 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Pseudo-label in Self-training Unsupervised Domain Adaptation with Energy-based Model
Aug 26, 2022Deep learning is usually data starved, and the unsupervised domain adaptation (UDA) is developed to introduce the knowledge in the labeled source domain to the unlabeled target domain. Recently, deep self-training presents a powerful means for UDA, involving an iterative process of predicting the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, thus easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with an energy function minimization objective. It can be achieved via a simple additional regularization or an energy-based loss. This framework allows us to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. The convergence property and its connection with classification expectation minimization are investigated. We deliver extensive experiments on the most popular and large-scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Identity-aware Facial Expression Recognition in Compressed Video
Jan 07, 2021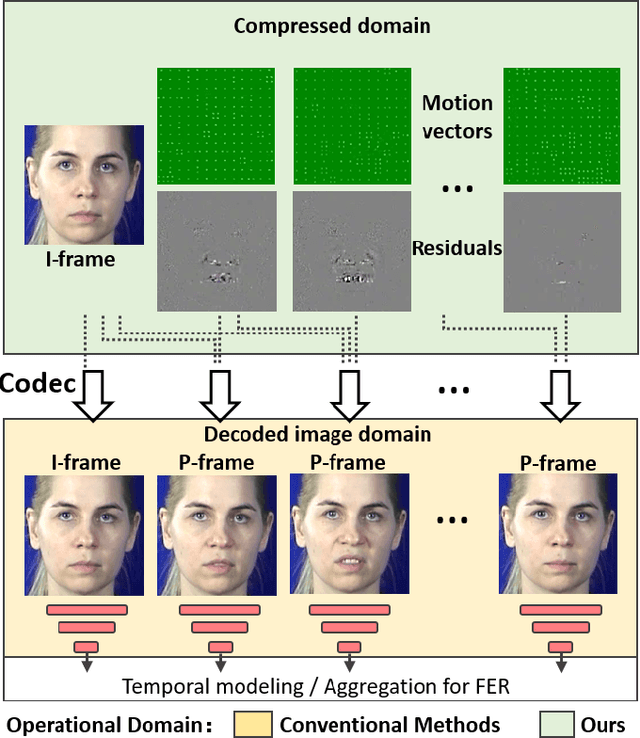
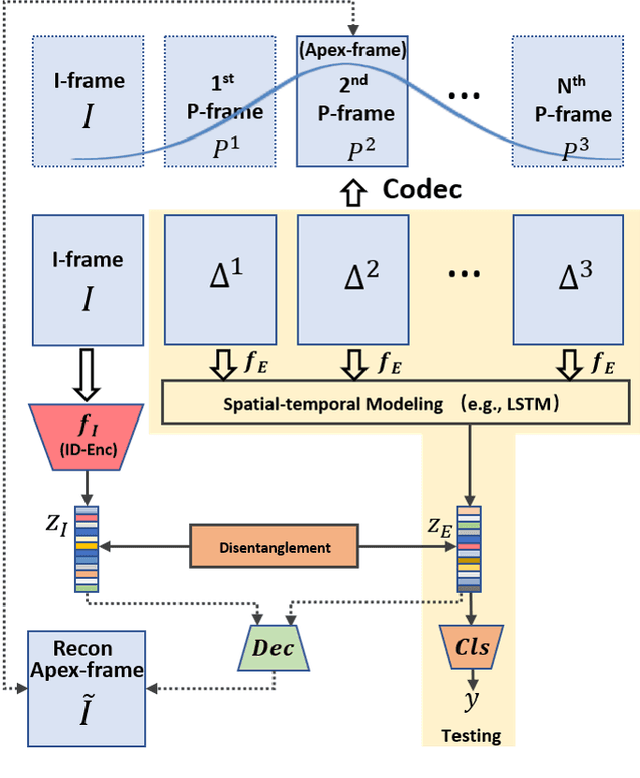
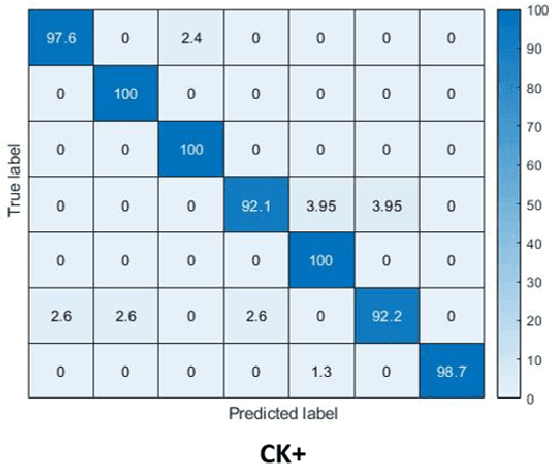

