. The orthogonal complementarity of the two paths and the information fusion mechanism jointly construct a comprehensive representation and identification capability for anomalous events. Extensive experimental results on the UCF-Crime and XD-Violence benchmarks establish the effectiveness of the DAMS framework.
Insect-Computer Hybrid Speaker: Speaker using Chirp of the Cicada Controlled by Electrical Muscle Stimulation
Apr 23, 2025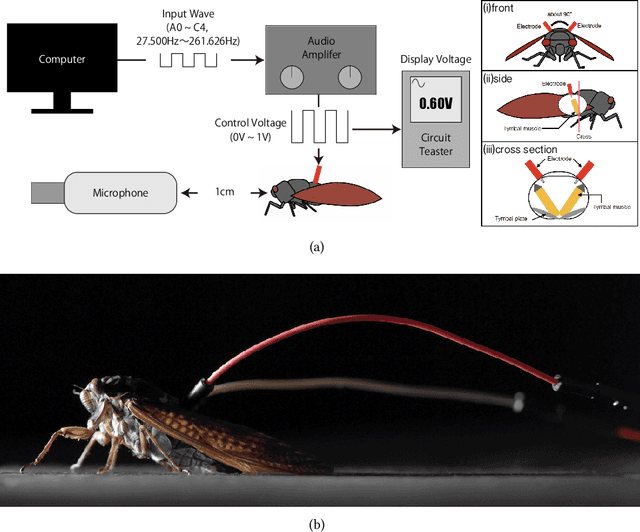

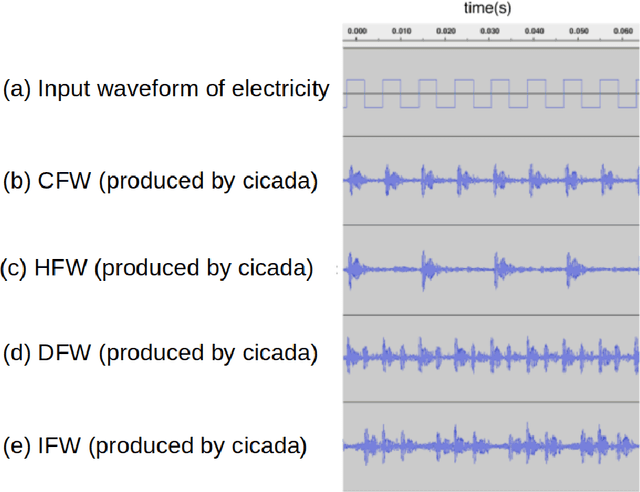
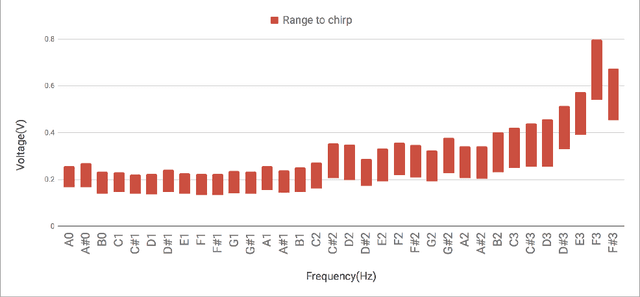
We propose "Insect-Computer Hybrid Speaker", which enables us to make musics made from combinations of computer and insects. Lots of studies have proposed methods and interfaces for controlling insects and obtaining feedback. However, there have been less research on the use of insects for interaction with third parties. In this paper, we propose a method in which cicadas are used as speakers triggered by using Electrical Muscle Stimulation (EMS). We explored and investigated the suitable waveform of chirp to be controlled, the appropriate voltage range, and the maximum pitch at which cicadas can chirp.
