 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConservative Wasserstein Training for Pose Estimation
Nov 03, 2019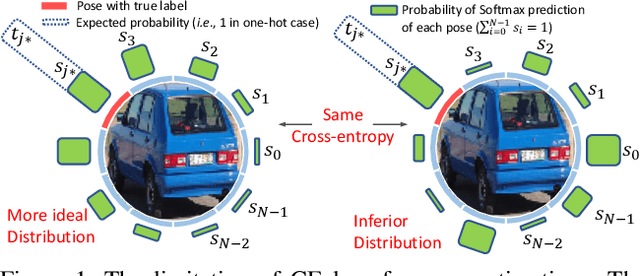
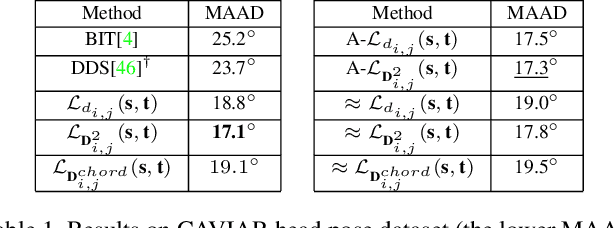
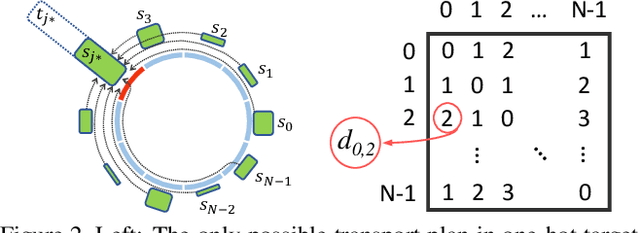
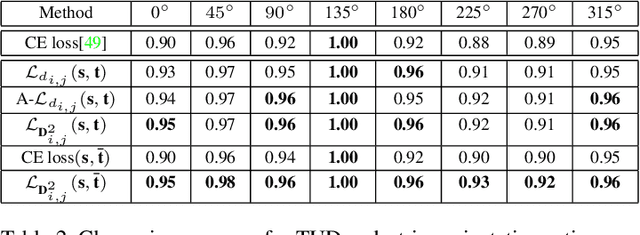
This paper targets the task with discrete and periodic class labels ($e.g.,$ pose/orientation estimation) in the context of deep learning. The commonly used cross-entropy or regression loss is not well matched to this problem as they ignore the periodic nature of the labels and the class similarity, or assume labels are continuous value. We propose to incorporate inter-class correlations in a Wasserstein training framework by pre-defining ($i.e.,$ using arc length of a circle) or adaptively learning the ground metric. We extend the ground metric as a linear, convex or concave increasing function $w.r.t.$ arc length from an optimization perspective. We also propose to construct the conservative target labels which model the inlier and outlier noises using a wrapped unimodal-uniform mixture distribution. Unlike the one-hot setting, the conservative label makes the computation of Wasserstein distance more challenging. We systematically conclude the practical closed-form solution of Wasserstein distance for pose data with either one-hot or conservative target label. We evaluate our method on head, body, vehicle and 3D object pose benchmarks with exhaustive ablation studies. The Wasserstein loss obtaining superior performance over the current methods, especially using convex mapping function for ground metric, conservative label, and closed-form solution.
Permutation-invariant Feature Restructuring for Correlation-aware Image Set-based Recognition
Aug 03, 2019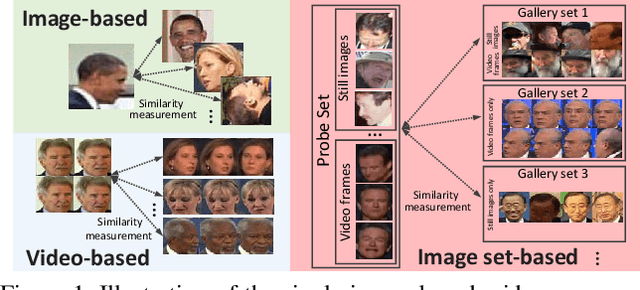
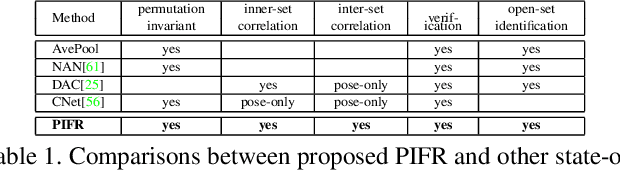


We consider the problem of comparing the similarity of image sets with variable-quantity, quality and un-ordered heterogeneous images. We use feature restructuring to exploit the correlations of both inner$\&$inter-set images. Specifically, the residual self-attention can effectively restructure the features using the other features within a set to emphasize the discriminative images and eliminate the redundancy. Then, a sparse/collaborative learning-based dependency-guided representation scheme reconstructs the probe features conditional to the gallery features in order to adaptively align the two sets. This enables our framework to be compatible with both verification and open-set identification. We show that the parametric self-attention network and non-parametric dictionary learning can be trained end-to-end by a unified alternative optimization scheme, and that the full framework is permutation-invariant. In the numerical experiments we conducted, our method achieves top performance on competitive image set/video-based face recognition and person re-identification benchmarks.