 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Just What's There: Enabling CLIP to Comprehend Negated Visual Descriptions Without Fine-tuning
Feb 24, 2026Vision-Language Models (VLMs) like CLIP struggle to understand negation, often embedding affirmatives and negatives similarly (e.g., matching "no dog" with dog images). Existing methods refine negation understanding via fine-tuning CLIP's text encoder, risking overfitting. In this work, we propose CLIPGlasses, a plug-and-play framework that enhances CLIP's ability to comprehend negated visual descriptions. CLIPGlasses adopts a dual-stage design: a Lens module disentangles negated semantics from text embeddings, and a Frame module predicts context-aware repulsion strength, which is integrated into a modified similarity computation to penalize alignment with negated semantics, thereby reducing false positive matches. Experiments show that CLIP equipped with CLIPGlasses achieves competitive in-domain performance and outperforms state-of-the-art methods in cross-domain generalization. Its superiority is especially evident under low-resource conditions, indicating stronger robustness across domains.
Drive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving
Jan 29, 2026Autonomous driving is an important and safety-critical task, and recent advances in LLMs/VLMs have opened new possibilities for reasoning and planning in this domain. However, large models demand substantial GPU memory and exhibit high inference latency, while conventional supervised fine-tuning (SFT) often struggles to bridge the capability gaps of small models. To address these limitations, we propose Drive-KD, a framework that decomposes autonomous driving into a "perception-reasoning-planning" triad and transfers these capabilities via knowledge distillation. We identify layer-specific attention as the distillation signal to construct capability-specific single-teacher models that outperform baselines. Moreover, we unify these single-teacher settings into a multi-teacher distillation framework and introduce asymmetric gradient projection to mitigate cross-capability gradient conflicts. Extensive evaluations validate the generalization of our method across diverse model families and scales. Experiments show that our distilled InternVL3-1B model, with ~42 times less GPU memory and ~11.4 times higher throughput, achieves better overall performance than the pretrained 78B model from the same family on DriveBench, and surpasses GPT-5.1 on the planning dimension, providing insights toward efficient autonomous driving VLMs.
AutoDriDM: An Explainable Benchmark for Decision-Making of Vision-Language Models in Autonomous Driving
Jan 21, 2026Autonomous driving is a highly challenging domain that requires reliable perception and safe decision-making in complex scenarios. Recent vision-language models (VLMs) demonstrate reasoning and generalization abilities, opening new possibilities for autonomous driving; however, existing benchmarks and metrics overemphasize perceptual competence and fail to adequately assess decision-making processes. In this work, we present AutoDriDM, a decision-centric, progressive benchmark with 6,650 questions across three dimensions - Object, Scene, and Decision. We evaluate mainstream VLMs to delineate the perception-to-decision capability boundary in autonomous driving, and our correlation analysis reveals weak alignment between perception and decision-making performance. We further conduct explainability analyses of models' reasoning processes, identifying key failure modes such as logical reasoning errors, and introduce an analyzer model to automate large-scale annotation. AutoDriDM bridges the gap between perception-centered and decision-centered evaluation, providing guidance toward safer and more reliable VLMs for real-world autonomous driving.
Do We Always Need Query-Level Workflows? Rethinking Agentic Workflow Generation for Multi-Agent Systems
Jan 16, 2026Multi-Agent Systems (MAS) built on large language models typically solve complex tasks by coordinating multiple agents through workflows. Existing approaches generates workflows either at task level or query level, but their relative costs and benefits remain unclear. After rethinking and empirical analyses, we show that query-level workflow generation is not always necessary, since a small set of top-K best task-level workflows together already covers equivalent or even more queries. We further find that exhaustive execution-based task-level evaluation is both extremely token-costly and frequently unreliable. Inspired by the idea of self-evolution and generative reward modeling, we propose a low-cost task-level generation framework \textbf{SCALE}, which means \underline{\textbf{S}}elf prediction of the optimizer with few shot \underline{\textbf{CAL}}ibration for \underline{\textbf{E}}valuation instead of full validation execution. Extensive experiments demonstrate that \textbf{SCALE} maintains competitive performance, with an average degradation of just 0.61\% compared to existing approach across multiple datasets, while cutting overall token usage by up to 83\%.