Large Language Model Compression via the Nested Activation-Aware Decomposition
Mar 21, 2025In this paper, we tackle the critical challenge of compressing large language models (LLMs) to facilitate their practical deployment and broader adoption. We introduce a novel post-training compression paradigm that focuses on low-rank decomposition of LLM weights. Our analysis identifies two main challenges in this task: the variability in LLM activation distributions and handling unseen activations from different datasets and models. To address these challenges, we propose a nested activation-aware framework (NSVD) for LLMs, a training-free approach designed to enhance the accuracy of low-rank decompositions by managing activation outliers through transforming the weight matrix based on activation distribution and the original weight matrix. This method allows for the absorption of outliers into the transformed weight matrix, improving decomposition accuracy. Our comprehensive evaluation across eight datasets and six models from three distinct LLM families demonstrates the superiority of NSVD over current state-of-the-art methods, especially at medium to large compression ratios or in multilingual and multitask settings.
Generalizable Machine Learning Models for Predicting Data Center Server Power, Efficiency, and Throughput
Mar 09, 2025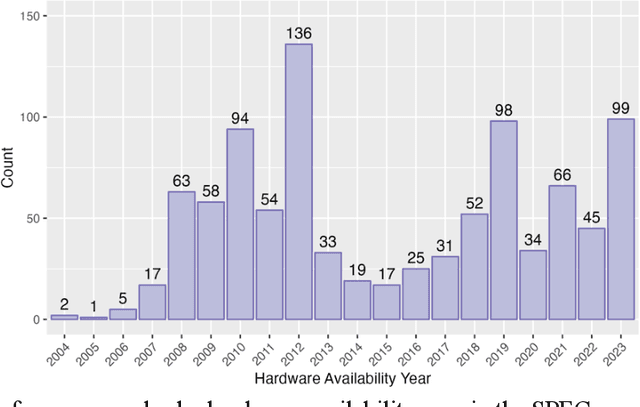
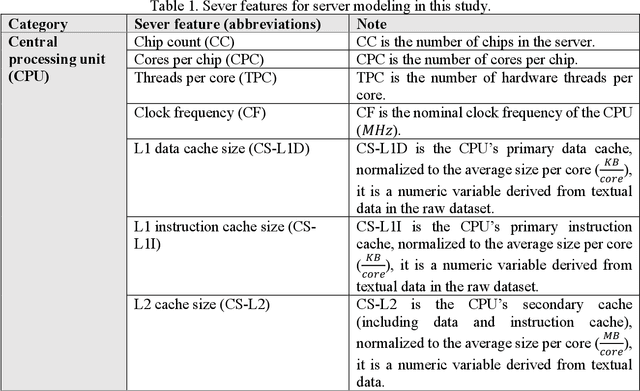
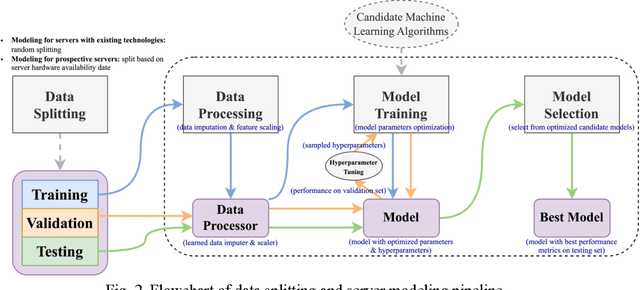

In the rapidly evolving digital era, comprehending the intricate dynamics influencing server power consumption, efficiency, and performance is crucial for sustainable data center operations. However, existing models lack the ability to provide a detailed and reliable understanding of these intricate relationships. This study employs a machine learning-based approach, using the SPECPower_ssj2008 database, to facilitate user-friendly and generalizable server modeling. The resulting models demonstrate high accuracy, with errors falling within approximately 10% on the testing dataset, showcasing their practical utility and generalizability. Through meticulous analysis, predictive features related to hardware availability date, server workload level, and specifications are identified, providing insights into optimizing energy conservation, efficiency, and performance in server deployment and operation. By systematically measuring biases and uncertainties, the study underscores the need for caution when employing historical data for prospective server modeling, considering the dynamic nature of technology landscapes. Collectively, this work offers valuable insights into the sustainable deployment and operation of servers in data centers, paving the way for enhanced resource use efficiency and more environmentally conscious practices.
