 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AVSR Meets Video Conferencing: Dataset, Degradation, and the Hidden Mechanism Behind Performance Collapse
Mar 24, 2026Audio-Visual Speech Recognition (AVSR) has achieved remarkable progress in offline conditions, yet its robustness in real-world video conferencing (VC) remains largely unexplored. This paper presents the first systematic evaluation of state-of-the-art AVSR models across mainstream VC platforms, revealing severe performance degradation caused by transmission distortions and spontaneous human hyper-expression. To address this gap, we construct \textbf{MLD-VC}, the first multimodal dataset tailored for VC, comprising 31 speakers, 22.79 hours of audio-visual data, and explicit use of the Lombard effect to enhance human hyper-expression. Through comprehensive analysis, we find that speech enhancement algorithms are the primary source of distribution shift, which alters the first and second formants of audio. Interestingly, we find that the distribution shift induced by the Lombard effect closely resembles that introduced by speech enhancement, which explains why models trained on Lombard data exhibit greater robustness in VC. Fine-tuning AVSR models on MLD-VC mitigates this issue, achieving an average 17.5% reduction in CER across several VC platforms. Our findings and dataset provide a foundation for developing more robust and generalizable AVSR systems in real-world video conferencing. MLD-VC is available at https://huggingface.co/datasets/nccm2p2/MLD-VC.
Robust Provably Secure Image Steganography via Latent Iterative Optimization
Mar 10, 2026We propose a robust and provably secure image steganography framework based on latent-space iterative optimization. Within this framework, the receiver treats the transmitted image as a fixed reference and iteratively refines a latent variable to minimize the reconstruction error, thereby improving message extraction accuracy. Unlike prior methods, our approach preserves the provable security of the embedding while markedly enhancing robustness under various compression and image processing scenarios. On benchmark datasets, the experimental results demonstrate that the proposed iterative optimization not only improves robustness against image compression while preserving provable security, but can also be applied as an independent module to further reinforce robustness in other provably secure steganographic schemes. This highlights the practicality and promise of latent-space optimization for building reliable, robust, and secure steganographic systems.
Unifying Speech Editing Detection and Content Localization via Prior-Enhanced Audio LLMs
Jan 29, 2026Speech editing achieves semantic inversion by performing fine-grained segment-level manipulation on original utterances, while preserving global perceptual naturalness. Existing detection studies mainly focus on manually edited speech with explicit splicing artifacts, and therefore struggle to cope with emerging end-to-end neural speech editing techniques that generate seamless acoustic transitions. To address this challenge, we first construct a large-scale bilingual dataset, AiEdit, which leverages large language models to drive precise semantic tampering logic and employs multiple advanced neural speech editing methods for data synthesis, thereby filling the gap of high-quality speech editing datasets. Building upon this foundation, we propose PELM (Prior-Enhanced Audio Large Language Model), the first large-model framework that unifies speech editing detection and content localization by formulating them as an audio question answering task. To mitigate the inherent forgery bias and semantic-priority bias observed in existing audio large models, PELM incorporates word-level probability priors to provide explicit acoustic cues, and further designs a centroid-aggregation-based acoustic consistency perception loss to explicitly enforce the modeling of subtle local distribution anomalies. Extensive experimental results demonstrate that PELM significantly outperforms state-of-the-art methods on both the HumanEdit and AiEdit datasets, achieving equal error rates (EER) of 0.57\% and 9.28\% (localization), respectively.
Audio-visual Event Localization on Portrait Mode Short Videos
Apr 09, 2025Audio-visual event localization (AVEL) plays a critical role in multimodal scene understanding. While existing datasets for AVEL predominantly comprise landscape-oriented long videos with clean and simple audio context, short videos have become the primary format of online video content due to the the proliferation of smartphones. Short videos are characterized by portrait-oriented framing and layered audio compositions (e.g., overlapping sound effects, voiceovers, and music), which brings unique challenges unaddressed by conventional methods. To this end, we introduce AVE-PM, the first AVEL dataset specifically designed for portrait mode short videos, comprising 25,335 clips that span 86 fine-grained categories with frame-level annotations. Beyond dataset creation, our empirical analysis shows that state-of-the-art AVEL methods suffer an average 18.66% performance drop during cross-mode evaluation. Further analysis reveals two key challenges of different video formats: 1) spatial bias from portrait-oriented framing introduces distinct domain priors, and 2) noisy audio composition compromise the reliability of audio modality. To address these issues, we investigate optimal preprocessing recipes and the impact of background music for AVEL on portrait mode videos. Experiments show that these methods can still benefit from tailored preprocessing and specialized model design, thus achieving improved performance. This work provides both a foundational benchmark and actionable insights for advancing AVEL research in the era of mobile-centric video content. Dataset and code will be released.