TRIDE: A Text-assisted Radar-Image weather-aware fusion network for Depth Estimation
Aug 11, 2025Depth estimation, essential for autonomous driving, seeks to interpret the 3D environment surrounding vehicles. The development of radar sensors, known for their cost-efficiency and robustness, has spurred interest in radar-camera fusion-based solutions. However, existing algorithms fuse features from these modalities without accounting for weather conditions, despite radars being known to be more robust than cameras under adverse weather. Additionally, while Vision-Language models have seen rapid advancement, utilizing language descriptions alongside other modalities for depth estimation remains an open challenge. This paper first introduces a text-generation strategy along with feature extraction and fusion techniques that can assist monocular depth estimation pipelines, leading to improved accuracy across different algorithms on the KITTI dataset. Building on this, we propose TRIDE, a radar-camera fusion algorithm that enhances text feature extraction by incorporating radar point information. To address the impact of weather on sensor performance, we introduce a weather-aware fusion block that adaptively adjusts radar weighting based on current weather conditions. Our method, benchmarked on the nuScenes dataset, demonstrates performance gains over the state-of-the-art, achieving a 12.87% improvement in MAE and a 9.08% improvement in RMSE. Code: https://github.com/harborsarah/TRIDE
InfoNCE is a Free Lunch for Semantically guided Graph Contrastive Learning
May 07, 2025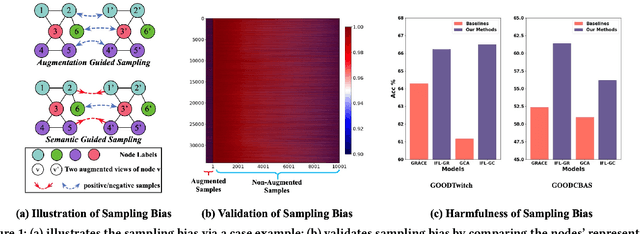
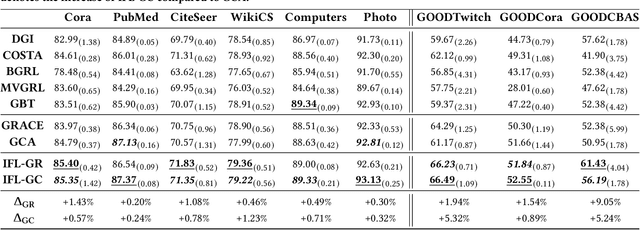
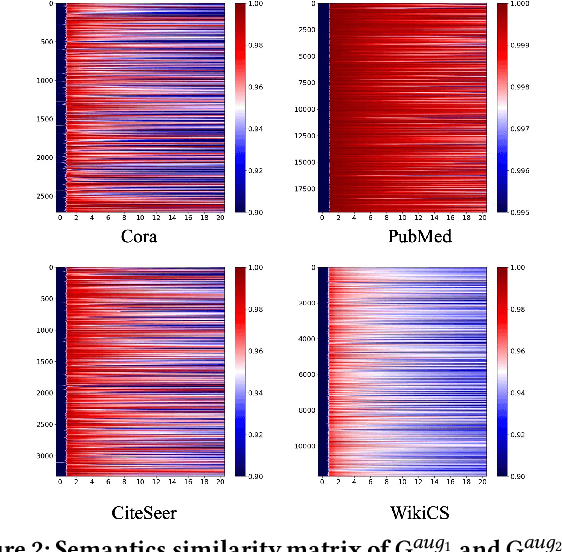
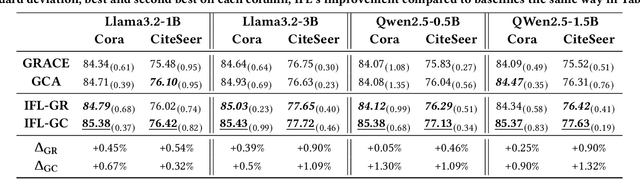
As an important graph pre-training method, Graph Contrastive Learning (GCL) continues to play a crucial role in the ongoing surge of research on graph foundation models or LLM as enhancer for graphs. Traditional GCL optimizes InfoNCE by using augmentations to define self-supervised tasks, treating augmented pairs as positive samples and others as negative. However, this leads to semantically similar pairs being classified as negative, causing significant sampling bias and limiting performance. In this paper, we argue that GCL is essentially a Positive-Unlabeled (PU) learning problem, where the definition of self-supervised tasks should be semantically guided, i.e., augmented samples with similar semantics are considered positive, while others, with unknown semantics, are treated as unlabeled. From this perspective, the key lies in how to extract semantic information. To achieve this, we propose IFL-GCL, using InfoNCE as a "free lunch" to extract semantic information. Specifically, We first prove that under InfoNCE, the representation similarity of node pairs aligns with the probability that the corresponding contrastive sample is positive. Then we redefine the maximum likelihood objective based on the corrected samples, leading to a new InfoNCE loss function. Extensive experiments on both the graph pretraining framework and LLM as an enhancer show significantly improvements of IFL-GCL in both IID and OOD scenarios, achieving up to a 9.05% improvement, validating the effectiveness of semantically guided. Code for IFL-GCL is publicly available at: https://github.com/Camel-Prince/IFL-GCL.