S2C: Learning Noise-Resistant Differences for Unsupervised Change Detection in Multimodal Remote Sensing Images
Feb 18, 2025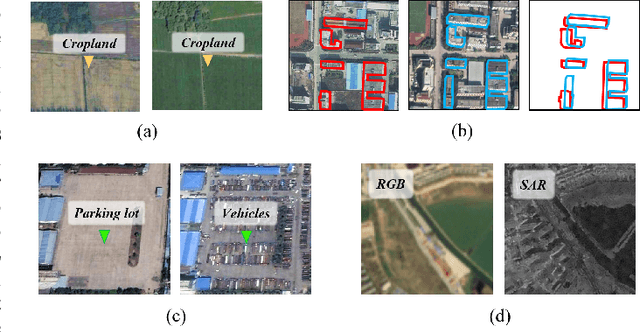
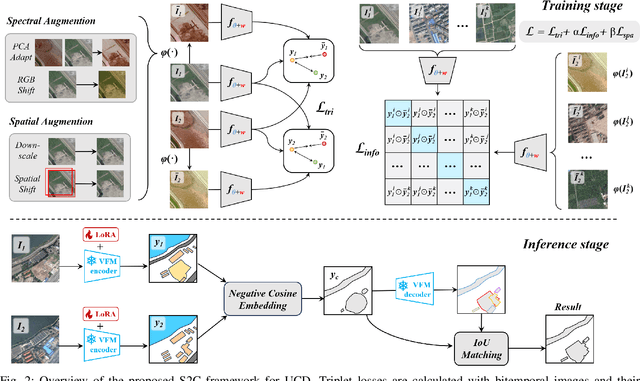

Unsupervised Change Detection (UCD) in multimodal Remote Sensing (RS) images remains a difficult challenge due to the inherent spatio-temporal complexity within data, and the heterogeneity arising from different imaging sensors. Inspired by recent advancements in Visual Foundation Models (VFMs) and Contrastive Learning (CL) methodologies, this research aims to develop CL methodologies to translate implicit knowledge in VFM into change representations, thus eliminating the need for explicit supervision. To this end, we introduce a Semantic-to-Change (S2C) learning framework for UCD in both homogeneous and multimodal RS images. Differently from existing CL methodologies that typically focus on learning multi-temporal similarities, we introduce a novel triplet learning strategy that explicitly models temporal differences, which are crucial to the CD task. Furthermore, random spatial and spectral perturbations are introduced during the training to enhance robustness to temporal noise. In addition, a grid sparsity regularization is defined to suppress insignificant changes, and an IoU-matching algorithm is developed to refine the CD results. Experiments on four benchmark CD datasets demonstrate that the proposed S2C learning framework achieves significant improvements in accuracy, surpassing current state-of-the-art by over 31\%, 9\%, 23\%, and 15\%, respectively. It also demonstrates robustness and sample efficiency, suitable for training and adaptation of various Visual Foundation Models (VFMs) or backbone neural networks. The relevant code will be available at: github.com/DingLei14/S2C.
