 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Feedback-Driven Continual Adaptation for Vision-and-Language Navigation
Dec 11, 2025Vision-and-Language Navigation (VLN) requires agents to navigate complex environments by following natural-language instructions. General Scene Adaptation for VLN (GSA-VLN) shifts the focus from zero-shot generalization to continual, environment-specific adaptation, narrowing the gap between static benchmarks and real-world deployment. However, current GSA-VLN frameworks exclude user feedback, relying solely on unsupervised adaptation from repeated environmental exposure. In practice, user feedback offers natural and valuable supervision that can significantly enhance adaptation quality. We introduce a user-feedback-driven adaptation framework that extends GSA-VLN by systematically integrating human interactions into continual learning. Our approach converts user feedback-navigation instructions and corrective signals-into high-quality, environment-aligned training data, enabling efficient and realistic adaptation. A memory-bank warm-start mechanism further reuses previously acquired environmental knowledge, mitigating cold-start degradation and ensuring stable redeployment. Experiments on the GSA-R2R benchmark show that our method consistently surpasses strong baselines such as GR-DUET, improving navigation success and path efficiency. The memory-bank warm start stabilizes early navigation and reduces performance drops after updates. Results under both continual and hybrid adaptation settings confirm the robustness and generality of our framework, demonstrating sustained improvement across diverse deployment conditions.
Ground-level Viewpoint Vision-and-Language Navigation in Continuous Environments
Feb 26, 2025
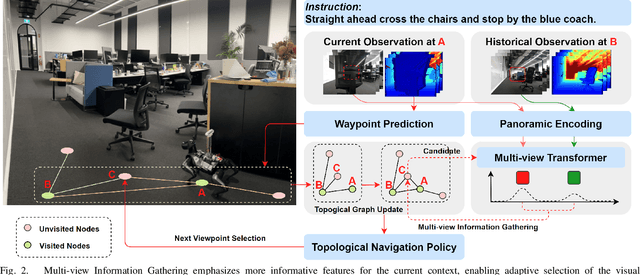

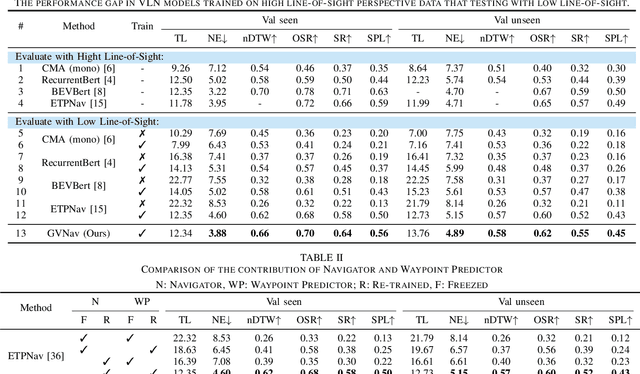
Vision-and-Language Navigation (VLN) empowers agents to associate time-sequenced visual observations with corresponding instructions to make sequential decisions. However, generalization remains a persistent challenge, particularly when dealing with visually diverse scenes or transitioning from simulated environments to real-world deployment. In this paper, we address the mismatch between human-centric instructions and quadruped robots with a low-height field of view, proposing a Ground-level Viewpoint Navigation (GVNav) approach to mitigate this issue. This work represents the first attempt to highlight the generalization gap in VLN across varying heights of visual observation in realistic robot deployments. Our approach leverages weighted historical observations as enriched spatiotemporal contexts for instruction following, effectively managing feature collisions within cells by assigning appropriate weights to identical features across different viewpoints. This enables low-height robots to overcome challenges such as visual obstructions and perceptual mismatches. Additionally, we transfer the connectivity graph from the HM3D and Gibson datasets as an extra resource to enhance spatial priors and a more comprehensive representation of real-world scenarios, leading to improved performance and generalizability of the waypoint predictor in real-world environments. Extensive experiments demonstrate that our Ground-level Viewpoint Navigation (GVnav) approach significantly improves performance in both simulated environments and real-world deployments with quadruped robots.
General Scene Adaptation for Vision-and-Language Navigation
Jan 29, 2025
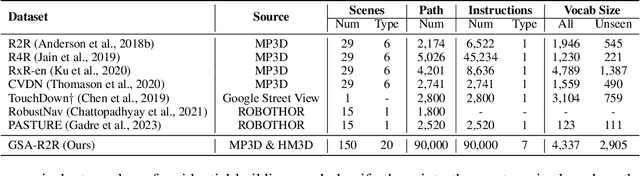

