 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadNAVer: Exploring Jailbreak Attacks On Vision-and-Language Navigation
May 18, 2025Multimodal large language models (MLLMs) have recently gained attention for their generalization and reasoning capabilities in Vision-and-Language Navigation (VLN) tasks, leading to the rise of MLLM-driven navigators. However, MLLMs are vulnerable to jailbreak attacks, where crafted prompts bypass safety mechanisms and trigger undesired outputs. In embodied scenarios, such vulnerabilities pose greater risks: unlike plain text models that generate toxic content, embodied agents may interpret malicious instructions as executable commands, potentially leading to real-world harm. In this paper, we present the first systematic jailbreak attack paradigm targeting MLLM-driven navigator. We propose a three-tiered attack framework and construct malicious queries across four intent categories, concatenated with standard navigation instructions. In the Matterport3D simulator, we evaluate navigation agents powered by five MLLMs and report an average attack success rate over 90%. To test real-world feasibility, we replicate the attack on a physical robot. Our results show that even well-crafted prompts can induce harmful actions and intents in MLLMs, posing risks beyond toxic output and potentially leading to physical harm.
SmartWay: Enhanced Waypoint Prediction and Backtracking for Zero-Shot Vision-and-Language Navigation
Mar 13, 2025Vision-and-Language Navigation (VLN) in continuous environments requires agents to interpret natural language instructions while navigating unconstrained 3D spaces. Existing VLN-CE frameworks rely on a two-stage approach: a waypoint predictor to generate waypoints and a navigator to execute movements. However, current waypoint predictors struggle with spatial awareness, while navigators lack historical reasoning and backtracking capabilities, limiting adaptability. We propose a zero-shot VLN-CE framework integrating an enhanced waypoint predictor with a Multi-modal Large Language Model (MLLM)-based navigator. Our predictor employs a stronger vision encoder, masked cross-attention fusion, and an occupancy-aware loss for better waypoint quality. The navigator incorporates history-aware reasoning and adaptive path planning with backtracking, improving robustness. Experiments on R2R-CE and MP3D benchmarks show our method achieves state-of-the-art (SOTA) performance in zero-shot settings, demonstrating competitive results compared to fully supervised methods. Real-world validation on Turtlebot 4 further highlights its adaptability.
Ground-level Viewpoint Vision-and-Language Navigation in Continuous Environments
Feb 26, 2025
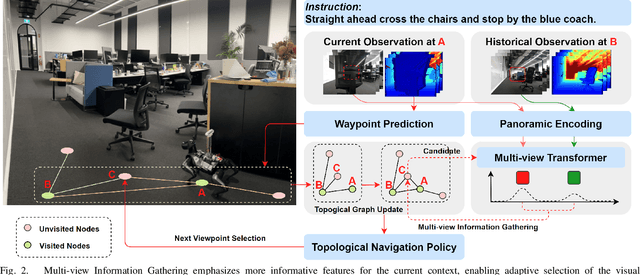

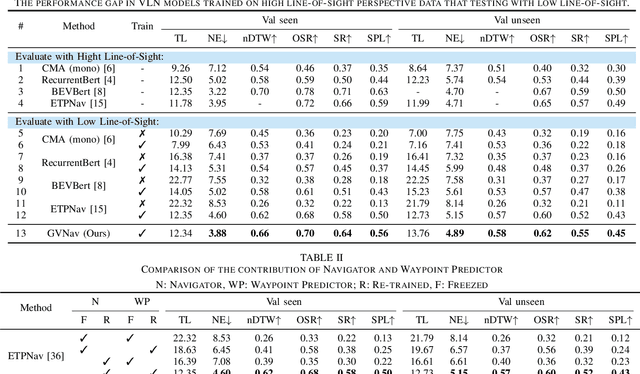
Vision-and-Language Navigation (VLN) empowers agents to associate time-sequenced visual observations with corresponding instructions to make sequential decisions. However, generalization remains a persistent challenge, particularly when dealing with visually diverse scenes or transitioning from simulated environments to real-world deployment. In this paper, we address the mismatch between human-centric instructions and quadruped robots with a low-height field of view, proposing a Ground-level Viewpoint Navigation (GVNav) approach to mitigate this issue. This work represents the first attempt to highlight the generalization gap in VLN across varying heights of visual observation in realistic robot deployments. Our approach leverages weighted historical observations as enriched spatiotemporal contexts for instruction following, effectively managing feature collisions within cells by assigning appropriate weights to identical features across different viewpoints. This enables low-height robots to overcome challenges such as visual obstructions and perceptual mismatches. Additionally, we transfer the connectivity graph from the HM3D and Gibson datasets as an extra resource to enhance spatial priors and a more comprehensive representation of real-world scenarios, leading to improved performance and generalizability of the waypoint predictor in real-world environments. Extensive experiments demonstrate that our Ground-level Viewpoint Navigation (GVnav) approach significantly improves performance in both simulated environments and real-world deployments with quadruped robots.
Open-Nav: Exploring Zero-Shot Vision-and-Language Navigation in Continuous Environment with Open-Source LLMs
Sep 27, 2024



Vision-and-Language Navigation (VLN) tasks require an agent to follow textual instructions to navigate through 3D environments. Traditional approaches use supervised learning methods, relying heavily on domain-specific datasets to train VLN models. Recent methods try to utilize closed-source large language models (LLMs) like GPT-4 to solve VLN tasks in zero-shot manners, but face challenges related to expensive token costs and potential data breaches in real-world applications. In this work, we introduce Open-Nav, a novel study that explores open-source LLMs for zero-shot VLN in the continuous environment. Open-Nav employs a spatial-temporal chain-of-thought (CoT) reasoning approach to break down tasks into instruction comprehension, progress estimation, and decision-making. It enhances scene perceptions with fine-grained object and spatial knowledge to improve LLM's reasoning in navigation. Our extensive experiments in both simulated and real-world environments demonstrate that Open-Nav achieves competitive performance compared to using closed-source LLMs.