Improving embedding with contrastive fine-tuning on small datasets with expert-augmented scores
Aug 19, 2024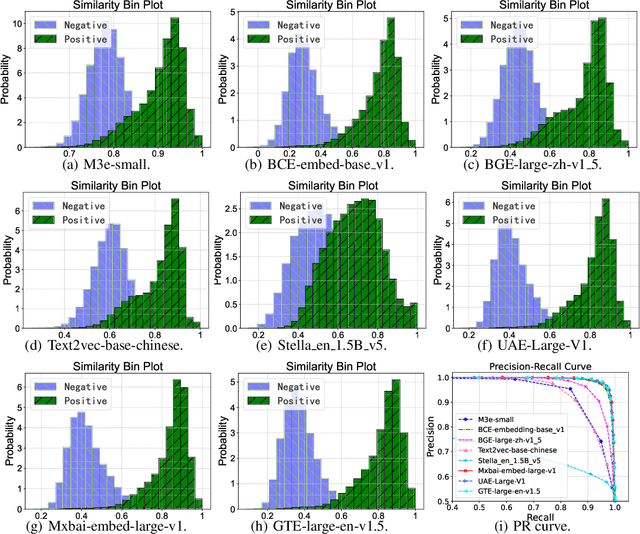
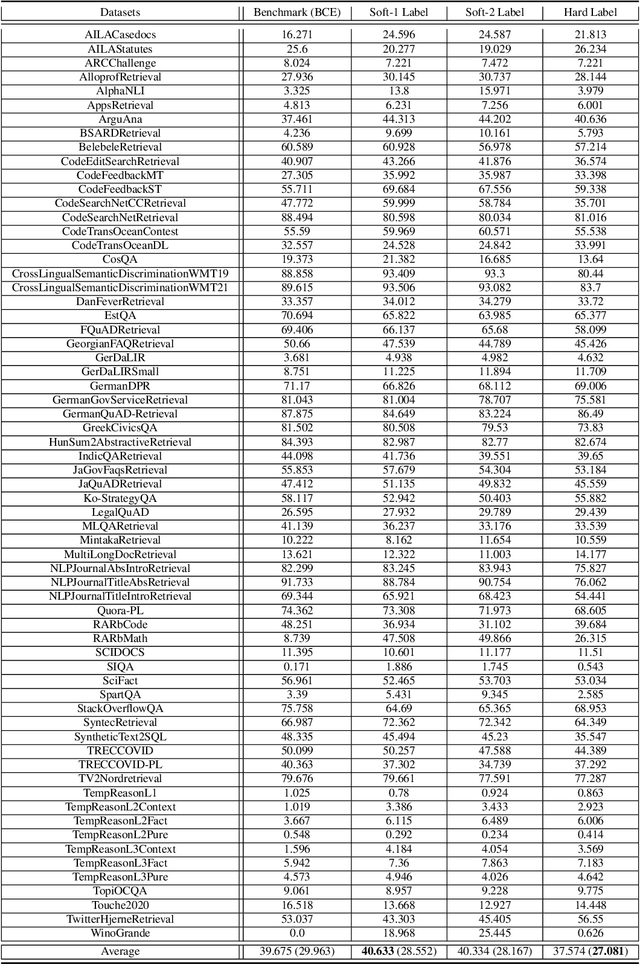
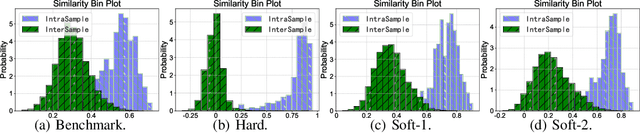

This paper presents an approach to improve text embedding models through contrastive fine-tuning on small datasets augmented with expert scores. It focuses on enhancing semantic textual similarity tasks and addressing text retrieval problems. The proposed method uses soft labels derived from expert-augmented scores to fine-tune embedding models, preserving their versatility and ensuring retrieval capability is improved. The paper evaluates the method using a Q\&A dataset from an online shopping website and eight expert models. Results show improved performance over a benchmark model across multiple metrics on various retrieval tasks from the massive text embedding benchmark (MTEB). The method is cost-effective and practical for real-world applications, especially when labeled data is scarce.
Low-Rank Approximation, Adaptation, and Other Tales
Aug 12, 2024Low-rank approximation is a fundamental technique in modern data analysis, widely utilized across various fields such as signal processing, machine learning, and natural language processing. Despite its ubiquity, the mechanics of low-rank approximation and its application in adaptation can sometimes be obscure, leaving practitioners and researchers with questions about its true capabilities and limitations. This paper seeks to clarify low-rank approximation and adaptation by offering a comprehensive guide that reveals their inner workings and explains their utility in a clear and accessible way. Our focus here is to develop a solid intuition for how low-rank approximation and adaptation operate, and why they are so effective. We begin with basic concepts and gradually build up to the mathematical underpinnings, ensuring that readers of all backgrounds can gain a deeper understanding of low-rank approximation and adaptation. We strive to strike a balance between informal explanations and rigorous mathematics, ensuring that both newcomers and experienced experts can benefit from this survey. Additionally, we introduce new low-rank decomposition and adaptation algorithms that have not yet been explored in the field, hoping that future researchers will investigate their potential applicability.