SE4Lip: Speech-Lip Encoder for Talking Head Synthesis to Solve Phoneme-Viseme Alignment Ambiguity
Apr 08, 2025Speech-driven talking head synthesis tasks commonly use general acoustic features (such as HuBERT and DeepSpeech) as guided speech features. However, we discovered that these features suffer from phoneme-viseme alignment ambiguity, which refers to the uncertainty and imprecision in matching phonemes (speech) with visemes (lip). To address this issue, we propose the Speech Encoder for Lip (SE4Lip) to encode lip features from speech directly, aligning speech and lip features in the joint embedding space by a cross-modal alignment framework. The STFT spectrogram with the GRU-based model is designed in SE4Lip to preserve the fine-grained speech features. Experimental results show that SE4Lip achieves state-of-the-art performance in both NeRF and 3DGS rendering models. Its lip sync accuracy improves by 13.7% and 14.2% compared to the best baseline and produces results close to the ground truth videos.
Improving Speech Enhancement by Cross- and Sub-band Processing with State Space Model
Feb 22, 2025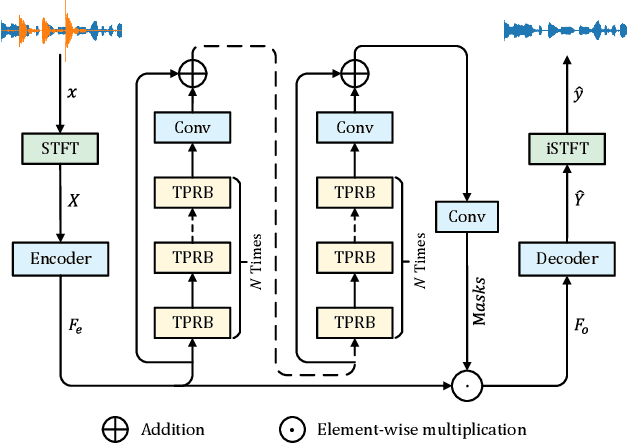
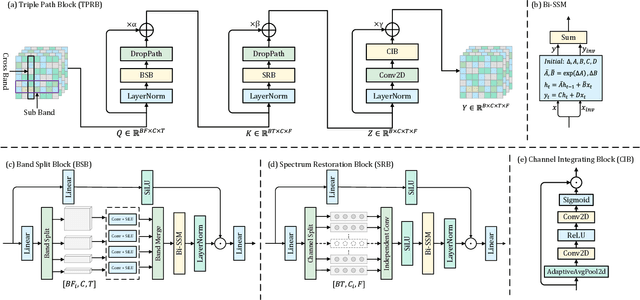

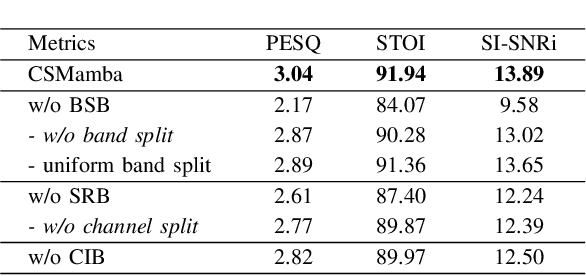
Recently, the state space model (SSM) represented by Mamba has shown remarkable performance in long-term sequence modeling tasks, including speech enhancement. However, due to substantial differences in sub-band features, applying the same SSM to all sub-bands limits its inference capability. Additionally, when processing each time frame of the time-frequency representation, the SSM may forget certain high-frequency information of low energy, making the restoration of structure in the high-frequency bands challenging. For this reason, we propose Cross- and Sub-band Mamba (CSMamba). To assist the SSM in handling different sub-band features flexibly, we propose a band split block that splits the full-band into four sub-bands with different widths based on their information similarity. We then allocate independent weights to each sub-band, thereby reducing the inference burden on the SSM. Furthermore, to mitigate the forgetting of low-energy information in the high-frequency bands by the SSM, we introduce a spectrum restoration block that enhances the representation of the cross-band features from multiple perspectives. Experimental results on the DNS Challenge 2021 dataset demonstrate that CSMamba outperforms several state-of-the-art (SOTA) speech enhancement methods in three objective evaluation metrics with fewer parameters.
FA-GAN: Artifacts-free and Phase-aware High-fidelity GAN-based Vocoder
Jul 05, 2024Generative adversarial network (GAN) based vocoders have achieved significant attention in speech synthesis with high quality and fast inference speed. However, there still exist many noticeable spectral artifacts, resulting in the quality decline of synthesized speech. In this work, we adopt a novel GAN-based vocoder designed for few artifacts and high fidelity, called FA-GAN. To suppress the aliasing artifacts caused by non-ideal upsampling layers in high-frequency components, we introduce the anti-aliased twin deconvolution module in the generator. To alleviate blurring artifacts and enrich the reconstruction of spectral details, we propose a novel fine-grained multi-resolution real and imaginary loss to assist in the modeling of phase information. Experimental results reveal that FA-GAN outperforms the compared approaches in promoting audio quality and alleviating spectral artifacts, and exhibits superior performance when applied to unseen speaker scenarios.
