 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-MCDF: Closed-Loop Multi-Expert LLM Reasoning for Knowledge-Grounded Clinical Diagnosis
Feb 01, 2026Electronic medical records (EMRs), particularly in neurology, are inherently heterogeneous, sparse, and noisy, which poses significant challenges for large language models (LLMs) in clinical diagnosis. In such settings, single-agent systems are vulnerable to self-reinforcing errors, as their predictions lack independent validation and can drift toward spurious conclusions. Although recent multi-agent frameworks attempt to mitigate this issue through collaborative reasoning, their interactions are often shallow and loosely structured, failing to reflect the rigorous, evidence-driven processes used by clinical experts. More fundamentally, existing approaches largely ignore the rich logical dependencies among diseases, such as mutual exclusivity, pathological compatibility, and diagnostic confusion. This limitation prevents them from ruling out clinically implausible hypotheses, even when sufficient evidence is available. To overcome these, we propose RE-MCDF, a relation-enhanced multi-expert clinical diagnosis framework. RE-MCDF introduces a generation--verification--revision closed-loop architecture that integrates three complementary components: (i) a primary expert that generates candidate diagnoses and supporting evidence, (ii) a laboratory expert that dynamically prioritizes heterogeneous clinical indicators, and (iii) a multi-relation awareness and evaluation expert group that explicitly enforces inter-disease logical constraints. Guided by a medical knowledge graph (MKG), the first two experts adaptively reweight EMR evidence, while the expert group validates and corrects candidate diagnoses to ensure logical consistency. Extensive experiments on the neurology subset of CMEMR (NEEMRs) and on our curated dataset (XMEMRs) demonstrate that RE-MCDF consistently outperforms state-of-the-art baselines in complex diagnostic scenarios.
HATIR: Heat-Aware Diffusion for Turbulent Infrared Video Super-Resolution
Jan 08, 2026Infrared video has been of great interest in visual tasks under challenging environments, but often suffers from severe atmospheric turbulence and compression degradation. Existing video super-resolution (VSR) methods either neglect the inherent modality gap between infrared and visible images or fail to restore turbulence-induced distortions. Directly cascading turbulence mitigation (TM) algorithms with VSR methods leads to error propagation and accumulation due to the decoupled modeling of degradation between turbulence and resolution. We introduce HATIR, a Heat-Aware Diffusion for Turbulent InfraRed Video Super-Resolution, which injects heat-aware deformation priors into the diffusion sampling path to jointly model the inverse process of turbulent degradation and structural detail loss. Specifically, HATIR constructs a Phasor-Guided Flow Estimator, rooted in the physical principle that thermally active regions exhibit consistent phasor responses over time, enabling reliable turbulence-aware flow to guide the reverse diffusion process. To ensure the fidelity of structural recovery under nonuniform distortions, a Turbulence-Aware Decoder is proposed to selectively suppress unstable temporal cues and enhance edge-aware feature aggregation via turbulence gating and structure-aware attention. We built FLIR-IVSR, the first dataset for turbulent infrared VSR, comprising paired LR-HR sequences from a FLIR T1050sc camera (1024 X 768) spanning 640 diverse scenes with varying camera and object motion conditions. This encourages future research in infrared VSR. Project page: https://github.com/JZ0606/HATIR
BRIDGES: Bridging Graph Modality and Large Language Models within EDA Tasks
Apr 07, 2025While many EDA tasks already involve graph-based data, existing LLMs in EDA primarily either represent graphs as sequential text, or simply ignore graph-structured data that might be beneficial like dataflow graphs of RTL code. Recent studies have found that LLM performance suffers when graphs are represented as sequential text, and using additional graph information significantly boosts performance. To address these challenges, we introduce BRIDGES, a framework designed to incorporate graph modality into LLMs for EDA tasks. BRIDGES integrates an automated data generation workflow, a solution that combines graph modality with LLM, and a comprehensive evaluation suite. First, we establish an LLM-driven workflow to generate RTL and netlist-level data, converting them into dataflow and netlist graphs with function descriptions. This workflow yields a large-scale dataset comprising over 500,000 graph instances and more than 1.5 billion tokens. Second, we propose a lightweight cross-modal projector that encodes graph representations into text-compatible prompts, enabling LLMs to effectively utilize graph data without architectural modifications. Experimental results demonstrate 2x to 10x improvements across multiple tasks compared to text-only baselines, including accuracy in design retrieval, type prediction and perplexity in function description, with negligible computational overhead (<1% model weights increase and <30% additional runtime overhead). Even without additional LLM finetuning, our results outperform text-only by a large margin. We plan to release BRIDGES, including the dataset, models, and training flow.
AxisPose: Model-Free Matching-Free Single-Shot 6D Object Pose Estimation via Axis Generation
Mar 09, 2025



