 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk When It Pays: Cost-Aware Open-Ended Interaction for Instance Goal Navigation
Jun 03, 2026Instance Goal Navigation (IGN) requires an embodied agent to find a specific object instance among distractors from an under-specified natural-language description. Such ambiguity often cannot be resolved from perception and language alone, making interaction with an oracle a natural mechanism for disambiguation. Prior interactive methods allow oracle queries but treat lightweight clarification and route-level guidance alike, letting agents boost success rate through repeated high-information questions rather than by resolving the underlying ambiguity efficiently. We recast interactive IGN as a cost-sensitive uncertainty-reduction problem, where the agent should ask the question whose answer provides the largest reduction in navigation uncertainty relative to its penalty. To this end, we apply an information-gain analysis on existing navigation corpora to identify which cues reduce navigation uncertainty, yielding a compact set of question types and data-derived weights. However, existing interactive navigation benchmarks do not model the cost of different question types or evaluate how efficiently agents use interaction, making them unsuitable for studying cost-sensitive interaction. Based on this taxonomy, we construct a benchmark for diagnosing interaction behavior and efficiency, together with a Weighted Success Rate metric that penalizes each query by its derived cost. We further propose a zero-shot MLLM navigator that selectively queries at each decision step only when the expected uncertainty reduction justifies the interaction cost.
TTT-VLA: Test-Time Latent Prompt Optimization for Vision-Language-Action Models
Jun 02, 2026Vision-Language-Action (VLA) models trained on large-scale data have made remarkable progress, but they remain vulnerable to distribution shifts at deployment time. Recent VLA models suggest that prompts can serve as an efficient interface for steering policy behavior, but existing prompt-based steering typically relies on external guidance. This raises a natural question: can test-time training (TTT) for VLA be achieved by optimizing a prompt, so that the steering interface itself can be learned and adapted from interaction? We address this question with TTT-VLA, a test-time training framework based on Latent Prompt Optimization (LPO). During training, the latent prompt is learned with an additional proxy task, providing an extra learned conditioning signal for policy learning. At test time, TTT is performed by collecting interaction data from the current environment and optimizing only the latent prompt on those data using the proxy task's self-supervised signal, without modifying the policy itself. Experiments on SimplerEnv demonstrate that the proposed method consistently improves task success rates in both single- and multi-embodiment settings. Further analysis shows that the gains arise primarily from correcting a small number of critical decisions rather than globally altering policy behavior. These results suggest that LPO provides an effective and practical pathway for deployment-time improvement of foundation manipulation policies.
Knowledge Poisoning Attacks on Medical Multi-Modal Retrieval-Augmented Generation
May 11, 2026Retrieval-augmented generation (RAG) is a widely adopted paradigm for enhancing LLMs in medical applications by incorporating expert multimodal knowledge during generation. However, the underlying retrieval databases may naturally contain, or be intentionally injected with, adversarial knowledge, which can perturb model outputs and undermine system reliability. To investigate this risk, prior studies have explored knowledge poisoning attacks in medical RAG systems. Nevertheless, most of them rely on the strong assumption that adversaries possess prior knowledge of user queries, which is unrealistic in deployments and substantially limits their practical applicability. In this paper, we propose M\textsuperscript{3}Att, a knowledge-poisoning framework designed for medical multimodal RAG systems, assuming only limited distribution knowledge of the underlying database. Our core idea is to inject covert misinformation into textual data while using paired visual data as a query-agnostic trigger to promote retrieval. We first propose a unified framework that introduces imperceptible perturbations to visual inputs to manipulate retrieval probabilities. Besides, due to the prior medical knowledge in LLMs, naively poisoned medical content with explicit factual errors can be corrected during generation. Thus, we leverage the inherent ambiguity of medical diagnosis and design a covert misinformation injection strategy that degrades diagnostic accuracy while evading model self-correction. Experiments on five LLMs and datasets demonstrate that M\textsuperscript{3}Att consistently produces clinically plausible yet incorrect generations. Codes: https://github.com/ypr17/M3Att.