Semantic Proximity Alignment: Towards Human Perception-consistent Audio Tagging by Aligning with Label Text Description
Sep 28, 2023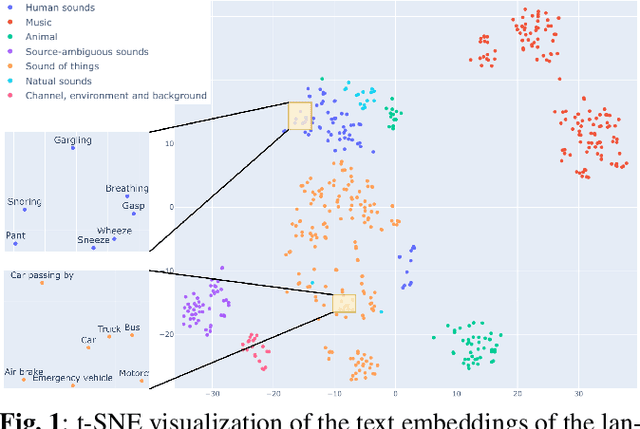
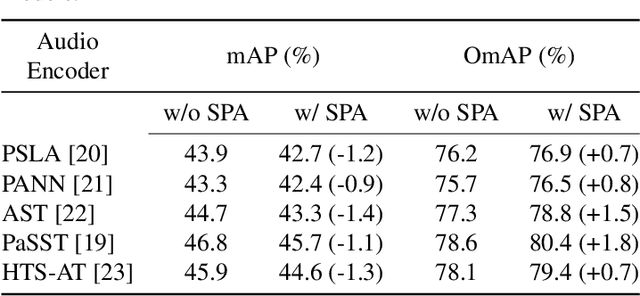
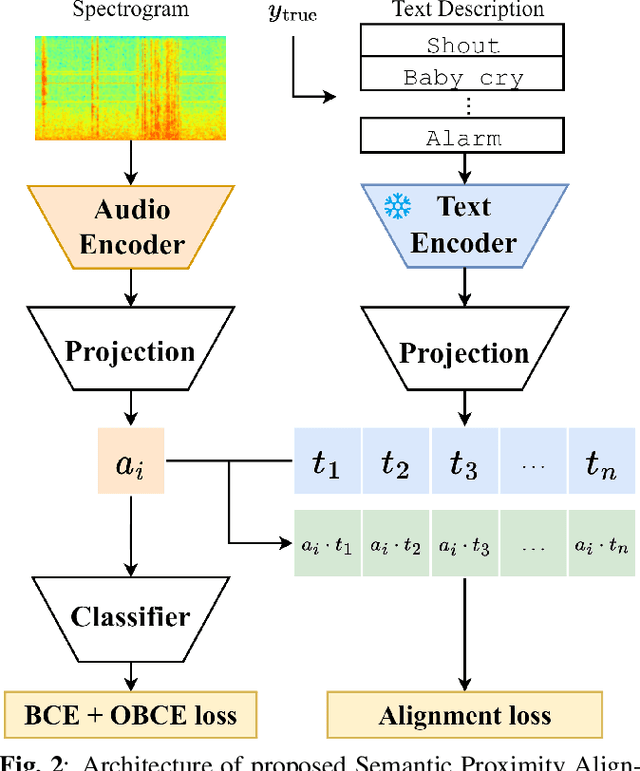
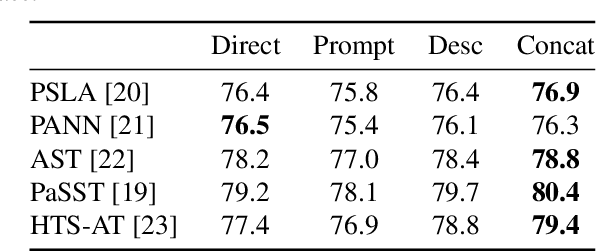
Most audio tagging models are trained with one-hot labels as supervised information. However, one-hot labels treat all sound events equally, ignoring the semantic hierarchy and proximity relationships between sound events. In contrast, the event descriptions contains richer information, describing the distance between different sound events with semantic proximity. In this paper, we explore the impact of training audio tagging models with auxiliary text descriptions of sound events. By aligning the audio features with the text features of corresponding labels, we inject the hierarchy and proximity information of sound events into audio encoders, improving the performance while making the prediction more consistent with human perception. We refer to this approach as Semantic Proximity Alignment (SPA). We use Ontology-aware mean Average Precision (OmAP) as the main evaluation metric for the models. OmAP reweights the false positives based on Audioset ontology distance and is more consistent with human perception compared to mAP. Experimental results show that the audio tagging models trained with SPA achieve higher OmAP compared to models trained with one-hot labels solely (+1.8 OmAP). Human evaluations also demonstrate that the predictions of SPA models are more consistent with human perception.