Object pose estimation, which plays a vital role in robotics, augmented reality, and autonomous driving, has been of great interest in computer vision. Existing studies either require multi-stage pose regression or rely on 2D-3D feature matching. Though these approaches have shown promising results, they rely heavily on appearance information, requiring complex input (i.e., multi-view reference input, depth, or CAD models) and intricate pipeline (i.e., feature extraction-SfM-2D to 3D matching-PnP). We propose AxisPose, a model-free, matching-free, single-shot solution for robust 6D pose estimation, which fundamentally diverges from the existing paradigm. Unlike existing methods that rely on 2D-3D or 2D-2D matching using 3D techniques, such as SfM and PnP, AxisPose directly infers a robust 6D pose from a single view by leveraging a diffusion model to learn the latent axis distribution of objects without reference views. Specifically, AxisPose constructs an Axis Generation Module (AGM) to capture the latent geometric distribution of object axes through a diffusion model. The diffusion process is guided by injecting the gradient of geometric consistency loss into the noise estimation to maintain the geometric consistency of the generated tri-axis. With the generated tri-axis projection, AxisPose further adopts a Triaxial Back-projection Module (TBM) to recover the 6D pose from the object tri-axis. The proposed AxisPose achieves robust performance at the cross-instance level (i.e., one model for N instances) using only a single view as input without reference images, with great potential for generalization to unseen-object level.
DifIISR: A Diffusion Model with Gradient Guidance for Infrared Image Super-Resolution
Mar 03, 2025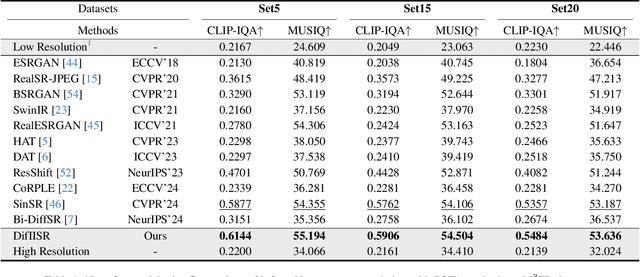
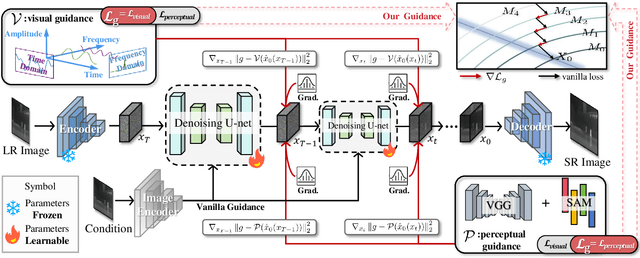


Infrared imaging is essential for autonomous driving and robotic operations as a supportive modality due to its reliable performance in challenging environments. Despite its popularity, the limitations of infrared cameras, such as low spatial resolution and complex degradations, consistently challenge imaging quality and subsequent visual tasks. Hence, infrared image super-resolution (IISR) has been developed to address this challenge. While recent developments in diffusion models have greatly advanced this field, current methods to solve it either ignore the unique modal characteristics of infrared imaging or overlook the machine perception requirements. To bridge these gaps, we propose DifIISR, an infrared image super-resolution diffusion model optimized for visual quality and perceptual performance. Our approach achieves task-based guidance for diffusion by injecting gradients derived from visual and perceptual priors into the noise during the reverse process. Specifically, we introduce an infrared thermal spectrum distribution regulation to preserve visual fidelity, ensuring that the reconstructed infrared images closely align with high-resolution images by matching their frequency components. Subsequently, we incorporate various visual foundational models as the perceptual guidance for downstream visual tasks, infusing generalizable perceptual features beneficial for detection and segmentation. As a result, our approach gains superior visual results while attaining State-Of-The-Art downstream task performance. Code is available at https://github.com/zirui0625/DifIISR
Efficient Scaling of Diffusion Transformers for Text-to-Image Generation
Dec 16, 2024



