 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Pseudo-label in Self-training Unsupervised Domain Adaptation with Energy-based Model
Aug 26, 2022Deep learning is usually data starved, and the unsupervised domain adaptation (UDA) is developed to introduce the knowledge in the labeled source domain to the unlabeled target domain. Recently, deep self-training presents a powerful means for UDA, involving an iterative process of predicting the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, thus easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with an energy function minimization objective. It can be achieved via a simple additional regularization or an energy-based loss. This framework allows us to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. The convergence property and its connection with classification expectation minimization are investigated. We deliver extensive experiments on the most popular and large-scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Subtype-aware Unsupervised Domain Adaptation for Medical Diagnosis
Jan 11, 2021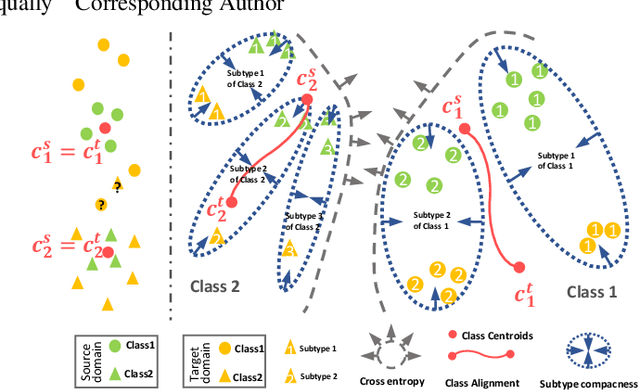
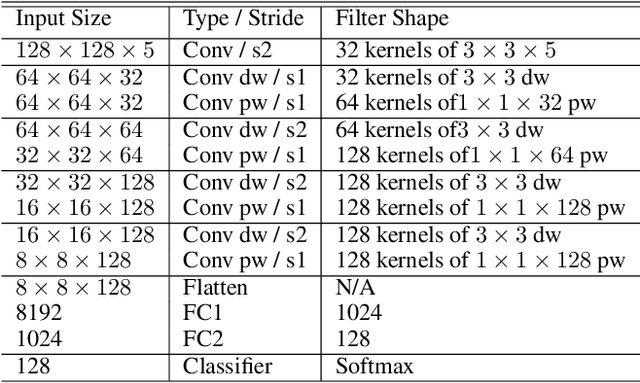
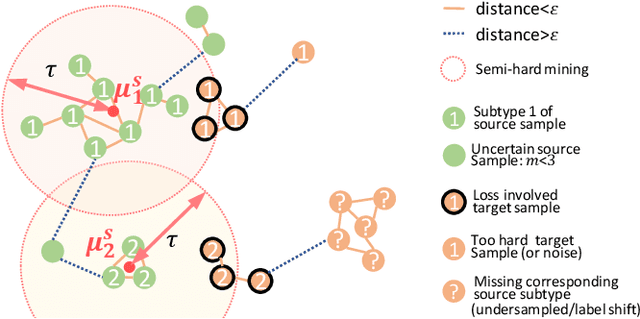
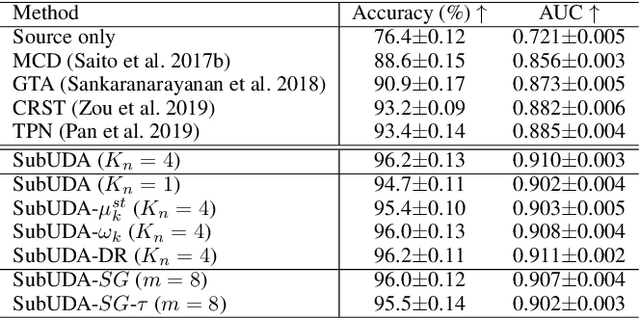
Recent advances in unsupervised domain adaptation (UDA) show that transferable prototypical learning presents a powerful means for class conditional alignment, which encourages the closeness of cross-domain class centroids. However, the cross-domain inner-class compactness and the underlying fine-grained subtype structure remained largely underexplored. In this work, we propose to adaptively carry out the fine-grained subtype-aware alignment by explicitly enforcing the class-wise separation and subtype-wise compactness with intermediate pseudo labels. Our key insight is that the unlabeled subtypes of a class can be divergent to one another with different conditional and label shifts, while inheriting the local proximity within a subtype. The cases of with or without the prior information on subtype numbers are investigated to discover the underlying subtype structure in an online fashion. The proposed subtype-aware dynamic UDA achieves promising results on medical diagnosis tasks.