A Snoring Sound Dataset for Body Position Recognition: Collection, Annotation, and Analysis
Jul 25, 2023



Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a chronic breathing disorder caused by a blockage in the upper airways. Snoring is a prominent symptom of OSAHS, and previous studies have attempted to identify the obstruction site of the upper airways by snoring sounds. Despite some progress, the classification of the obstruction site remains challenging in real-world clinical settings due to the influence of sleep body position on upper airways. To address this challenge, this paper proposes a snore-based sleep body position recognition dataset (SSBPR) consisting of 7570 snoring recordings, which comprises six distinct labels for sleep body position: supine, supine but left lateral head, supine but right lateral head, left-side lying, right-side lying and prone. Experimental results show that snoring sounds exhibit certain acoustic features that enable their effective utilization for identifying body posture during sleep in real-world scenarios.
Who is Speaking Actually? Robust and Versatile Speaker Traceability for Voice Conversion
May 09, 2023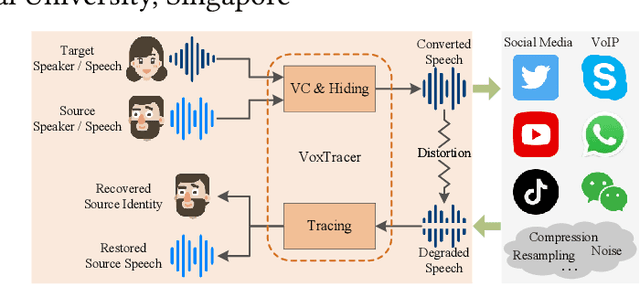
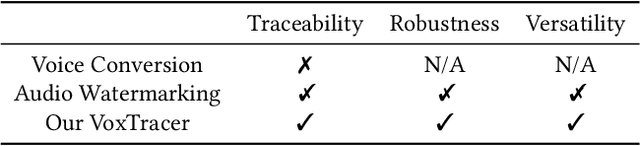
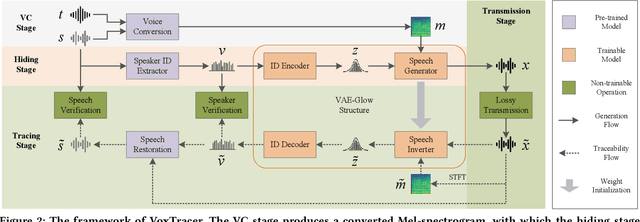
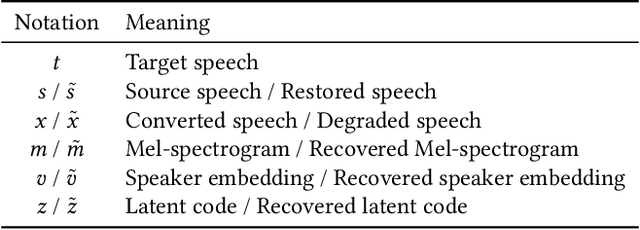
Voice conversion (VC), as a voice style transfer technology, is becoming increasingly prevalent while raising serious concerns about its illegal use. Proactively tracing the origins of VC-generated speeches, i.e., speaker traceability, can prevent the misuse of VC, but unfortunately has not been extensively studied. In this paper, we are the first to investigate the speaker traceability for VC and propose a traceable VC framework named VoxTracer. Our VoxTracer is similar to but beyond the paradigm of audio watermarking. We first use unique speaker embedding to represent speaker identity. Then we design a VAE-Glow structure, in which the hiding process imperceptibly integrates the source speaker identity into the VC, and the tracing process accurately recovers the source speaker identity and even the source speech in spite of severe speech quality degradation. To address the speech mismatch between the hiding and tracing processes affected by different distortions, we also adopt an asynchronous training strategy to optimize the VAE-Glow models. The VoxTracer is versatile enough to be applied to arbitrary VC methods and popular audio coding standards. Extensive experiments demonstrate that the VoxTracer achieves not only high imperceptibility in hiding, but also nearly 100% tracing accuracy against various types of audio lossy compressions (AAC, MP3, Opus and SILK) with a broad range of bitrates (16 kbps - 128 kbps) even in a very short time duration (0.74s). Our speech demo is available at https://anonymous.4open.science/w/DEMOofVoxTracer.