ReCoVR: Closing the Loop in Interactive Composed Video Retrieval
May 11, 2026Composed video retrieval (CoVR) searches for target videos using a reference video and a modification text, but existing methods are restricted to a single interaction round and cannot support the progressive nature of real-world visual search. To bridge this gap, we first formalize interactive composed video retrieval, a multi-turn extension of CoVR, where users progressively refine their search intent through natural-language feedback across turns. Adapting existing interactive retrieval methods to this setting reveals two structural weaknesses: reliance on a single retrieval channel and an open-loop retrieval design that consumes user feedback but does not diagnose whether its own retrieval trajectory is drifting or stagnating. To address these limitations, we propose ReCoVR (Reflexive Composed Video Retrieval), a dual-pathway architecture built on reflexive perception, where the system treats its retrieval history as diagnostic evidence alongside user feedback. Specifically, an Intent Pathway routes heterogeneous feedback to complementary retrieval channels, while a Reflection Pathway performs trajectory-level reflection to monitor result evolution and correct retrieval errors across turns. Experiments on multiple benchmarks show that ReCoVR consistently outperforms interactive baselines, notably achieving 74.30% R@1 after just one interactive round on the WebVid-CoVR-Test dataset.
OrthoDiffusion: A Generalizable Multi-Task Diffusion Foundation Model for Musculoskeletal MRI Interpretation
Feb 24, 2026Musculoskeletal disorders represent a significant global health burden and are a leading cause of disability worldwide. While MRI is essential for accurate diagnosis, its interpretation remains exceptionally challenging. Radiologists must identify multiple potential abnormalities within complex anatomical structures across different imaging planes, a process that requires significant expertise and is prone to variability. We developed OrthoDiffusion, a unified diffusion-based foundation model designed for multi-task musculoskeletal MRI interpretation. The framework utilizes three orientation-specific 3D diffusion models, pre-trained in a self-supervised manner on 15,948 unlabeled knee MRI scans, to learn robust anatomical features from sagittal, coronal, and axial views. These view-specific representations are integrated to support diverse clinical tasks, including anatomical segmentation and multi-label diagnosis. Our evaluation demonstrates that OrthoDiffusion achieves excellent performance in the segmentation of 11 knee structures and the detection of 8 knee abnormalities. The model exhibited remarkable robustness across different clinical centers and MRI field strengths, consistently outperforming traditional supervised models. Notably, in settings where labeled data was scarce, OrthoDiffusion maintained high diagnostic precision using only 10\% of training labels. Furthermore, the anatomical representations learned from knee imaging proved highly transferable to other joints, achieving strong diagnostic performance across 11 diseases of the ankle and shoulder. These findings suggest that diffusion-based foundation models can serve as a unified platform for multi-disease diagnosis and anatomical segmentation, potentially improving the efficiency and accuracy of musculoskeletal MRI interpretation in real-world clinical workflows.
Geometry-Aware Rotary Position Embedding for Consistent Video World Model
Feb 08, 2026Predictive world models that simulate future observations under explicit camera control are fundamental to interactive AI. Despite rapid advances, current systems lack spatial persistence: they fail to maintain stable scene structures over long trajectories, frequently hallucinating details when cameras revisit previously observed locations. We identify that this geometric drift stems from reliance on screen-space positional embeddings, which conflict with the projective geometry required for 3D consistency. We introduce \textbf{ViewRope}, a geometry-aware encoding that injects camera-ray directions directly into video transformer self-attention layers. By parameterizing attention with relative ray geometry rather than pixel locality, ViewRope provides a model-native inductive bias for retrieving 3D-consistent content across temporal gaps. We further propose \textbf{Geometry-Aware Frame-Sparse Attention}, which exploits these geometric cues to selectively attend to relevant historical frames, improving efficiency without sacrificing memory consistency. We also present \textbf{ViewBench}, a diagnostic suite measuring loop-closure fidelity and geometric drift. Our results demonstrate that ViewRope substantially improves long-term consistency while reducing computational costs.
A multimodal vision foundation model for generalizable knee pathology
Jan 26, 2026Musculoskeletal disorders represent a leading cause of global disability, creating an urgent demand for precise interpretation of medical imaging. Current artificial intelligence (AI) approaches in orthopedics predominantly rely on task-specific, supervised learning paradigms. These methods are inherently fragmented, require extensive annotated datasets, and often lack generalizability across different modalities and clinical scenarios. The development of foundation models in this field has been constrained by the scarcity of large-scale, curated, and open-source musculoskeletal datasets. To address these challenges, we introduce OrthoFoundation, a multimodal vision foundation model optimized for musculoskeletal pathology. We constructed a pre-training dataset of 1.2 million unlabeled knee X-ray and MRI images from internal and public databases. Utilizing a Dinov3 backbone, the model was trained via self-supervised contrastive learning to capture robust radiological representations. OrthoFoundation achieves state-of-the-art (SOTA) performance across 14 downstream tasks. It attained superior accuracy in X-ray osteoarthritis diagnosis and ranked first in MRI structural injury detection. The model demonstrated remarkable label efficiency, matching supervised baselines using only 50% of labeled data. Furthermore, despite being pre-trained on knee images, OrthoFoundation exhibited exceptional cross-anatomy generalization to the hip, shoulder, and ankle. OrthoFoundation represents a significant advancement toward general-purpose AI for musculoskeletal imaging. By learning fundamental, joint-agnostic radiological semantics from large-scale multimodal data, it overcomes the limitations of conventional models, which provides a robust framework for reducing annotation burdens and enhancing diagnostic accuracy in clinical practice.