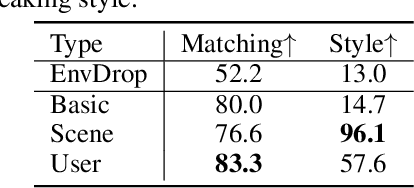
Vision-and-Language Navigation (VLN) tasks mainly evaluate agents based on one-time execution of individual instructions across multiple environments, aiming to develop agents capable of functioning in any environment in a zero-shot manner. However, real-world navigation robots often operate in persistent environments with relatively consistent physical layouts, visual observations, and language styles from instructors. Such a gap in the task setting presents an opportunity to improve VLN agents by incorporating continuous adaptation to specific environments. To better reflect these real-world conditions, we introduce GSA-VLN, a novel task requiring agents to execute navigation instructions within a specific scene and simultaneously adapt to it for improved performance over time. To evaluate the proposed task, one has to address two challenges in existing VLN datasets: the lack of OOD data, and the limited number and style diversity of instructions for each scene. Therefore, we propose a new dataset, GSA-R2R, which significantly expands the diversity and quantity of environments and instructions for the R2R dataset to evaluate agent adaptability in both ID and OOD contexts. Furthermore, we design a three-stage instruction orchestration pipeline that leverages LLMs to refine speaker-generated instructions and apply role-playing techniques to rephrase instructions into different speaking styles. This is motivated by the observation that each individual user often has consistent signatures or preferences in their instructions. We conducted extensive experiments on GSA-R2R to thoroughly evaluate our dataset and benchmark various methods. Based on our findings, we propose a novel method, GR-DUET, which incorporates memory-based navigation graphs with an environment-specific training strategy, achieving state-of-the-art results on all GSA-R2R splits.
Navigating Beyond Instructions: Vision-and-Language Navigation in Obstructed Environments
Jul 31, 2024Real-world navigation often involves dealing with unexpected obstructions such as closed doors, moved objects, and unpredictable entities. However, mainstream Vision-and-Language Navigation (VLN) tasks typically assume instructions perfectly align with the fixed and predefined navigation graphs without any obstructions. This assumption overlooks potential discrepancies in actual navigation graphs and given instructions, which can cause major failures for both indoor and outdoor agents. To address this issue, we integrate diverse obstructions into the R2R dataset by modifying both the navigation graphs and visual observations, introducing an innovative dataset and task, R2R with UNexpected Obstructions (R2R-UNO). R2R-UNO contains various types and numbers of path obstructions to generate instruction-reality mismatches for VLN research. Experiments on R2R-UNO reveal that state-of-the-art VLN methods inevitably encounter significant challenges when facing such mismatches, indicating that they rigidly follow instructions rather than navigate adaptively. Therefore, we propose a novel method called ObVLN (Obstructed VLN), which includes a curriculum training strategy and virtual graph construction to help agents effectively adapt to obstructed environments. Empirical results show that ObVLN not only maintains robust performance in unobstructed scenarios but also achieves a substantial performance advantage with unexpected obstructions.
Why Only Text: Empowering Vision-and-Language Navigation with Multi-modal Prompts
Jun 04, 2024



Current Vision-and-Language Navigation (VLN) tasks mainly employ textual instructions to guide agents. However, being inherently abstract, the same textual instruction can be associated with different visual signals, causing severe ambiguity and limiting the transfer of prior knowledge in the vision domain from the user to the agent. To fill this gap, we propose Vision-and-Language Navigation with Multi-modal Prompts (VLN-MP), a novel task augmenting traditional VLN by integrating both natural language and images in instructions. VLN-MP not only maintains backward compatibility by effectively handling text-only prompts but also consistently shows advantages with different quantities and relevance of visual prompts. Possible forms of visual prompts include both exact and similar object images, providing adaptability and versatility in diverse navigation scenarios. To evaluate VLN-MP under a unified framework, we implement a new benchmark that offers: (1) a training-free pipeline to transform textual instructions into multi-modal forms with landmark images; (2) diverse datasets with multi-modal instructions for different downstream tasks; (3) a novel module designed to process various image prompts for seamless integration with state-of-the-art VLN models. Extensive experiments on four VLN benchmarks (R2R, RxR, REVERIE, CVDN) show that incorporating visual prompts significantly boosts navigation performance. While maintaining efficiency with text-only prompts, VLN-MP enables agents to navigate in the pre-explore setting and outperform text-based models, showing its broader applicability.