Distributed Memory Approximate Message Passing
Jul 25, 2024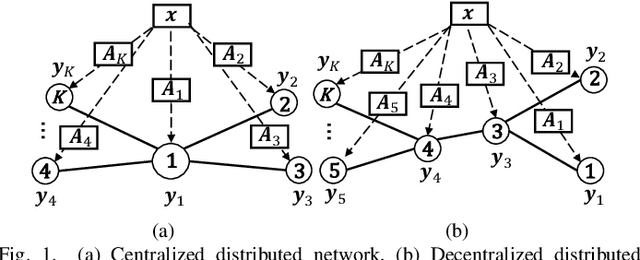
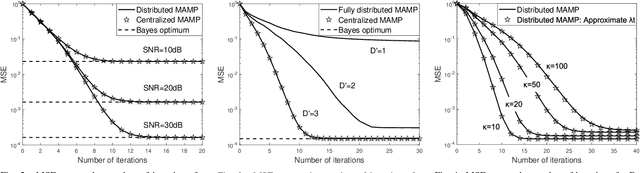

Approximate message passing (AMP) algorithms are iterative methods for signal recovery in noisy linear systems. In some scenarios, AMP algorithms need to operate within a distributed network. To address this challenge, the distributed extensions of AMP (D-AMP, FD-AMP) and orthogonal/vector AMP (D-OAMP/D-VAMP) were proposed, but they still inherit the limitations of centralized algorithms. In this letter, we propose distributed memory AMP (D-MAMP) to overcome the IID matrix limitation of D-AMP/FD-AMP, as well as the high complexity and heavy communication cost of D-OAMP/D-VAMP. We introduce a matrix-by-vector variant of MAMP tailored for distributed computing. Leveraging this variant, D-MAMP enables each node to execute computations utilizing locally available observation vectors and transform matrices. Meanwhile, global summations of locally updated results are conducted through message interaction among nodes. For acyclic graphs, D-MAMP converges to the same mean square error performance as the centralized MAMP.
DMSA: Dynamic Multi-scale Unsupervised Semantic Segmentation Based on Adaptive Affinity
Mar 01, 2023



The proposed method in this paper proposes an end-to-end unsupervised semantic segmentation architecture DMSA based on four loss functions. The framework uses Atrous Spatial Pyramid Pooling (ASPP) module to enhance feature extraction. At the same time, a dynamic dilation strategy is designed to better capture multi-scale context information. Secondly, a Pixel-Adaptive Refinement (PAR) module is introduced, which can adaptively refine the initial pseudo labels after feature fusion to obtain high quality pseudo labels. Experiments show that the proposed DSMA framework is superior to the existing methods on the saliency dataset. On the COCO 80 dataset, the MIoU is improved by 2.0, and the accuracy is improved by 5.39. On the Pascal VOC 2012 Augmented dataset, the MIoU is improved by 4.9, and the accuracy is improved by 3.4. In addition, the convergence speed of the model is also greatly improved after the introduction of the PAR module.
Bayesian Matrix Decomposition and Applications
Feb 18, 2023The sole aim of this book is to give a self-contained introduction to concepts and mathematical tools in Bayesian matrix decomposition in order to seamlessly introduce matrix decomposition techniques and their applications in subsequent sections. However, we clearly realize our inability to cover all the useful and interesting results concerning Bayesian matrix decomposition and given the paucity of scope to present this discussion, e.g., the separated analysis of variational inference for conducting the optimization. We refer the reader to literature in the field of Bayesian analysis for a more detailed introduction to the related fields. This book is primarily a summary of purpose, significance of important Bayesian matrix decomposition methods, e.g., real-valued decomposition, nonnegative matrix factorization, Bayesian interpolative decomposition, and the origin and complexity of the methods which shed light on their applications. The mathematical prerequisite is a first course in statistics and linear algebra. Other than this modest background, the development is self-contained, with rigorous proof provided throughout.