The Illusion of Clinical Reasoning: A Benchmark Reveals the Pervasive Gap in Vision-Language Models for Clinical Competency
Dec 25, 2025Background: The rapid integration of foundation models into clinical practice and public health necessitates a rigorous evaluation of their true clinical reasoning capabilities beyond narrow examination success. Current benchmarks, typically based on medical licensing exams or curated vignettes, fail to capture the integrated, multimodal reasoning essential for real-world patient care. Methods: We developed the Bones and Joints (B&J) Benchmark, a comprehensive evaluation framework comprising 1,245 questions derived from real-world patient cases in orthopedics and sports medicine. This benchmark assesses models across 7 tasks that mirror the clinical reasoning pathway, including knowledge recall, text and image interpretation, diagnosis generation, treatment planning, and rationale provision. We evaluated eleven vision-language models (VLMs) and six large language models (LLMs), comparing their performance against expert-derived ground truth. Results: Our results demonstrate a pronounced performance gap between task types. While state-of-the-art models achieved high accuracy, exceeding 90%, on structured multiple-choice questions, their performance markedly declined on open-ended tasks requiring multimodal integration, with accuracy scarcely reaching 60%. VLMs demonstrated substantial limitations in interpreting medical images and frequently exhibited severe text-driven hallucinations, often ignoring contradictory visual evidence. Notably, models specifically fine-tuned for medical applications showed no consistent advantage over general-purpose counterparts. Conclusions: Current artificial intelligence models are not yet clinically competent for complex, multimodal reasoning. Their safe deployment should currently be limited to supportive, text-based roles. Future advancement in core clinical tasks awaits fundamental breakthroughs in multimodal integration and visual understanding.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025
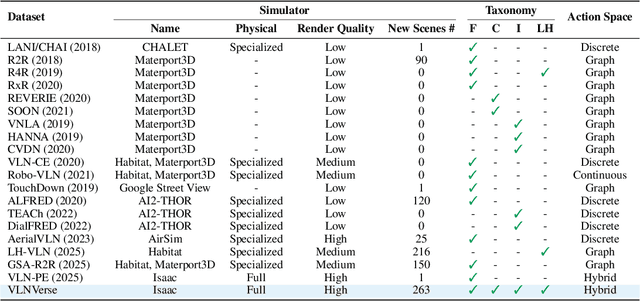
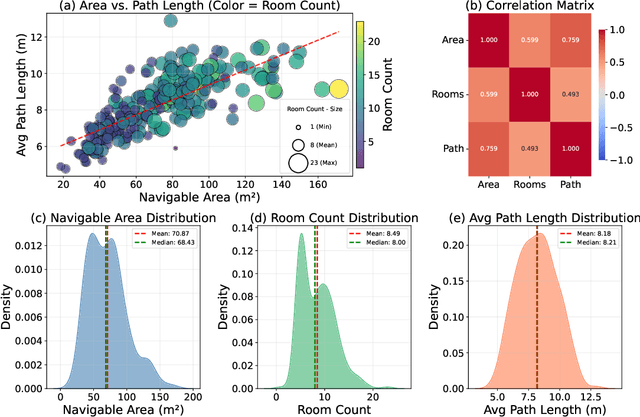

Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
A Class of Dual-Frame Passively-Tilting Fully-Actuated Hexacopter
Nov 19, 2025



This paper proposed a novel fully-actuated hexacopter. It features a dual-frame passive tilting structure and achieves independent control of translational motion and attitude with minimal actuators. Compared to previous fully-actuated UAVs, it liminates internal force cancellation, resulting in higher flight efficiency and endurance under equivalent payload conditions. Based on the dynamic model of fully-actuated hexacopter, a full-actuation controller is designed to achieve efficient and stable control. Finally, simulation is conducted, validating the superior fully-actuated motion capability of fully-actuated hexacopter and the effectiveness of the proposed control strategy.