This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image based methods on the typical FER benchmarks with about 3$\times$ faster inference with compressed data.
Energy-constrained Self-training for Unsupervised Domain Adaptation
Jan 01, 2021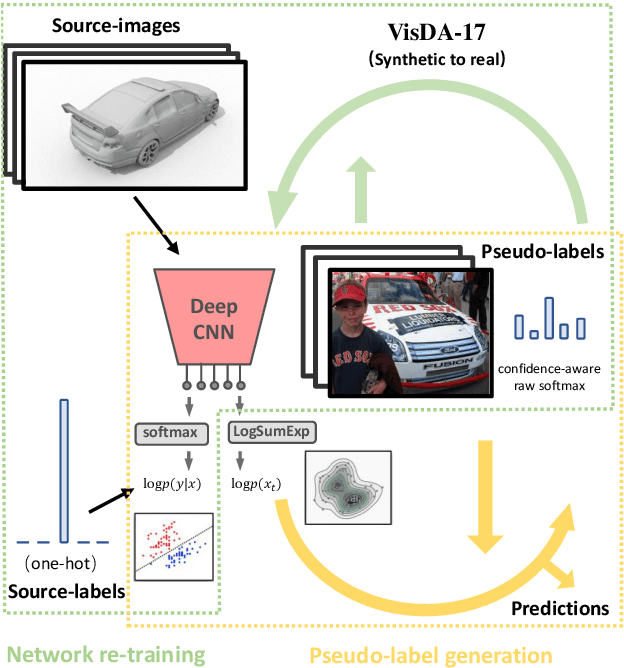

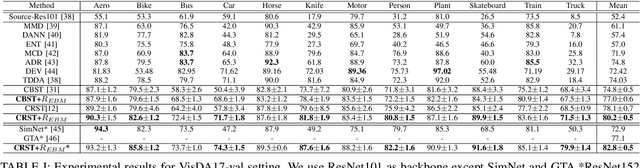
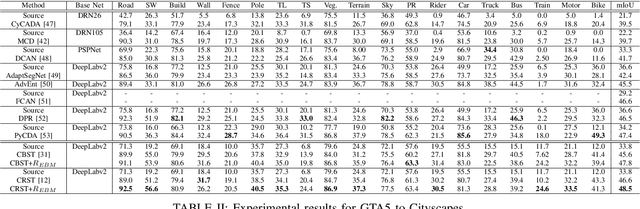
Unsupervised domain adaptation (UDA) aims to transfer the knowledge on a labeled source domain distribution to perform well on an unlabeled target domain. Recently, the deep self-training involves an iterative process of predicting on the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, and easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with the energy function minimization objective. It can be applied as a simple additional regularization. In this framework, it is possible to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. We deliver extensive experiments on the most popular and large scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Permutation-invariant Feature Restructuring for Correlation-aware Image Set-based Recognition
Aug 03, 2019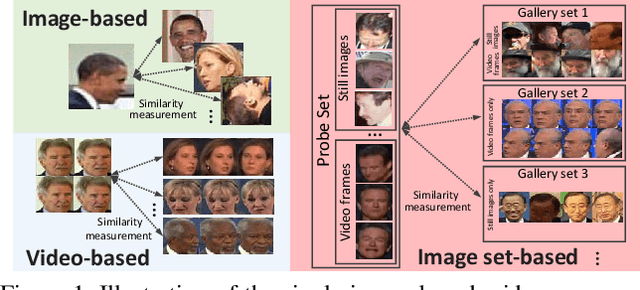
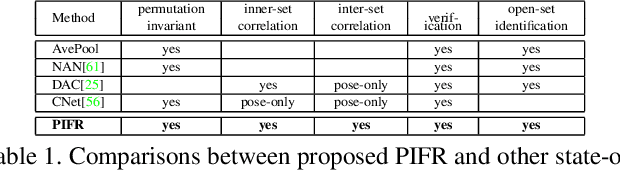


We consider the problem of comparing the similarity of image sets with variable-quantity, quality and un-ordered heterogeneous images. We use feature restructuring to exploit the correlations of both inner$\&$inter-set images. Specifically, the residual self-attention can effectively restructure the features using the other features within a set to emphasize the discriminative images and eliminate the redundancy. Then, a sparse/collaborative learning-based dependency-guided representation scheme reconstructs the probe features conditional to the gallery features in order to adaptively align the two sets. This enables our framework to be compatible with both verification and open-set identification. We show that the parametric self-attention network and non-parametric dictionary learning can be trained end-to-end by a unified alternative optimization scheme, and that the full framework is permutation-invariant. In the numerical experiments we conducted, our method achieves top performance on competitive image set/video-based face recognition and person re-identification benchmarks.