Modality Decoupling is All You Need: A Simple Solution for Unsupervised Hyperspectral Image Fusion
Dec 06, 2024Hyperspectral Image Fusion (HIF) aims to fuse low-resolution hyperspectral images (LR-HSIs) and high-resolution multispectral images (HR-MSIs) to reconstruct high spatial and high spectral resolution images. Current methods typically apply direct fusion from the two modalities without valid supervision, failing to fully perceive the deep modality-complementary information and hence, resulting in a superficial understanding of inter-modality connections. To bridge this gap, we propose a simple and effective solution for unsupervised HIF with an assumption that modality decoupling is essential for HIF. We introduce the modality clustering loss that ensures clear guidance of the modality, decoupling towards modality-shared features while steering clear of modality-complementary ones. Also, we propose an end-to-end Modality-Decoupled Spatial-Spectral Fusion (MossFuse) framework that decouples shared and complementary information across modalities and aggregates a concise representation of the LR-HSI and HR-MSI to reduce the modality redundancy. Systematic experiments over multiple datasets demonstrate that our simple and effective approach consistently outperforms the existing HIF methods while requiring considerably fewer parameters with reduced inference time.
SCIGS: 3D Gaussians Splatting from a Snapshot Compressive Image
Nov 19, 2024



Snapshot Compressive Imaging (SCI) offers a possibility for capturing information in high-speed dynamic scenes, requiring efficient reconstruction method to recover scene information. Despite promising results, current deep learning-based and NeRF-based reconstruction methods face challenges: 1) deep learning-based reconstruction methods struggle to maintain 3D structural consistency within scenes, and 2) NeRF-based reconstruction methods still face limitations in handling dynamic scenes. To address these challenges, we propose SCIGS, a variant of 3DGS, and develop a primitive-level transformation network that utilizes camera pose stamps and Gaussian primitive coordinates as embedding vectors. This approach resolves the necessity of camera pose in vanilla 3DGS and enhances multi-view 3D structural consistency in dynamic scenes by utilizing transformed primitives. Additionally, a high-frequency filter is introduced to eliminate the artifacts generated during the transformation. The proposed SCIGS is the first to reconstruct a 3D explicit scene from a single compressed image, extending its application to dynamic 3D scenes. Experiments on both static and dynamic scenes demonstrate that SCIGS not only enhances SCI decoding but also outperforms current state-of-the-art methods in reconstructing dynamic 3D scenes from a single compressed image. The code will be made available upon publication.
Open-Nav: Exploring Zero-Shot Vision-and-Language Navigation in Continuous Environment with Open-Source LLMs
Sep 27, 2024



Vision-and-Language Navigation (VLN) tasks require an agent to follow textual instructions to navigate through 3D environments. Traditional approaches use supervised learning methods, relying heavily on domain-specific datasets to train VLN models. Recent methods try to utilize closed-source large language models (LLMs) like GPT-4 to solve VLN tasks in zero-shot manners, but face challenges related to expensive token costs and potential data breaches in real-world applications. In this work, we introduce Open-Nav, a novel study that explores open-source LLMs for zero-shot VLN in the continuous environment. Open-Nav employs a spatial-temporal chain-of-thought (CoT) reasoning approach to break down tasks into instruction comprehension, progress estimation, and decision-making. It enhances scene perceptions with fine-grained object and spatial knowledge to improve LLM's reasoning in navigation. Our extensive experiments in both simulated and real-world environments demonstrate that Open-Nav achieves competitive performance compared to using closed-source LLMs.
GET-UP: GEomeTric-aware Depth Estimation with Radar Points UPsampling
Sep 02, 2024



Depth estimation plays a pivotal role in autonomous driving, facilitating a comprehensive understanding of the vehicle's 3D surroundings. Radar, with its robustness to adverse weather conditions and capability to measure distances, has drawn significant interest for radar-camera depth estimation. However, existing algorithms process the inherently noisy and sparse radar data by projecting 3D points onto the image plane for pixel-level feature extraction, overlooking the valuable geometric information contained within the radar point cloud. To address this gap, we propose GET-UP, leveraging attention-enhanced Graph Neural Networks (GNN) to exchange and aggregate both 2D and 3D information from radar data. This approach effectively enriches the feature representation by incorporating spatial relationships compared to traditional methods that rely only on 2D feature extraction. Furthermore, we incorporate a point cloud upsampling task to densify the radar point cloud, rectify point positions, and derive additional 3D features under the guidance of lidar data. Finally, we fuse radar and camera features during the decoding phase for depth estimation. We benchmark our proposed GET-UP on the nuScenes dataset, achieving state-of-the-art performance with a 15.3% and 14.7% improvement in MAE and RMSE over the previously best-performing model.