We empirically study the scaling properties of various Diffusion Transformers (DiTs) for text-to-image generation by performing extensive and rigorous ablations, including training scaled DiTs ranging from 0.3B upto 8B parameters on datasets up to 600M images. We find that U-ViT, a pure self-attention based DiT model provides a simpler design and scales more effectively in comparison with cross-attention based DiT variants, which allows straightforward expansion for extra conditions and other modalities. We identify a 2.3B U-ViT model can get better performance than SDXL UNet and other DiT variants in controlled setting. On the data scaling side, we investigate how increasing dataset size and enhanced long caption improve the text-image alignment performance and the learning efficiency.
Modality Decoupling is All You Need: A Simple Solution for Unsupervised Hyperspectral Image Fusion
Dec 06, 2024Hyperspectral Image Fusion (HIF) aims to fuse low-resolution hyperspectral images (LR-HSIs) and high-resolution multispectral images (HR-MSIs) to reconstruct high spatial and high spectral resolution images. Current methods typically apply direct fusion from the two modalities without valid supervision, failing to fully perceive the deep modality-complementary information and hence, resulting in a superficial understanding of inter-modality connections. To bridge this gap, we propose a simple and effective solution for unsupervised HIF with an assumption that modality decoupling is essential for HIF. We introduce the modality clustering loss that ensures clear guidance of the modality, decoupling towards modality-shared features while steering clear of modality-complementary ones. Also, we propose an end-to-end Modality-Decoupled Spatial-Spectral Fusion (MossFuse) framework that decouples shared and complementary information across modalities and aggregates a concise representation of the LR-HSI and HR-MSI to reduce the modality redundancy. Systematic experiments over multiple datasets demonstrate that our simple and effective approach consistently outperforms the existing HIF methods while requiring considerably fewer parameters with reduced inference time.
Contourlet Refinement Gate Framework for Thermal Spectrum Distribution Regularized Infrared Image Super-Resolution
Nov 19, 2024



Image super-resolution (SR) is a classical yet still active low-level vision problem that aims to reconstruct high-resolution (HR) images from their low-resolution (LR) counterparts, serving as a key technique for image enhancement. Current approaches to address SR tasks, such as transformer-based and diffusion-based methods, are either dedicated to extracting RGB image features or assuming similar degradation patterns, neglecting the inherent modal disparities between infrared and visible images. When directly applied to infrared image SR tasks, these methods inevitably distort the infrared spectral distribution, compromising the machine perception in downstream tasks. In this work, we emphasize the infrared spectral distribution fidelity and propose a Contourlet refinement gate framework to restore infrared modal-specific features while preserving spectral distribution fidelity. Our approach captures high-pass subbands from multi-scale and multi-directional infrared spectral decomposition to recover infrared-degraded information through a gate architecture. The proposed Spectral Fidelity Loss regularizes the spectral frequency distribution during reconstruction, which ensures the preservation of both high- and low-frequency components and maintains the fidelity of infrared-specific features. We propose a two-stage prompt-learning optimization to guide the model in learning infrared HR characteristics from LR degradation. Extensive experiments demonstrate that our approach outperforms existing image SR models in both visual and perceptual tasks while notably enhancing machine perception in downstream tasks. Our code is available at https://github.com/hey-it-s-me/CoRPLE.
Enhancing robustness of data-driven SHM models: adversarial training with circle loss
Jun 20, 2024



Structural health monitoring (SHM) is critical to safeguarding the safety and reliability of aerospace, civil, and mechanical infrastructure. Machine learning-based data-driven approaches have gained popularity in SHM due to advancements in sensors and computational power. However, machine learning models used in SHM are vulnerable to adversarial examples -- even small changes in input can lead to different model outputs. This paper aims to address this problem by discussing adversarial defenses in SHM. In this paper, we propose an adversarial training method for defense, which uses circle loss to optimize the distance between features in training to keep examples away from the decision boundary. Through this simple yet effective constraint, our method demonstrates substantial improvements in model robustness, surpassing existing defense mechanisms.
Diffusion Soup: Model Merging for Text-to-Image Diffusion Models
Jun 12, 2024



We present Diffusion Soup, a compartmentalization method for Text-to-Image Generation that averages the weights of diffusion models trained on sharded data. By construction, our approach enables training-free continual learning and unlearning with no additional memory or inference costs, since models corresponding to data shards can be added or removed by re-averaging. We show that Diffusion Soup samples from a point in weight space that approximates the geometric mean of the distributions of constituent datasets, which offers anti-memorization guarantees and enables zero-shot style mixing. Empirically, Diffusion Soup outperforms a paragon model trained on the union of all data shards and achieves a 30% improvement in Image Reward (.34 $\to$ .44) on domain sharded data, and a 59% improvement in IR (.37 $\to$ .59) on aesthetic data. In both cases, souping also prevails in TIFA score (respectively, 85.5 $\to$ 86.5 and 85.6 $\to$ 86.8). We demonstrate robust unlearning -- removing any individual domain shard only lowers performance by 1% in IR (.45 $\to$ .44) -- and validate our theoretical insights on anti-memorization using real data. Finally, we showcase Diffusion Soup's ability to blend the distinct styles of models finetuned on different shards, resulting in the zero-shot generation of hybrid styles.