Energy-constrained Self-training for Unsupervised Domain Adaptation
Jan 01, 2021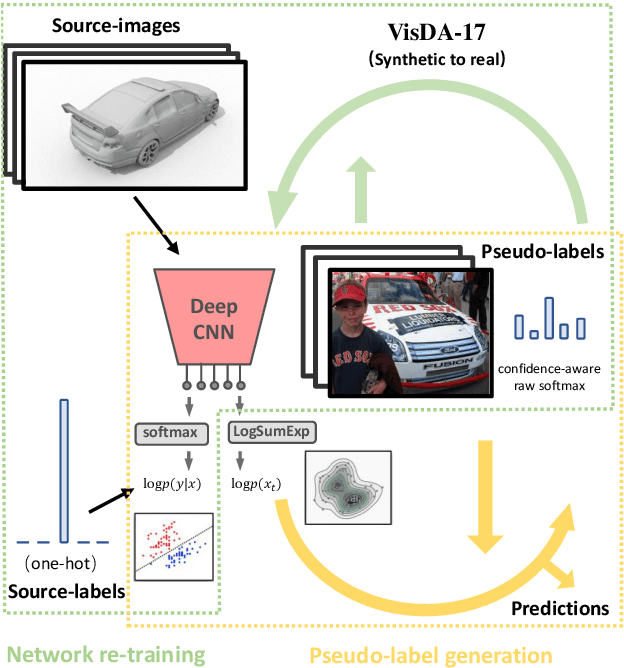

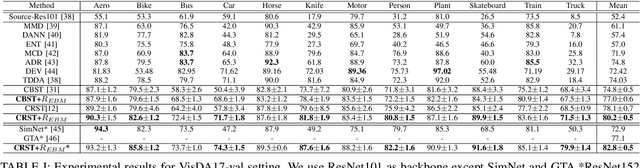
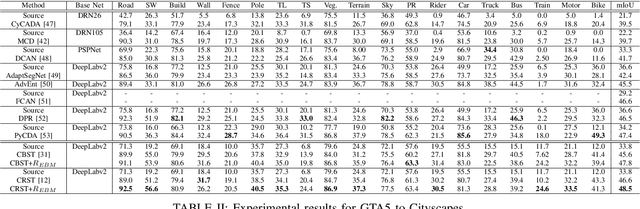
Unsupervised domain adaptation (UDA) aims to transfer the knowledge on a labeled source domain distribution to perform well on an unlabeled target domain. Recently, the deep self-training involves an iterative process of predicting on the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, and easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with the energy function minimization objective. It can be applied as a simple additional regularization. In this framework, it is possible to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. We deliver extensive experiments on the most popular and large scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Reinforced Wasserstein Training for Severity-Aware Semantic Segmentation in Autonomous Driving
Aug 11, 2020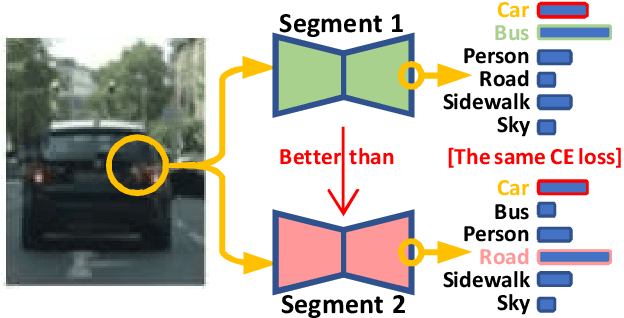
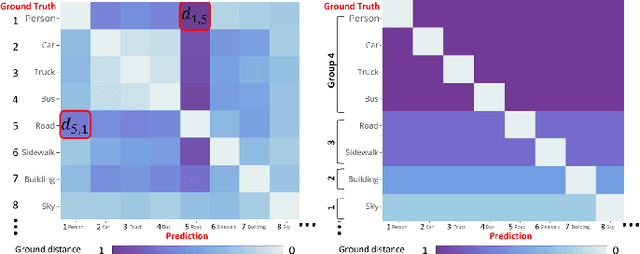
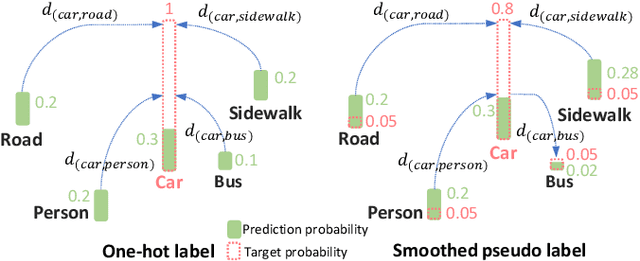
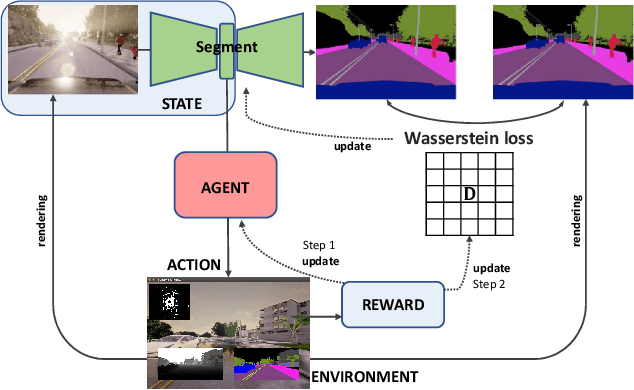
Semantic segmentation is important for many real-world systems, e.g., autonomous vehicles, which predict the class of each pixel. Recently, deep networks achieved significant progress w.r.t. the mean Intersection-over Union (mIoU) with the cross-entropy loss. However, the cross-entropy loss can essentially ignore the difference of severity for an autonomous car with different wrong prediction mistakes. For example, predicting the car to the road is much more servery than recognize it as the bus. Targeting for this difficulty, we develop a Wasserstein training framework to explore the inter-class correlation by defining its ground metric as misclassification severity. The ground metric of Wasserstein distance can be pre-defined following the experience on a specific task. From the optimization perspective, we further propose to set the ground metric as an increasing function of the pre-defined ground metric. Furthermore, an adaptively learning scheme of the ground matrix is proposed to utilize the high-fidelity CARLA simulator. Specifically, we follow a reinforcement alternative learning scheme. The experiments on both CamVid and Cityscapes datasets evidenced the effectiveness of our Wasserstein loss. The SegNet, ENet, FCN and Deeplab networks can be adapted following a plug-in manner. We achieve significant improvements on the predefined important classes, and much longer continuous playtime in our simulator.